財務應該及早進入產品開發流程,貫穿到企業愿景,使命,產品規劃,產品開發及產品生命周期管理全過程
IPD成本控制主要針對兩個目標:
1、 降低開發成本
2、 降低產品本身的結構成本
研發人員常犯的成本錯誤:
1、 只關注物料成本,不關注設計成本和維護成本,出現物料成本雖然降低,但是帶來的設計難度、設計成本增加
2、 不采購外來成熟組件,自行開發,導致產品不穩定帶來的維護成本增加
3、 對公司內部成本高的優選器件不采用,忽略量產后帶來的采購成本下降
控制綜合成本的手段:
1、 通過需求與規劃,區分基本需求、競爭需求、可有可無的需求,避免過度開發
2、 通過產品化共享,減少低水平重復開發
3、 通過技術分類,識別核心技術、關鍵技術、通用技術和一般技術,核心技術和關鍵技術自主開發,通用技術和一般技術外包,以降低開發成本
4、 在設計中控制成本:確定目標成本,設計中采用多方案選擇,減少新模塊,控制質量成本,加強可靠性設計,由高手負責設計
5、 在開發與制造中進行成本過程控制:保證資源
產品經理必須掌握的財務成本知識:
1、 了解財務基本專業知識,定期看部門財務報表,分析部門的內部核算表
2、 理解核算原則,學會用比例定崗
3、 了解公司和部門的固定成本變動,學會控制成本
4、 知識計算部門內部的盈虧平衡點
5、 知道怎么做預算,并親自做預算和審核下級預算及費用
6、 關注項目回款,明白影響現金流的原因
7、 熟悉公司財務制度,并提出改進措施,使其簡潔有效
posted @
2012-12-14 10:57 胡滿超 閱讀(443) |
評論 (0) |
編輯 收藏新產品開發的前三單客戶也是產品開發的一部分,必須由公司高級別的人員完成,而不是一味地交給客戶經理去銷售
產品命名及商標管理:
1、 產品命令應將技術語言轉換為了市場語言
2、 命名突出賣點
3、 命名保持統一品牌形象
4、 命名不要使用方言,俚語
產品宴會的FFAB策略:
Feature:技術賣點
Function:功能賣點
Advantage:產品的優點
Benefits:對客戶的好處
1、 如果客戶熟悉技術,突出介紹Function、Feature;不熟悉技術,突出介紹Advantage、Benefits
2、 客戶經理(銷售)應該掌握,Benefits、Advantage、Function
3、 市場經理應該掌握,Benefits、Advantage、Function、Feature
4、 技術經理應熟悉技術實現路徑
5、 嚴格區別Advantage、Benefits
產品定價:
1、 要利潤,定高價
2、 要規模,定低價
3、 阻攔對手,定更低價
4、 把價格隱藏在服務中
產品定價步驟:
1、 明確競爭對手產品
2、 分析競爭對手產品定價
3、 進行比較定價分析$APPEALS
4、 對產品進行成本分析,根據配置不同進行成本分析
5、 根據戰略價值及KPI定價
6、 細化并驗證定價策略
按價格承受力把客戶分類:
1、 戰略客戶:樣板用戶,帶動其他客戶消費
2、 利潤客戶:接受的價格給公司帶來的利潤大于機會利潤
3、 非利潤客戶:接受的價格給公司帶來的利潤小于機會利潤
4、 大客戶:訂單較多
5、 價值客戶:戰略+利潤+大客戶
定價避免以下情況:
1、 避免大客戶是非利潤客戶
2、 避免非利潤的戰略客戶太多
3、 避免將戰略客戶等同于價值客戶
客戶滿意度聚焦利潤客戶,價值客戶的滿意度必須達到100%,非戰略非利潤客戶的滿意度不要超過50%
新產品推廣:
一個資料庫六個子庫:案例庫,問題庫,產品資料庫,市場資料庫,需求庫,競爭對手資料庫
銷售工具包:內部銷售工具包,給客戶資料包
五種手段:公司展廳,展覽會,樣板點,研討交流會,廣告/網站/軟性文章
公司高層,產品經理,市場經理,客戶經理都要進行客戶關系的維護和開拓
產品經理和系統級工程師更要對技術型的客戶進行維護和開拓
產品銷售工具:產品一紙禪、售前膠片、案例分析、銷售指導書
通過規范的資料培訓銷售人員,營造產品大量進入市場的條件
posted @
2012-12-11 09:10 胡滿超 閱讀(414) |
評論 (0) |
編輯 收藏常見的質量管理問題原因:
1、 QA沒有在設計時介入
2、 QA工作不獨立,影響測試結果
3、 做評審沒有評審要素,評審人沒有績效考核,走過場
4、 新手做設計,高手救火
5、 未建立公共模塊共享開發的研發模式
6、 引入不成熟的技術
7、 在設計時,未進行多方案預備
構建質量體系六個要素:
1、 一套流程:將質量管理體系融入研發流程
2、 兩個原則:業務決策評審與技術質量評審分離、建立產品貨架
3、 三個職位:系統級工程師,主審人,PQA
4、 四個分離:規劃與系統設計分離,設計與實現分離,實現與測試分離,測試與驗證分離
5、 五種手段:規劃與CBB共享、評審、測試和驗證、任職資格與活動匹配、缺陷歸零管理
6、 六個評審點
技術評審:關注技術評估
決策評審:關注財務、資源投入、計劃
posted @
2012-12-06 16:19 胡滿超 閱讀(353) |
評論 (0) |
編輯 收藏技術分類:核心技術,關鍵技術,一般技術,通用技術
核心技術:需要進行發展規劃,進行立體開發,知識產權保護
技術外包進行嚴格評審,避免核心技術,關鍵技術外包
核心技術,關鍵技術:縱向發展人員
一般技術,通用技術:橫向發展人員,可以外包
核心技術特點:獨有性,競爭性,可攔截性,不可替代性,可管理可保護,產生價值
技術并不是越多越好,而是核心技術和關鍵技術越多越好
技術開發五個階段:立項,開發,驗證,發布,成果貨架化管理
對技術管理考核:結果要寬松,過程要嚴格
共用基礎模塊CBB:在不同產品、系統之間共用的零部件,模塊,技術,設計成果
貨架:將不同層次的產品統一管理
貨架產品:成熟度達到一定程度的CBB
平臺:一系列貨架產品在層級上的集合
平臺形成的兩條路:
1、 根據需求形成平臺規劃:平臺很難規劃
2、 總結與沉淀:做3個定制項目進行一次CBB分析
技術預研和平臺開發人員級別要高,需要高手開發
預研團隊和技術開發,產品開發團隊應該合理流動,以實現技術成果的產品化
鼓勵和激勵平臺開發措施:
1、 通過任職資格牽引
2、 平臺進行內部定價
3、 可以對非競爭的客戶進行外部銷售
4、 對平臺開發給予戰略補貼和特別激勵
posted @
2012-12-04 09:38 胡滿超 閱讀(495) |
評論 (0) |
編輯 收藏項目分級:
A級項目:公司級重點關注和管理項目
B級項目:產品線重點關注和管理的項目
C級項目:產品經理或項目經理自己管理的項目
項目排序要素:市場吸引力、競爭地位、財務評估
單項目主體:項目經理
多項目主體:項目管理部
項目開發四個階段:階段,步驟,任務,活動
三個計劃:
1、 一級計劃:解決全流程、全要素協同
2、 二級計劃:全流程協同下的各部門協同
3、 三級計劃:指導更小模塊或個人具體執行任務計劃
提高計劃準備度和完成率三要素:需求管理,關鍵資源及時到位,項目經理的能力
計劃制訂需要分階段,分級進行,避免追求一次成型
posted @
2012-11-26 10:44 胡滿超 閱讀(409) |
評論 (0) |
編輯 收藏研發工作四類流程:
1、 技術開發流程:預研、應用技術開發V版本
2、 平臺開發流程:共享模塊開發V版本
3、 產品開發流程:每向細分市場R版本
4、 定制項目開發流程:在產品和平臺基礎上針對某一客戶的定制M版本
產品開發活動四個步驟:階段,步驟,任務,活動
概念階段:驗證市場需求,確立產品是否可以立項
計劃階段:確立總體方案,資源投入,確保工藝、結構方案、設計方案同步,避免重復開發
發布階段:尋找樣板客戶,準備商標、命令、市場指導書、產品實驗局、初步定價策略;銷售工具包、售前膠片、銷售指導書、產品的配置、商業械設計、產品的成功安全分析,銷售培訓,發布計劃
產品開發流程六個階段:概念、計劃、產品開發、驗證、生命周期管理
四個決策評審點:概念決策、計劃決策、發布決策、生命周期決策
六個技術評審點:產品包需求評審、系統規格評審、概要設計評審、詳細設計評審、樣機評審、小批量評審
