第二十三、四章:楊氏矩陣查找����,倒排索引關鍵詞Hash不重復編碼實踐
作者:July��、yansha����。編程藝術室出品。
出處:結構之法算法之道。
前言
本文闡述兩個問題,第二十三章是楊氏矩陣查找問題����,第二十四章是有關倒排索引中關鍵詞Hash編碼的問題��,主要要解決不重復以及追加的功能,同時也是經典算法研究系列十一、從頭到尾徹底解析Hash表算法之續。
OK,有任何問題����,也歡迎隨時交流或批評指正����。謝謝����。
第二十三章、楊氏矩陣查找
楊氏矩陣查找
先看一個來自算法導論習題里6-3與劍指offer的一道編程題(也被經常用作面試題,本人此前去搜狗二面時便遇到了):
在一個二維數組中,每一行都按照從左到右遞增的順序排序�����,每一列都按照從上到下遞增的順序排序�����。請完成一個函數��,輸入這樣的一個二維數組和一個整數,判斷數組中是否含有該整數。
例如下面的二維數組就是每行�����、每列都遞增排序�����。如果在這個數組中查找數字6,則返回true����;如果查找數字5�����,由于數組不含有該數字�����,則返回false。

本Young問題解法有二(如查找數字6):
1、分治法��,分為四個矩形�����,配以二分查找�����,如果要找的數是6介于對角線上相鄰的兩個數4、10�����,可以排除掉左上和右下的兩個矩形��,而遞歸在左下和右上的兩個矩形繼續找,如下圖所示:
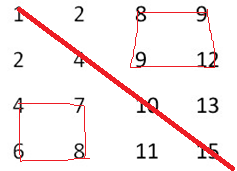
2����、首先直接定位到最右上角的元素�����,再配以二分查找,比要找的數(6)大就往左走��,比要找數(6)的小就往下走����,直到找到要找的數字(6)為止,如下圖所示: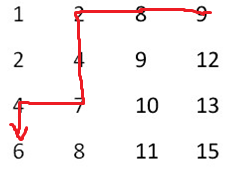
上述方法二的關鍵代碼+程序運行如下圖所示:

試問�����,上述算法復雜么��?不復雜����,只要稍微動點腦筋便能想到��,還可以參看友人老夢的文章�����,Young氏矩陣:http://blog.csdn.net/zhanglei8893/article/details/6234564,以及IT練兵場的:http://www.jobcoding.com/array/matrix/young-tableau-problem/����,除此之外�����,何海濤先生一書劍指offer中也收集了此題����,感興趣的朋友也可以去看看。
第二十四章、經典算法十一Hash表算法(續)��、倒排索引關鍵詞不重復Hash編碼
本章要介紹這樣一個問題��,對倒排索引中的關鍵詞進行編碼�����。那么��,這個問題將分為兩個個步驟:
- 首先,要提取倒排索引內詞典文件中的關鍵詞�����;
- 對提取出來的關鍵詞進行編碼����。本章采取hash編碼的方式。既然要用hash編碼�����,那么最重要的就是要解決hash沖突的問題�����,下文會詳細介紹����。
有一點必須提醒讀者的是,倒排索引包含詞典和倒排記錄表兩個部分�����,詞典一般有詞項(或稱為關鍵詞)和詞項頻率(即這個詞項或關鍵詞出現的次數)��,倒排記錄表則記錄著上述詞項(或關鍵詞)所出現的位置��,或出現的文檔及網頁ID等相關信息。
24.1、正排索引與倒排索引
咱們先來看什么是倒排索引�����,以及倒排索引與正排索引之間的區別:
我們知道�����,搜索引擎的關鍵步驟就是建立倒排索引����,所謂倒排索引一般表示為一個關鍵詞�����,然后是它的頻度(出現的次數)��,位置(出現在哪一篇文章或網頁中,及有關的日期��,作者等信息)�����,它相當于為互聯網上幾千億頁網頁做了一個索引��,好比一本書的目錄��、標簽一般����。讀者想看哪一個主題相關的章節����,直接根據目錄即可找到相關的頁面。不必再從書的第一頁到最后一頁�����,一頁一頁的查找��。
接下來��,闡述下正排索引與倒排索引的區別:
一般索引(正排索引)
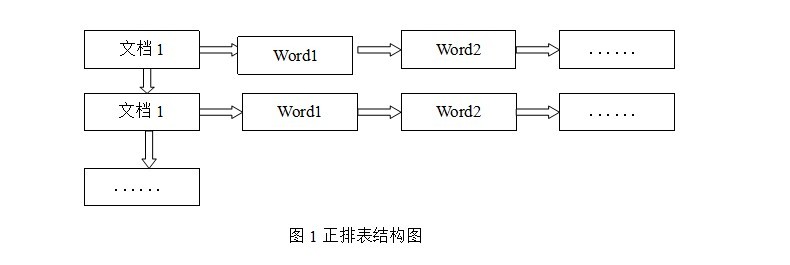
正排表是以文檔的ID為關鍵字,表中記錄文檔中每個字的位置信息����,查找時掃描表中每個文檔中字的信息直到找出所有包含查詢關鍵字的文檔����。正排表結構如圖1所示,這種組織方法在建立索引的時候結構比較簡單�����,建立比較方便且易于維護;因為索引是基于文檔建立的�����,若是有新的文檔假如��,直接為該文檔建立一個新的索引塊����,掛接在原來索引文件的后面。若是有文檔刪除�����,則直接找到該文檔號文檔對因的索引信息����,將其直接刪除。但是在查詢的時候需對所有的文檔進行掃描以確保沒有遺漏����,這樣就使得檢索時間大大延長��,檢索效率低下。
盡管正排表的工作原理非常的簡單�����,但是由于其檢索效率太低��,除非在特定情況下�����,否則實用性價值不大。
倒排索引
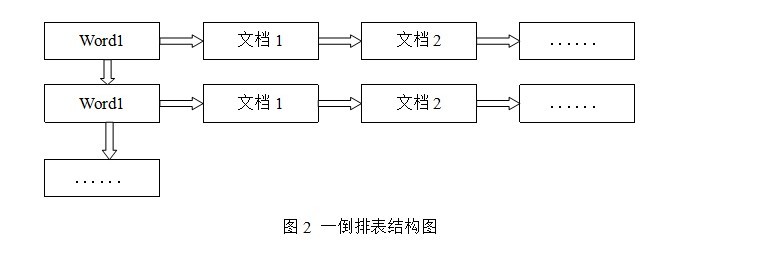
倒排表以字或詞為關鍵字進行索引�����,表中關鍵字所對應的記錄表項記錄了出現這個字或詞的所有文檔�����,一個表項就是一個字表段,它記錄該文檔的ID和字符在該文檔中出現的位置情況。由于每個字或詞對應的文檔數量在動態變化����,所以倒排表的建立和維護都較為復雜�����,但是在查詢的時候由于可以一次得到查詢關鍵字所對應的所有文檔,所以效率高于正排表。在全文檢索中��,檢索的快速響應是一個最為關鍵的性能����,而索引建立由于在后臺進行,盡管效率相對低一些,但不會影響整個搜索引擎的效率�����。
倒排表的結構圖如圖2:
倒排表的索引信息保存的是字或詞后繼數組模型�����、互關聯后繼數組模型條在文檔內的位置��,在同一篇文檔內相鄰的字或詞條的前后關系沒有被保存到索引文件內����。
24.2����、倒排索引中提取關鍵詞
倒排索