財務角色:
概念階段:產品的定價分析和成本分析
計劃階段:核算綜合成本
開發階段:監控成本
發布階段:明確價格策略
生命周期階段:進行價格的核準和調整價格
生產、維護、服務人員:在方案設計階段參與進來,提出可維護、可安裝、可測試、可生產需求,使方案設計一步到位。
采購角色:
概念階段:參與供應商認證
計劃階段:完成元器件認證,明確提前采購的風險
產品生命周期階段:關注器件的產能情況,提前預警
企業執行產品開發流程失敗原因分析:
1、 為流程而流程,只有研發參與
2、 沒有建立市場管理流程,沒有好的市場經理,產品開發沒有良好的輸入,推行產品開發流程困難
3、 沒有培養起來系統級工程師或團隊進行總體方案設計,沒有打通設計時的所有環節,流程流于形式
4、 評審過于關注技術,在市場和財務成功方面考慮較少
5、 過多關注流程執行的完整性,沒有結合自身情況,分步推進
6、 配套支撐流程和體系建設跟不上,如項目管理流程、績效管理流程、任職資格體系建設,落地的支撐人員配套跟不上
7、 沒有固化或形成時,過早進行IT化,僵化了流程
posted @
2012-11-19 15:32 胡滿超 閱讀(318) |
評論 (0) |
編輯 收藏研發與銷售矛盾重重:需要建立市場體系,銷售與市場分離
市場體系:分析客戶需求,進行產品規劃,培訓渠道及客戶經理,立足核心產品設計
市場體系:讓產品好賣,營
銷售體系:將產品賣好,銷
需求管理四個步驟:需求收集,需求分析與分類,需求分發,需求實現及驗證
需求管理體系目的:讓每個人在日常活動中,將需求進行收集并通過分析和分發,以確保非金屬人員面向市場進行開發
需求管理體系原則:落后了,找對手;平行了,建市場;領先了,做標準。
要建立好的市場體系,必須建立鼓勵研發人員進入營銷體系的機制。
為了保證快速地反映市場,規劃必須每三個月更新一次。
需求分類:
A類:新產品開發需求
B類:產品設計規格更改需求
C類:詳細設計路徑更改需求
D類:生產訂單需求
E類:CBB和平臺開發需求
F類:技術開發需求
G類:市場調研,需要繼續求證
進入一個客戶群三要素:
1、 市場吸引力:市場規模,市場成長性,戰略價值
2、 競爭地位:是否有能力進入,市場份額、產品優勢、成本優勢、渠道能力
3、 財務回報:收入增長率,現金流貢獻、研發投入產出比
確定新產品的需求的方法:
1、 重新進行新產品開發
2、 對老產品進行改進
外部需求:客戶的要求、功能需求、規格需求、可靠性需求
內部需求:產品化需求(可生產、可安裝、可維護、可測試、可驗證),技術需求
需求完成包括四類人員:客戶經理、市場經理、產品經理、技術經理
需求產出的四份文檔:
1、 客戶需求規格說明書
2、 產品包需求說明書
3、 需求的分解分配
4、 技術規格說明書
將產品規格轉變為技術需求:FFAB
Benefits:對客戶的好處
Advantage:產品的優點
Function:功能模塊的賣點
Feature:實現功能模塊的技術特性
業界常用的$APPEALS模型:$價格、A可獲得性、P包裝、P功能性能、E易用、A保證、L生命周期成本、S社會接受程度

posted @
2012-11-16 13:37 胡滿超 閱讀(370) |
評論 (0) |
編輯 收藏企業戰略規劃制定:一個從公司愿景,到經營計劃,到各產品線的愿景,及業務計劃,再到產品平臺以及核心技術需求,并落實到資源規劃以及各種激勵機制的配套保證的總體流程
戰略規劃分三個層次:
1、 頂層設計,戰略研究層
2、 業務層,產品線戰略規劃層
3、 支撐層,資源配置管理改進層
產品戰略的W型八個步驟
技術型企業組織績效指標:
1、 生存類能力指標:財務指標,交付指標,
2、 可持續發展能力指標:新業務占收入的比重,核心技術和平臺帶來的收入占比
3、 核心競爭能力指標:公共模塊共享率,人員結構合理性及任職資料提升率,引導客戶需求與規劃能力
產品線的核心考核指標是組織績效:對市場成功和財務成功負責
個人績效:只能產品線有利潤,組織績效成功,才有意義
企業增加利潤的路徑:
1、 進入新市場
2、 開發新業務
3、 改變商業模式
4、 降低成本:研發的首要目的是提高老產品的利潤,其次是開發新產品,新技術
5、 提高價格
企業新業務分類:
1、 聚焦發展,70%
2、 必須突破的業務,20%
3、 布局式業務,10%
筆記原書:
http://www.amazon.cn/%E4%BA%A7%E5%93%81%E7%A0%94%E5%8F%91%E7%AE%A1%E7%90%86-%E6%9E%84%E5%BB%BA%E4%B8%96%E7%95%8C%E4%B8%80%E6%B5%81%E7%9A%84%E4%BA%A7%E5%93%81%E7%A0%94%E5%8F%91%E7%AE%A1%E7%90%86%E4%BD%93%E7%B3%BB-%E5%91%A8%E8%BE%89/dp/B006THMWQS/ref=pd_sim_b_3

posted @
2012-11-13 09:54 胡滿超 閱讀(357) |
評論 (0) |
編輯 收藏IPD介紹
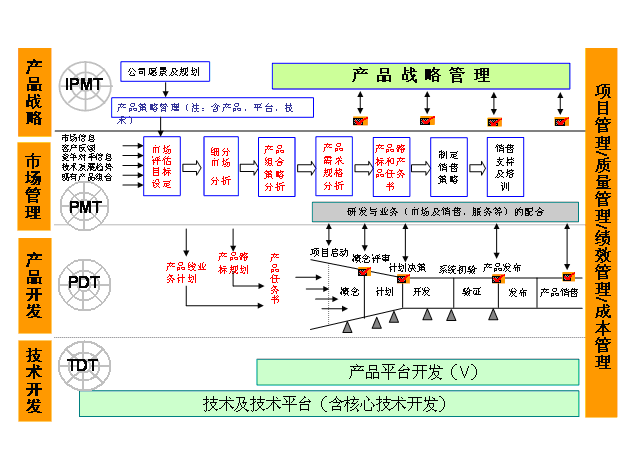
研發的六種產出模式:
1、 基礎研究,發明和標準
2、 應用開發,將非成熟的應用技術變成成熟的技術
3、 項目開發,一次性的定制
4、 產品開發,內部共享模塊與產品,外部銷售的產品,可批量,可重復,可復制生產
5、 解決方案,以產品為核心,為客戶做的跨產品或跨領域集成方案
6、 服務和運營,服務、運營、維護獲取收益
產品開發貨架層次:器件、組件、部件、單機、整機、子系統、系統
產品分類:
1、 內部共享產品:器件、組件、部件
2、 面向細分客戶群的產品:部件、單機、整機、子系統(能力強的公司)
3、 解決方案級產品:子系統、系統
技術型企業的商業模式:經營技術、經營產品、經營解決方案、經營客戶和服務
技術型企業的商業模式發展和演變五個階段:
1、 勞動密集型加工
2、 項目生存型
3、 產品擴展型
4、 運營客戶型
5、 集成產業鏈型
產品開發方式:
1、 先開發技術,然后做通用產品,再銷售
技術開發->產品開發->形成產品->銷售渠道->通用客戶需求
缺點:容易被細分市場產品替代,技術一旦落后沒有后續產出
2、 客戶需求,尋找技術,完成定制
客戶需求->營銷渠道->確定交付->投入開發->技術突破
缺點:技術開發有風險;一個個項目做,企業很難做大;質量不易保證;人員沒有專業發展通道,容易流失;項目越多,管理越難
集成產品開發:
1、 產品開發與技術開發、平臺開發分離;
2、 技術和平臺開發先行,解決技術突破;
3、 產品開發按細分客戶群需求
集成產品開發和技術開發特點:
1、 產品開發:強調基于市場需求和共享平臺,對市場和財務的成功負責
2、 技術開發:自己掌握業界成熟的技術,做成貨架,供產品開發時共享,以縮短產品開發周期
集成產品開發三種產品形態:
1、 產品大版本V:平臺版本
2、 細分客戶群版本R:交付給用客戶產品,四要素:客戶及競爭需求、功能與技術需求、時間、成本
3、 客戶定制版本M:在R版本的基礎上針對具體客戶的個性化版本
產品開發四個范疇:技術開發、市場開發、生產和服務開發、資料包開發
產品開發的步驟:
1、 先進行市場開發,細分客戶群,尋找賣點和商業模式,尋找市場和財務成功的要素;
2、 根據產品需求進行分解與分配,進行技術開發
3、 根據技術要求進行產品的可生產性,可安裝性,可測試性,可驗證性,可服務性開發
4、 根據產品大量進入市場,進行技術資料包,服務資料包和銷售工具的開發
企業研發管理發展的五個階段:
1、 單項目單產品階段:以項目為核心
2、 多產品、共享產品和貨架平臺階段:以產品為核心
3、 以共享為核心面向客戶需求階段:以客戶為核心
4、 以產業鏈為核心的關注利潤階段:以利潤為核心
5、 持續改進階段
集成產品開發管理思想:
1、 產品開發是一項投資
2、 必須強調基于市場的創新
3、 執行技術開發與產品開發分離
4、 對技術進行分類管理,強調核心技術,關鍵技術的自主開發
5、 跨部分的協同開發,實現全流程全要素(市場、研發、生產、采購、財務協同)的管理
6、 強調CBB和平臺建設,強調技術共享
7、 執行異步開發
8、 根據產品的不同層次和技術開發執行不同的結構化開發流程
9、 強調市場和財務成功、核心競爭力的提升是研發績效考核的重要因素
要實現IPD要以產品線(產品)為核心進行四大重組:財務重組、市場重組、產品重組、組織與流程重組
筆記原書:
http://www.amazon.cn/%E4%BA%A7%E5%93%81%E7%A0%94%E5%8F%91%E7%AE%A1%E7%90%86-%E6%9E%84%E5%BB%BA%E4%B8%96%E7%95%8C%E4%B8%80%E6%B5%81%E7%9A%84%E4%BA%A7%E5%93%81%E7%A0%94%E5%8F%91%E7%AE%A1%E7%90%86%E4%BD%93%E7%B3%BB-%E5%91%A8%E8%BE%89/dp/B006THMWQS/ref=pd_sim_b_3
posted @
2012-11-11 21:42 胡滿超 閱讀(748) |
評論 (0) |
編輯 收藏IPD集成產品開發管理思想強調:
1、 產品開發是一項投資
2、 必須強調基于市場的創新
3、 執行技術開發與產品開發分離
4、 對技術進行分類管理,強調核心技術,關鍵技術的自主開發
5、 跨部分的協同開發,實現全流程全要素(市場、研發、生產、采購、財務協同)的管理
6、 強調CBB和平臺建設,強調技術共享
7、 執行異步開發
8、 根據產品的不同層次和技術開發執行不同的結構化開發流程
9、 強調市場和財務成功、核心競爭力的提升是研發績效考核的重要因素
除了IPD的流程之外,華為人結合了華為實踐IPD過程的經驗與教訓,及一些成功的管理實踐,做了完整的總結與升華,閱讀之后感覺茅塞頓開。
介紹兩本書:
http://www.amazon.cn/gp/product/B001ULBY6W 與
與http://www.amazon.cn/%E4%BA%A7%E5%93%81%E7%A0%94%E5%8F%91%E7%AE%A1%E7%90%86-%E6%9E%84%E5%BB%BA%E4%B8%96%E7%95%8C%E4%B8%80%E6%B5%81%E7%9A%84%E4%BA%A7%E5%93%81%E7%A0%94%E5%8F%91%E7%AE%A1%E7%90%86%E4%BD%93%E7%B3%BB-%E5%91%A8%E8%BE%89/dp/B006THMWQS/ref=pd_sim_b_3
我將陸續把自己寫的一些筆記與大家分享。
posted @
2012-11-10 14:20 胡滿超 閱讀(1867) |
評論 (1) |
編輯 收藏總結網上訂票系統常見的問題如下:
1、 高峰時段無法登陸,提示在線用戶過多
2、 訂單提交成功之后,支付環節出了問題,瀏覽器意外退出,后再登陸,發現登陸不上,無法在規定時間內完成支付,購票失敗
3、 訂單提交反饋時間過長,熱門線路需要等待20分鐘甚至更長時間,才能得到反饋
4、 驗證碼輸入總是錯誤,無法完成驗證碼驗證環節,無法登陸
5、 逢用戶高峰,網站反應速度較慢
6、 對多瀏覽器支持不好,沒有IOS,Android應用入口
以上問題多數都是用戶體驗的問題,用戶體驗的問題即有票源稀少的原因,更多的是對訂票系統使用過程中系統登陸困難,反應遲鈍,訂單結果反饋太慢,意外退出等問題難以忍受。
本人并非訂票系統設計人員,但是通用對訂票系統外在的表現大膽猜測一下訂票系統的設計。
常見問題原因分析:
問題1,高峰時段無法登陸,提示在線用戶過多;
問題4,驗證碼輸入總是錯誤,無法完成驗證碼驗證環節,無法登陸
無法登陸的問題,其原因顯然是前端用于處理WEB連接服務器太少或網絡帶寬不足所至,為了不讓更多的用戶一起連接服務器導致服務器較慢,只好拒絕一些用戶的登陸請求。使同時在線人數保持在一個上限以內。
驗證碼輸入總是錯誤的問題,原因也是用于處理WEB連接服務器太少所至,為了防止一些客戶端使用“惡意”軟件,不斷自動登陸的情況,驗證碼需求由客戶端向服務器提交一個驗證請求,可以由于服務器響應實在太慢,以至于整個響應速度居然超過了驗證碼的有效時間。
常見問題:
問題2:訂單提交成功之后,支付環節出了問題,瀏覽器意外退出,后再登陸,發現登陸不上,無法在規定時間內完成支付,購票失敗
問題3:訂單提交反饋時間過長,熱門線路需要等待20分鐘甚至更長時間,才能得到反饋
問題5:逢用戶高峰,網站反應速度較慢
問題2是一個系統的BUG,但是可以通過一些設計來解決這個問題。
問題3,問題5,可能是由于WEB服務器與邏輯處理服務器在同一臺機器上,而導致服務器CPU分配了過多的時間與資源在處理用戶請求,在執行邏輯時執行緩慢。
如果數據庫也在同一臺服務器上,那問題可能更加嚴重。當然我相信,不在一臺服務器上的可能性比較大。
總結以上問題,其解決方案建議如下:
1、 準備更多前端WEB服務器,解決WEB前端的問題沒有別的辦法,只能加服務器,或者每個省市放一群單獨的服務器,根據用戶量進行增加,直到響應流暢為止。
2、 可以考慮把邏輯服務器單獨分離出來,與WEB服務器分開,WEB服務器只處理WEB請求,邏輯服務器單獨運行
3、 把數據庫服務器單獨分離,并且把火車票票量數據庫與用戶訂票信息數據庫放到不同的機器上,由于大量的訂票請求會訪問火車票票量數據庫,并且會有大量訂票數據添加到用戶訂票信息數據庫中,在處理添加的邏輯占用了大量的數據庫資源,會導致整個系統變慢。如果放到同一臺機器上,必然導致響應變慢。把不同性質的數據,放到不同機器、不同的數據系統中,可以合理的分流系統訪問量,使系統響應加快,橫向擴展更具有彈性。
4、 把支付訂票費用放到一個單獨的網站進行,訂單提交成功后鎖票,之后根據訂單號可以在另外一個單獨的網站上進行單獨支付,支付時只要提供訂票號就可以,這樣做有很多好處:1. 避免了由于支付失敗而導致退出瀏覽器,卻由于在線人數過多無法登陸導致訂票失敗的情況,2. 電話訂票也可以在此支付,在火車站機自動售票機器上取票,這樣支付方便,也解決了異地付款取票的問題 3. 單獨支付會在一定程度上給訂票網站減輕訪問與處理壓力
5、 提供快遞火車票服務進行創收,支付成功的火車票可以進行快遞,這樣即方便訂票人也可以給鐵道部創收
6、 網站可以根據用戶訂票信息做一些有針對性網站廣告,如旅游、酒店廣告等進行創收
7、 開發出更多的手機終端軟件,擴大訂票系統使用的覆蓋面
8、 支持更多的瀏覽器,而不僅僅是IE
由于本人水平有限,歡迎各個高手批評指正,希望這篇文章能夠拋磚引玉,大家一起討論。
網上的其他類似文章:
http://cloud.it168.com/a2012/0130/1304/000001304533.shtml
posted @
2012-10-15 17:09 胡滿超 閱讀(2817) |
評論 (7) |
編輯 收藏轉自:http://book.douban.com/annotation/19461092/
半個月前在豆瓣上看到了一本新書《數學之美》,評價很高。而因為在半年前看了《什么是數學》就對數學產生濃厚興趣,但苦于水平不足的我便立馬買了一本,希望能對數學多一些了解,并認真閱讀起來。 令我意外并欣喜的是,這本書里邊的數學內容并不晦澀難懂,而且作者為了講述數學之美而搭配的一些工程實例都是和我學習并感興趣的模式識別,目標分類相關算法相關聯的。這讓我覺得撿到了意外的寶藏。 書中每一個章節都或多或少是作者親身經歷過的,比如世界級教授的小故事,或者Google的搜索引擎原理,又或者是Google的云計算等。作者用其行云流水般的語言將各個知識點像講故事一樣有趣的敘述出來。 這本書著實讓我印象深刻,所以我把筆記分享出來,希望更多和我學習研究領域一樣的人會喜歡并親自閱讀這本書,并能支持作者。畢竟國內這種書實在是太少了,也希望能有更多領域內的大牛能再寫出一些這種書籍來讓我們共同提高。1. 因為需要傳播信息量的增加,不同的聲音并不能完全表達信息,語言便產生了。2. 當文字增加到沒有人能完全記住所有文字時,聚類和歸類就開始了。例如日代表太陽或者代表一天。3. 聚類會帶來歧義性,但上下文可以消除歧義。信息冗余是信息安全的保障。例如羅塞塔石碑上同一信息重復三次。4. 最短編碼原理即常用信息短編碼,生僻信息長編碼。5. 因為文字只是信息的載體而非信息本身,所以翻譯是可以實現的。6. 2012,其實是瑪雅文明采用二十進制,即四百年是一個太陽紀,而2012年恰巧是當前太陽紀的最后一年,2013年是新的太陽紀的開始,故被誤傳為世界末日。7. 字母可以看為是一維編碼,而漢字可以看為二維編碼。8. 基于統計的自然語言處理方法,在數學模型上和通信是相通的,甚至是相同的。9. 讓計算機處理自然語言的基本問題就是為自然語言這種上下文相關的特性建立數學模型,即統計語言模型(Statistical Language Modal)。10. 根據大數定理(Law of Large Numbers),只要統計量足夠,相對頻度就等于概率。11. 二元模型。對于p(w1,w2,…,wn)=p(w1)p(w2|w1)p(w3|w1,w2)…p(wn|w1,w2,…,wn-1)的展開問題,因為p(w3|w1,w2)難計算,p(wn|w1,w2,…,wn-1)更難計算,馬爾科夫給出了一個偷懶但是頗為有效的方法,也就是每當遇到這種情況時,就假設任意wi出現的概率只與它前面的wi-1有關,即p(s)=p(w1)p(w2|w1)p(w3|w2)…p(wi|wi-1)…p(wn|wn-1)。現在這個概率就變的簡單了。對應的語言模型為2元模型(Bigram Model)。12. *N元模型。wi只與前一個wi-1有關近似的過頭了,所以N-1階馬爾科夫假設為p(wi|w1,w2,…,wi-1)=p(wi|wi-N+1,wi-N+2,…,wi-1),對應的語言模型成為N元模型(N-Gram Model)。一元模型就是上下文無關模型,實際應用中更多實用的是三元模型。Google的羅塞塔翻譯系統和語言搜索系統實用的是四元模型,存儲于500臺以上的Google服務器中。13. *卡茲退避法(Katz backoff),對于頻率超過一定閾值的詞,它們的概率估計就是它們在語料庫中的相對頻度,對于頻率小于這個閾值的詞,它們的概率估計就小于他們的相對頻度,出現次數越少,頻率下調越多。對于未看見的詞,也給予一個比較小的概率(即下調得到的頻率總和),這樣所有詞的概率估計都平滑了。這就是卡茲退避法(Katz backoff)。14. 訓練數據通常是越多越好,通過平滑過渡的方法可以解決零概率和很小概率的問題,畢竟在數據量多的時候概率模型的參數可以估計的比較準確。15. 利用統計語言模型進行分詞,即最好的分詞方法應該保證分完詞后這個句子出現的概率最大。根據不同應用,漢語分詞的顆粒度大小應該不同。16. 符合馬爾科夫假設(各個狀態st的概率分布只與它前一個狀態st-1有關)的隨即過程即成為馬爾科夫過程,也稱為馬爾科夫鏈。17. 隱含馬爾科夫模型是馬爾科夫鏈的擴展,任意時刻t的狀態st是不可見的,所以觀察者沒法通過觀察到一個狀態序列s1,s2,s3,…,sT來推測轉移概率等參數。但是隱馬爾科夫模型在每個時刻t會輸出一個符號ot,而且ot和st相關且僅和ot相關。這個被稱為獨立輸出假設。其中隱含的狀態s1,s2,s3,…是一個典型的馬爾科夫鏈。18. 隱含馬爾科夫模型是機器學習主要工具之一,和幾乎所有機器學習的模型工具一樣,它需要一個訓練算法(鮑姆-韋爾奇算法)和使用時的解碼算法(維特比算法)。掌握了這兩類算法,就基本上可以使用隱含馬爾科夫模型這個工具了。19. 鮑姆-韋爾奇算法(Baum-Welch Algorithm),首先找到一組能夠產生輸出序列O的模型參數,這個初始模型成為Mtheta0,需要在此基礎上找到一個更好的模型,假定不但可以算出這個模型產生O的概率P(O|Mtheta0),而且能夠找到這個模型產生O的所有可能的路徑以及這些路徑的概率。并算出一組新的模型參數theta1,從Mtheta0到Mtheta1的過程稱為一次迭代。接下來從Mtheta1出發尋找更好的模型Mtheta2,并一直找下去,直到模型的質量沒有明顯提高為止。這樣一直估計(Expectation)新的模型參數,使得輸出的概率達到最大化(Maximization)的過程被稱為期望值最大化(Expectation-Maximization)簡稱EM過程。EM過程能保證一定能收斂到一個局部最優點,但不能保證找到全局最優點。因此,在一些自然語言處理的應用中,這種無監督的鮑姆-韋爾奇算法訓練處的模型比有監督的訓練得到的模型效果略差。20. 熵,信息熵的定義為H(X)=-SumP(x)logP(x),變量的不確定性越大,熵也越大。21. 一個事物內部會存在隨機性,也就是不確定性,假定為U,而從外部消除這個不確定性唯一的辦法是引入信息I,而需要引入的信息量取決于這個不確定性的大小,即I>U才行。當I<U時,這些信息可以消除一部分不確定性,U'=U-I。反之,如果沒有信息,任何公示或者數字的游戲都無法排除不確定性。22. 信息的作用在于消除不確定性。23. 互信息,對兩個隨機事件相關性的量化度量,即隨機事件X的不確定性或者說熵H(X),在知道隨機事件Y條件下的不確定性,或者說條件熵H(X|Y)之間的差異,即I(X;Y)=H(X)-H(X|Y)。所謂兩個事件相關性的量化度量,即在了解了其中一個Y的前提下,對消除另一個X不確定性所提供的信息量。24. 相對熵(Kullback-Leibler Divergence)也叫交叉熵,對兩個完全相同的函數,他們的相對熵為零;相對熵越大,兩個函數差異越大,反之,相對熵越小,兩個函數差異越小;對于概率分布或者概率密度函數,如果取值均大于零,相對熵可以度量兩個隨機分布的差異性。25. 弗里德里克·賈里尼克(Frederek Jelinek)是自然語言處理真諦的先驅者。26. 技術分為術和道兩種,具體的做事方法是術,做事的原理和原則是道。術會從獨門絕技到普及再到落伍,追求術的人會很辛苦,只有掌握了道的本質和精髓才能永遠游刃有余。27. 真理在形式上從來是簡單的,而不是復雜和含混的。28. 搜索引擎不過是一張大表,表的每一行對應一個關鍵字,而每一個關鍵字后面跟著一組數字,是包含該關鍵詞的文獻序號。但當索引變的非常大的時候,這些索引需要通過分布式的方式存儲到不同的服務器上。29. 網絡爬蟲(Web Crawlers),圖論的遍歷算法和搜索引擎的關系。互聯網雖然復雜,但是說穿了其實就是一張大圖……可以把每一個網頁當做一個節點,把那些超鏈接當做連接網頁的弧。有了超鏈接,可以從任何一個網頁出發,用圖的遍歷算法,自動訪問到每一個網頁并且把他們存儲起來。完成這個功能的程序叫網絡爬蟲。30. 哥尼斯堡七橋,如果一個圖能從一個頂點出發,每條邊不重復的遍歷一遍回到這個頂點,那么每一個頂點的度必須為偶數。31. 構建網絡爬蟲的工程要點:1.用BFS(廣度優先搜索)還是DFS(深度優先搜索),一般是先下載完一個網站,再進入下一個網站,即BFS的成分多一些。2.頁面的分析和URL的提取,如果有些網頁明明存在,但搜索引擎并沒有收錄,可能的原因之一是網絡爬蟲中的解析程序沒能成功解析網頁中不規范的腳本程序。3.記錄哪些網頁已經下載過的URL表,可以用哈希表。最終,好的方法一般都采用了這樣兩個技術:首先明確每臺下載服務器的分工,也就是在調度時,一看到某個URL就知道要交給哪臺服務器去下載,這樣就避免了很多服務器對同一個URL做出是否需要下載的判斷。然后,在明確分工的基礎上,判斷URL是否下載就可以批處理了,比如每次向哈希表(一組獨立的服務器)發送一大批詢問,或者每次更新一大批哈希表的內容,這樣通信的次數就大大減少了。32. PageRank衡量網頁質量的核心思想,在互聯網上,如果一個網頁被很多其他網頁所鏈接,說明它受到普遍的承認和信賴,那么它的排名就高。同時,對于來自不同網頁的鏈接區別對待,因為網頁排名高的那些網頁的鏈接更可靠,于是要給這些鏈接比較大的權重。33. TF-IDF(Term Frequency / Inverse Document Frequency) ,關鍵詞頻率-逆文本頻率值,其中,TF為某個網頁上出現關鍵詞的頻率,IDF為假定一個關鍵詞w在Dw個網頁中出現過,那么Dw越大,w的權重越小,反之亦然,公式為log(D/Dw)。1.一個詞預測主題的能力越強,權重越大,反之,權重越小。2.停止詞的權重為零。34. 動態規劃(Dynamic Programming)的原理,將一個尋找全程最優的問題分解成一個個尋找局部最優的小問題。35. 一個好的算法應該像輕武器中最有名的AK-47沖鋒槍那樣:簡單、有效、可靠性好而且容易讀懂(易操作)而不應該故弄玄虛。選擇簡單方案可以容易解釋每個步驟和方法背后的道理,這樣不僅便于出問題時的查錯,也容易找到今后改進的目標。36. 在實際的分類中,可以先進行奇異值分解(得到分類結果略顯粗糙但能較快得到結果),在粗分類結果的基礎上,利用計算向量余弦的方法(對范圍內的分類做兩兩計算),在粗分類結果的基礎上,進行幾次迭代,得到比較精確的結果。37. 奇異值分解(Singular Value Decomposition),在需要用一個大矩陣A來描述成千上萬文章和幾十上百萬詞的關聯性時,計算量非常大,可以將A奇異值分解為X、B和Y三個矩陣,Amn=Xmm*Bmn*Ynn,X表示詞和詞類的相關性,Y表示文本和主題的相關性,B表示詞類和主題的相關性,其中B對角線上的元素很多值相對其他的非常小,或者為零,可以省略。對關聯矩陣A進行一次奇異值分解,就可以同時完成近義詞分類和文章的分類,同時能得到每個主題和每個詞義類之間的相關性,這個結果非常漂亮。38. 信息指紋。如果能夠找到一種函數,將5000億網址隨即地映射到128位二進制,也就是16字節的整數空間,就稱這16字節的隨機數做該網址的信息指紋。信息指紋可以理解為將一段信息映射到一個多維二進制空間中的一個點,只要這個隨即函數做的好,那么不同信息對應的點不會重合,因此這個二進制的數字就變成了原來信息所具有的獨一無二的指紋。39. 判斷兩個集合是否相同,最笨的方法是這個集合中的元素一一比較,復雜度O(squareN),稍好的是將元素排序后順序比較,復雜度O(NlogN),最完美的方法是計算這兩個集合的指紋,然后直接進行比較,計算復雜度O(N)。40. 偽隨機數產生器算法(Pseudo-Random Number Generator,PRNG),這是產生信息指紋的關鍵算法,通過他可以將任意長的整數轉換成特定長度的偽隨機數。最早的PRNG是將一個數的平方掐頭去尾取中間,當然這種方法不是很隨即,現在常用的是梅森旋轉算法(Mersenne Twister)。41. 在互聯網上加密要使用基于加密的偽隨機數產生器(Cryptography Secure Pseudo-Random Number Generator,CSPRNG),常用的算法有MD5或者SHA-1等標準,可以將不定長的信息變成定長的128位或者160位二進制隨機數。42. 最大熵模型(Maximum Entropy)的原理就是保留全部的不確定性,將風險降到最小。最大熵原理指出,需要對一個隨機事件的概率分布進行預測時,我們的預測應當滿足全部已知的條件,而對未知的情況不要做任何主觀假設。在這種情況下,概率分布最均勻,預測的風險最小。I.Csiszar證明,對任何一組不自相矛盾的信息,這個最大熵模型不僅存在,而且是唯一的,此外,他們都有同一個非常簡單的形式-指數函數。43. 通用迭代算法(Generalized Iterative Scaling,GIS)是最原始的最大熵模型的訓練方法。1.假定第零次迭代的初始模型為等概率的均勻分布。2.用第N次迭代的模型來估算每種信息特征在訓練數據中的分布。如果超過了實際的,就把相應的模型參數變小,反之變大。3.重復步驟2直至收斂。這是一種典型的期望值最大化(Expectation Maximization,EM)算法。IIS(Improved Iterative Scaling)比GIS縮短了一到兩個數量級。44. 布隆過濾器實際上是一個很長的二進制向量和一系列隨機映射的函數。45. 貝葉斯網絡從數學的層面講是一個加權的有向圖,是馬爾科夫鏈的擴展,而從知識論的層面看,貝葉斯網絡克服了馬爾科夫那種機械的線性的約束,它可以把任何有關聯的事件統一到它的框架下面。在網絡中,假定馬爾科夫假設成立,即每一個狀態只與和它直接相連的狀態有關,而和他間接相連的狀態沒有直接關系,那么它就是貝葉斯網絡。在網絡中每個節點概率的計算,都可以用貝葉斯公式來進行,貝葉斯網絡也因此得名。由于網絡的每個弧都有一個可信度,貝葉斯網絡也被稱作信念網絡(Belief Networks)。46. 條件隨機場是計算聯合概率分布的有效模型。在一個隱含馬爾科夫模型中,以x1,x2,...,xn表示觀測值序列,以y1,y2,...,yn表示隱含的狀態序列,那么xi只取決于產生它們的狀態yi,和前后的狀態yi-1和yi+1都無關。顯然很多應用里觀察值xi可能和前后的狀態都有關,如果把xi和yi-1,yi,yi+1都考慮進來,這樣的模型就是條件隨機場。它是一種特殊的概率圖模型(Probablistic Graph Model),它的特殊性在于,變量之間要遵守馬爾科夫假設,即每個狀態的轉移概率只取決于相鄰的狀態,這一點和另一種概率圖模型貝葉斯網絡相同,它們的不同之處在于條件隨機場是無向圖,而貝葉斯網絡是有向圖。47. 維特比算法(Viterbi Algoritm)是一個特殊但應用最廣的動態規劃算法,利用動態規劃,可以解決任何一個圖中的最短路徑問題。它之所以重要,是因為凡是使用隱含馬爾科夫模型描述的問題都可以用它來解碼。1.從點S出發,對于第一個狀態x1的各個節點,不妨假定有n1個,計算出S到他們的距離d(S,x1i),其中x1i代表任意狀態1的節點。因為只有一步,所以這些距離都是S到他們各自的最短距離。2.對于第二個狀態x2的所有節點,要計算出從S到他們的最短距離。d(S,x2i)=min_I=1,n1_d(S,x1j)+d(x1j,x2i),由于j有n1種可能性,需要一一計算,然后找到最小值。這樣對于第二個狀態的每個節點,需要n1次乘法計算。假定這個狀態有n2個節點,把S這些節點的距離都算一遍,就有O(n1*n2)次運算。3.按照上述方法從第二個狀態走到第三個狀態一直走到最后一個狀態,這樣就得到整個網絡從頭到尾的最短路徑。48. 擴頻傳輸(Spread-Spectrum Transmission)和固定頻率的傳輸相比,有三點明顯的好處:1.抗干擾能力強。2.信號能量非常低,很難獲取。3.擴頻傳輸利用帶寬更充分。49. Google針對云計算給出的解決工具是MapReduce,其根本原理就是計算機算法上常見的分治算法(Divide-and-Conquer)。將一個大任務拆分成小的子任務,并完成子任務的計算,這個過程叫Map,將中間結果合并成最終結果,這個過程叫Reduce。50. 邏輯回歸模型(Logistic Regression)是將一個事件出現的概率適應到一條邏輯曲線(Logistic Curve)上。典型的邏輯回歸函數:f(z)=e`z/e`z+1=1/1+e`-z。邏輯曲線是一條S型曲線,其特點是開始變化快,逐漸減慢,最后飽和。邏輯自回歸的好處是它的變量范圍從負無窮到正無窮,而值域范圍限制在0-1之間。因為值域的范圍在0-1之間,這樣邏輯回歸函數就可以和一個概率分別聯系起來了。因為自變量范圍在負無窮到正無窮之間,它就可以把信號組合起來,不論組合成多大或者多小的值,最后依然能得到一個概率分布。51. 期望最大化算法(Expectation Maximization Algorithm),根據現有的模型,計算各個觀測數據輸入到模型中的計算結果,這個過程稱為期望值計算過程(Expectation),或E過程;接下來,重新計算模型參數,以最大化期望值,這個過程稱為最大化的過程(Maximization),或M過程。這一類算法都稱為EM算法,比如隱含馬爾科夫模型的訓練方法Baum-Welch算法,以及最大熵模型的訓練方法GIS算法。
posted @
2012-09-18 15:04 胡滿超 閱讀(475) |
評論 (0) |
編輯 收藏posted @
2012-09-07 13:15 胡滿超 閱讀(364) |
評論 (0) |
編輯 收藏在Windows平臺做開發肯定會接觸到UI程序的編寫,以MFC的UI開發為例,可以開發單文檔,多文檔,對話框等形式的應用。寫一個UI程序容易,寫好卻不是一件簡單的事情。在整個代碼結構的清晰性與可維護性方面需要多加注意。寫好UI程序需求注意以下幾點:
1、圍繞數據編程與不是圍繞UI編程
當我們拿到需求最先接觸到的就是UI的設計,也許是美工畫的,也許是設計草圖。工程師在具體設計的時候容易受UI的影響,或者干脆從UI開始編程。
這是一個錯誤的編程習慣,無論UI如何展現與交互,最終都應該圍繞數據編程。拿到需求后,應該先思考和推敲數據的設計與流轉,UI不過就是數據的一種展現形式而已。
2、做好UI與邏輯的解耦
UI的編程會涉及到許多控件的操作,消息的處理,不知不覺,一個UI類的代碼會越寫越大,以至于一段時間以后,瀏覽和梳理都會變得不太方便。
在UI類里,除了與UI本身的操作有關的代碼以外,任何邏輯代碼都應該與此解耦,并根據具體情況進行封裝調用。如果一個控件關聯了太多數據操作,應該把這些操作封裝到控件的繼承類中,把一類代碼進行集中管理和維護。
上述問題,在程序寫作的初期還不太明顯,隨著代碼逐漸膨脹,會越會越讓人難以忍受。
3、數據單向依賴,單向更新
UI圍繞的數據進行展現與更新,在這個過程中,所以對數據的操作應該進行封裝,而不是散落在UI程序在各個角落,數據的更新、獲取和UI傳遞消息時,應該單向操作,如果出現循環處理的情況,在以后維護調試的BUG的過程中會變得比較困難,導致維護效率下降。
posted @
2012-08-31 17:00 胡滿超 閱讀(1059) |
評論 (0) |
編輯 收藏posted @
2012-03-23 17:16 胡滿超 閱讀(6122) |
評論 (1) |
編輯 收藏在 Windows x64 上共有2種查看方式。一種用于 32-bit 應用程序,另一種用于 x64 應用程序。默認情況下,32-bit 應用程序運行在 x64 系統的 WOW64 模式下時,只允許使用 32-bit 查看方式。使用
SetRegView 64 將允許安裝程序在 x64 中訪問注冊表鍵值。恢復訪問32位注冊表使用
SetRegView 32。
它將影響
DeleteRegKey,
DeleteRegValue,
EnumRegKey,
EnumRegValue,
ReadRegDWORD,
ReadRegStr,
WriteRegBin,
WriteRegDWORD,
WriteRegStr 和
WriteRegExpandStr。
posted @
2012-03-09 10:29 胡滿超 閱讀(1603) |
評論 (0) |
編輯 收藏轉自:http://www.ibm.com/developerworks/cn/linux/l-cn-valgrind/
Valgrind 概述
體系結構
Valgrind是一套Linux下,開放源代碼(GPL V2)的仿真調試工具的集合。Valgrind由內核(core)以及基于內核的其他調試工具組成。內核類似于一個框架(framework),它模擬了 一個CPU環境,并提供服務給其他工具;而其他工具則類似于插件 (plug-in),利用內核提供的服務完成各種特定的內存調試任務。Valgrind的體系結構如下圖所示:
圖 1 Valgrind 體系結構
Valgrind包括如下一些工具:
- Memcheck。這是valgrind應用最廣泛的工具,一個重量級的內存檢查器,能夠發現開發中絕大多數內存錯誤使用情況,比如:使用未初始化的內存,使用已經釋放了的內存,內存訪問越界等。這也是本文將重點介紹的部分。
- Callgrind。它主要用來檢查程序中函數調用過程中出現的問題。
- Cachegrind。它主要用來檢查程序中緩存使用出現的問題。
- Helgrind。它主要用來檢查多線程程序中出現的競爭問題。
- Massif。它主要用來檢查程序中堆棧使用中出現的問題。
- Extension。可以利用core提供的功能,自己編寫特定的內存調試工具。
Linux 程序內存空間布局
要發現Linux下的內存問題,首先一定要知道在Linux下,內存是如何被分配的?下圖展示了一個典型的Linux C程序內存空間布局:
圖 2: 典型內存空間布局
一個典型的Linux C程序內存空間由如下幾部分組成:
- 代碼段(.text)。這里存放的是CPU要執行的指令。代碼段是可共享的,相同的代碼在內存中只會有一個拷貝,同時這個段是只讀的,防止程序由于錯誤而修改自身的指令。
- 初始化數據段(.data)。這里存放的是程序中需要明確賦初始值的變量,例如位于所有函數之外的全局變量:int val=100。需要強調的是,以上兩段都是位于程序的可執行文件中,內核在調用exec函數啟動該程序時從源程序文件中讀入。
- 未初始化數據段(.bss)。位于這一段中的數據,內核在執行該程序前,將其初始化為0或者null。例如出現在任何函數之外的全局變量:int sum;
- 堆(Heap)。這個段用于在程序中進行動態內存申請,例如經常用到的malloc,new系列函數就是從這個段中申請內存。
- 棧(Stack)。函數中的局部變量以及在函數調用過程中產生的臨時變量都保存在此段中。
內存檢查原理
Memcheck檢測內存問題的原理如下圖所示:
圖 3 內存檢查原理
Memcheck 能夠檢測出內存問題,關鍵在于其建立了兩個全局表。
- Valid-Value 表:
對于進程的整個地址空間中的每一個字節(byte),都有與之對應的 8 個 bits;對于 CPU 的每個寄存器,也有一個與之對應的 bit 向量。這些 bits 負責記錄該字節或者寄存器值是否具有有效的、已初始化的值。
- Valid-Address 表
對于進程整個地址空間中的每一個字節(byte),還有與之對應的 1 個 bit,負責記錄該地址是否能夠被讀寫。
檢測原理:
- 當要讀寫內存中某個字節時,首先檢查這個字節對應的 A bit。如果該A bit顯示該位置是無效位置,memcheck 則報告讀寫錯誤。
- 內核(core)類似于一個虛擬的 CPU 環境,這樣當內存中的某個字節被加載到真實的 CPU 中時,該字節對應的 V bit 也被加載到虛擬的 CPU 環境中。一旦寄存器中的值,被用來產生內存地址,或者該值能夠影響程序輸出,則 memcheck 會檢查對應的V bits,如果該值尚未初始化,則會報告使用未初始化內存錯誤。
回頁首
Valgrind 使用
第一步:準備好程序
為了使valgrind發現的錯誤更精確,如能夠定位到源代碼行,建議在編譯時加上-g參數,編譯優化選項請選擇O0,雖然這會降低程序的執行效率。
這里用到的示例程序文件名為:sample.c(如下所示),選用的編譯器為gcc。
生成可執行程序 gcc –g –O0 sample.c –o sample
清單 1
第二步:在valgrind下,運行可執行程序。
利用valgrind調試內存問題,不需要重新編譯源程序,它的輸入就是二進制的可執行程序。調用Valgrind的通用格式是:valgrind [valgrind-options] your-prog [your-prog-options]
Valgrind 的參數分為兩類,一類是 core 的參數,它對所有的工具都適用;另外一類就是具體某個工具如 memcheck 的參數。Valgrind 默認的工具就是 memcheck,也可以通過“--tool=tool name”指定其他的工具。Valgrind 提供了大量的參數滿足你特定的調試需求,具體可參考其用戶手冊。
這個例子將使用 memcheck,于是可以輸入命令入下:valgrind <Path>/sample.
第三步:分析 valgrind 的輸出信息。
以下是運行上述命令后的輸出。
清單 2
- 左邊顯示類似行號的數字(32372)表示的是 Process ID。
- 最上面的紅色方框表示的是 valgrind 的版本信息。
- 中間的紅色方框表示 valgrind 通過運行被測試程序,發現的內存問題。通過閱讀這些信息,可以發現:
- 這是一個對內存的非法寫操作,非法寫操作的內存是4 bytes。
- 發生錯誤時的函數堆棧,以及具體的源代碼行號。
- 非法寫操作的具體地址空間。
- 最下面的紅色方框是對發現的內存問題和內存泄露問題的總結。內存泄露的大小(40 bytes)也能夠被檢測出來。
示例程序顯然有兩個問題,一是fun函數中動態申請的堆內存沒有釋放;二是對堆內存的訪問越界。這兩個問題均被valgrind發現。
回頁首
利用Memcheck發現常見的內存問題
在Linux平臺開發應用程序時,最常遇見的問題就是錯誤的使用內存,我們總結了常見了內存錯誤使用情況,并說明了如何用valgrind將其檢測出來。
使用未初始化的內存
問題分析:
對于位于程序中不同段的變量,其初始值是不同的,全局變量和靜態變量初始值為0,而局部變量和動態申請的變量,其初始值為隨機值。如果程序使用了為隨機值的變量,那么程序的行為就變得不可預期。
下面的程序就是一種常見的,使用了未初始化的變量的情況。數組a是局部變量,其初始值為隨機值,而在初始化時并沒有給其所有數組成員初始化,如此在接下來使用這個數組時就潛在有內存問題。
清單 3
結果分析:
假設這個文件名為:badloop.c,生成的可執行程序為badloop。用memcheck對其進行測試,輸出如下。
清單 4
輸出結果顯示,在該程序第11行中,程序的跳轉依賴于一個未初始化的變量。準確的發現了上述程序中存在的問題。
內存讀寫越界
問題分析:
這種情況是指:訪問了你不應該/沒有權限訪問的內存地址空間,比如訪問數組時越界;對動態內存訪問時超出了申請的內存大小范圍。下面的程序就是一個 典型的數組越界問題。pt是一個局部數組變量,其大小為4,p初始指向pt數組的起始地址,但在對p循環疊加后,p超出了pt數組的范圍,如果此時再對p 進行寫操作,那么后果將不可預期。
清單 5
結果分析:
假設這個文件名為badacc.cpp,生成的可執行程序為badacc,用memcheck對其進行測試,輸出如下。
清單 6
輸出結果顯示,在該程序的第15行,進行了非法的寫操作;在第16行,進行了非法讀操作。準確地發現了上述問題。
內存覆蓋
問題分析:
C 語言的強大和可怕之處在于其可以直接操作內存,C 標準庫中提供了大量這樣的函數,比如 strcpy, strncpy, memcpy, strcat 等,這些函數有一個共同的特點就是需要設置源地址 (src),和目標地址(dst),src 和 dst 指向的地址不能發生重疊,否則結果將不可預期。
下面就是一個 src 和 dst 發生重疊的例子。在 15 與 17 行中,src 和 dst 所指向的地址相差 20,但指定的拷貝長度卻是 21,這樣就會把之前的拷貝值覆蓋。第 24 行程序類似,src(x+20) 與 dst(x) 所指向的地址相差 20,但 dst 的長度卻為 21,這樣也會發生內存覆蓋。
清單 7
結果分析:
假設這個文件名為 badlap.cpp,生成的可執行程序為 badlap,用 memcheck 對其進行測試,輸出如下。
清單 8
輸出結果顯示上述程序中第15,17,24行,源地址和目標地址設置出現重疊。準確的發現了上述問題。
動態內存管理錯誤
問題分析:
常見的內存分配方式分三種:靜態存儲,棧上分配,堆上分配。全局變量屬于靜態存儲,它們是在編譯時就被分配了存儲空間,函數內的局部變量屬于棧上分 配,而最靈活的內存使用方式當屬堆上分配,也叫做內存動態分配了。常用的內存動態分配函數包括:malloc, alloc, realloc, new等,動態釋放函數包括free, delete。
一旦成功申請了動態內存,我們就需要自己對其進行內存管理,而這又是最容易犯錯誤的。下面的一段程序,就包括了內存動態管理中常見的錯誤。
清單 9
常見的內存動態管理錯誤包括:
由于 C++ 兼容 C,而 C 與 C++ 的內存申請和釋放函數是不同的,因此在 C++ 程序中,就有兩套動態內存管理函數。一條不變的規則就是采用 C 方式申請的內存就用 C 方式釋放;用 C++ 方式申請的內存,用 C++ 方式釋放。也就是用 malloc/alloc/realloc 方式申請的內存,用 free 釋放;用 new 方式申請的內存用 delete 釋放。在上述程序中,用 malloc 方式申請了內存卻用 delete 來釋放,雖然這在很多情況下不會有問題,但這絕對是潛在的問題。
申請了多少內存,在使用完成后就要釋放多少。如果沒有釋放,或者少釋放了就是內存泄露;多釋放了也會產生問題。上述程序中,指針p和pt指向的是同一塊內存,卻被先后釋放兩次。
本質上說,系統會在堆上維護一個動態內存鏈表,如果被釋放,就意味著該塊內存可以繼續被分配給其他部分,如果內存被釋放后再訪問,就可能覆蓋其他部分的信息,這是一種嚴重的錯誤,上述程序第16行中就在釋放后仍然寫這塊內存。
結果分析:
假設這個文件名為badmac.cpp,生成的可執行程序為badmac,用memcheck對其進行測試,輸出如下。
清單 10
輸出結果顯示,第14行分配和釋放函數不一致;第16行發生非法寫操作,也就是往釋放后的內存地址寫值;第17行釋放內存函數無效。準確地發現了上述三個問題。
內存泄露
問題描述:
內存泄露(Memory leak)指的是,在程序中動態申請的內存,在使用完后既沒有釋放,又無法被程序的其他部分訪問。內存泄露是在開發大型程序中最令人頭疼的問題,以至于有 人說,內存泄露是無法避免的。其實不然,防止內存泄露要從良好的編程習慣做起,另外重要的一點就是要加強單元測試(Unit Test),而memcheck就是這樣一款優秀的工具。
下面是一個比較典型的內存泄露案例。main函數調用了mk函數生成樹結點,可是在調用完成之后,卻沒有相應的函數:nodefr釋放內存,這樣內存中的這個樹結構就無法被其他部分訪問,造成了內存泄露。
在一個單獨的函數中,每個人的內存泄露意識都是比較強的。但很多情況下,我們都會對malloc/free 或new/delete做一些包裝,以符合我們特定的需要,無法做到在一個函數中既使用又釋放。這個例子也說明了內存泄露最容易發生的地方:即兩個部分的 接口部分,一個函數申請內存,一個函數釋放內存。并且這些函數由不同的人開發、使用,這樣造成內存泄露的可能性就比較大了。這需要養成良好的單元測試習 慣,將內存泄露消滅在初始階段。
清單 11 清單 11.2
清單 11.2 清單 11.3
清單 11.3
結果分析:
假設上述文件名位tree.h, tree.cpp, badleak.cpp,生成的可執行程序為badleak,用memcheck對其進行測試,輸出如下。
清單 12
該示例程序是生成一棵樹的過程,每個樹節點的大小為12(考慮內存對齊),共8個節點。從上述輸出可以看出,所有的內存泄露都被發現。 Memcheck將內存泄露分為兩種,一種是可能的內存泄露(Possibly lost),另外一種是確定的內存泄露(Definitely lost)。Possibly lost 是指仍然存在某個指針能夠訪問某塊內存,但該指針指向的已經不是該內存首地址。Definitely lost 是指已經不能夠訪問這塊內存。而Definitely lost又分為兩種:直接的(direct)和間接的(indirect)。直接和間接的區別就是,直接是沒有任何指針指向該內存,間接是指指向該內存的 指針都位于內存泄露處。在上述的例子中,根節點是directly lost,而其他節點是indirectly lost。
回頁首
總結
本文介紹了valgrind的體系結構,并重點介紹了其應用最廣泛的工具:memcheck。闡述了memcheck發現內存問題的基本原理,基本 使用方法,以及利用memcheck如何發現目前開發中最廣泛的五大類內存問題。在項目中盡早的發現內存問題,能夠極大地提高開發效率,valgrind 就是能夠幫助你實現這一目標的出色工具。
參考資料
關于作者
楊經,他的技術興趣包括自動化測試與linux系統管理。目前是IBM中國系統與技術實驗室(CSTL)的軟件工程師,從事中小型企業(SME)服務器的測試工作,可以通過cdlyangj@cn.ibm.com與他聯系。
posted @
2011-12-30 14:24 胡滿超 閱讀(339) |
評論 (0) |
編輯 收藏
新建一個DEF文件(右鍵Project->Add->New Item->.def)
加入
EXPORTS
fn_function @ 1
重新編譯就OK了
參考鏈接:
http://blog.csdn.net/cglover/article/details/1621685
posted @
2011-11-21 17:45 胡滿超 閱讀(983) |
評論 (0) |
編輯 收藏
Set objshell = CreateObject("wscript.shell")
strDomainDnsName = LCase(objshell.ExpandEnvironmentStrings("%USERDNSDOMAIN%"))
If strDomainDnsName = "%USERDNSDOMAIN%" Then
WScript.Echo "workgroup"
Else
WScript.Echo "Domain"
End if
本文出自 “okhelper” 博客,請務必保留此出處http://okhelper.blog.51cto.com/313500/197249
注意:下面的鏈接提供了7種方法
http://www.robvanderwoude.com/vbstech_network_names_domain.php
| Environment Variable |
|---|
| VBScript Code: |
Set wshShell = WScript.CreateObject( "WScript.Shell" )
strUserDomain = wshShell.ExpandEnvironmentStrings( "%USERDOMAIN%" )
WScript.Echo "User Domain: " & strUserDomain |
| Requirements: |
| Windows version: | NT 4, 2000, XP, Server 2003, Vista or Server 2008 |
| Network: | Stand-alone, workgroup, NT domain, or AD |
| Client software: | N/A |
| Script Engine: | WSH |
| Summarized: | Works in Windows NT 4 or later, *.vbs with CSCRIPT.EXE or WSCRIPT.EXE only.
Doesn't work in Windows 95, 98 or ME, nor in Internet Explorer (HTAs). |
| |
| [Back to the top of this page] |
| |
| WshNetwork |
| VBScript Code: |
Set wshNetwork = WScript.CreateObject( "WScript.Network" )
strUserDomain = wshNetwork.UserDomain
WScript.Echo "User Domain: " & strUserDomain |
| Requirements: |
| Windows version: | Windows 98, ME, NT 4, 2000, XP, Server 2003, Vista, Server 2008 |
| Network: | Stand-alone, workgroup, NT domain, or AD |
| Client software: | Windows Script 5.6 for Windows 98, ME, and NT 4 (no longer available for download?) |
| Script Engine: | WSH |
| Summarized: | Works in Windows 98 or later, *.vbs with CSCRIPT.EXE or WSCRIPT.EXE only.
Doesn't work in Windows 95, nor in Internet Explorer (HTAs). |
| |
| [Back to the top of this page] |
| |
| ADSI (WinNTSystemInfo) |
| VBScript Code: |
Set objSysInfo = CreateObject( "WinNTSystemInfo" )
strUserDomain = objSysInfo.DomainName
WScript.Echo "User Domain: " & strUserDomain |
| Requirements: |
| Windows version: | 2000, XP, Server 2003, Vista or Server 2008 (95, 98, ME, NT 4 with Active Directory client extension) |
| Network: | Stand-alone, workgroup, NT domain, or AD |
| Client software: | Active Directory client extension for Windows 95, 98, ME or NT 4 |
| Script Engine: | any |
| Summarized: | Can work in any Windows version, but Active Directory client extension is required for Windows 95, 98, ME or NT 4.
Can be used in *.vbs with CSCRIPT.EXE or WSCRIPT.EXE, as well as in HTAs. |
| |
| [Back to the top of this page] |
| |
| ADSI (ADSystemInfo) |
| VBScript Code: |
Set objSysInfo = CreateObject( "ADSystemInfo" )
strUserDomain = objSysInfo.DomainName
WScript.Echo "User Domain: " & strUserDomain |
| Requirements: |
| Windows version: | 2000, XP, Server 2003, Vista or Server 2008 (95, 98, ME, NT 4 with Active Directory client extension) |
| Network: | Only AD domain members |
| Client software: | Active Directory client extension for Windows 95, 98, ME or NT 4 |
| Script Engine: | any |
| Summarized: | For AD domain members only.
Can work in any Windows version, but Active Directory client extension is required for Windows 95, 98, ME or NT 4 SP4.
Can be used in *.vbs with CSCRIPT.EXE or WSCRIPT.EXE, as well as in HTAs.
Doesn't work on stand-alones, workgroup members or members of NT domains. |
| |
| [Back to the top of this page] |
| |
| WMI (Win32_ComputerSystem) |
| VBScript Code: |
Set objWMISvc = GetObject( "winmgmts:\\.\root\cimv2" )
Set colItems = objWMISvc.ExecQuery( "Select * from Win32_ComputerSystem", , 48 )
For Each objItem in colItems
strComputerDomain = objItem.Domain
If objItem.PartOfDomain Then
WScript.Echo "Computer Domain: " & strComputerDomain
Else
WScript.Echo "Workgroup: " & strComputerDomain
End If
Next |
| Requirements: |
| Windows version: | XP, Server 2003, Vista or Server 2008 |
| Network: | Stand-alone, workgroup, NT domain, or AD |
| Client software: | N/A |
| Script Engine: | any |
| Summarized: | Works in Windows XP and later.
Can be used in *.vbs with CSCRIPT.EXE or WSCRIPT.EXE, as well as in HTAs. |
| |
| [Back to the top of this page] |
| |
| WMI (Win32_NTDomain) |
| VBScript Code: |
Set objWMISvc = GetObject( "winmgmts:\\.\root\cimv2" )
Set colItems = objWMISvc.ExecQuery( "Select * from Win32_NTDomain", , 48 )
For Each objItem in colItems
strComputerDomain = objItem.DomainName
WScript.Echo "Computer Domain: " & strComputerDomain
Next |
| Requirements: |
| Windows version: | XP, Server 2003, Vista or Server 2008 |
| Network: | NT domain, or AD |
| Client software: | N/A |
| Script Engine: | any |
| Summarized: | Will work only on AD or NT domain members running Windows XP or later.
Can be used in *.vbs with CSCRIPT.EXE or WSCRIPT.EXE, as well as in HTAs.
Doesn't work in Windows 95, 98, ME, NT 4, or 2000.
Doesn't work on stand-alones or workgroup members. |
| |
| [Back to the top of this page] |
| |
| System Scripting Runtime |
| VBScript Code: |
Set objIP = CreateObject( "SScripting.IPNetwork" )
strComputerDomain = objIP.Domain
WScript.Echo "Computer Domain: " & strComputerDomain |
| Requirements: |
| Windows version: | any |
| Network: | TCP/IP |
| Client software: | System Scripting Runtime |
| Script Engine: | any |
| Summarized: | Works in any Windows version with System Scripting Runtime is installed, with any script engine. |
posted @
2011-09-26 10:09 胡滿超 閱讀(768) |
評論 (0) |
編輯 收藏
摘要: 轉自:http://www.cnblogs.com/k-eckel/articles/188489.html深入分析MFC文檔視圖結構(項目實踐) k_eckel:http://www.mscenter.edu.cn/blog/k_eckel 文檔視圖結構(Document/View Architecture)是MFC的精髓...
閱讀全文
posted @
2011-08-03 11:13 胡滿超 閱讀(1521) |
評論 (0) |
編輯 收藏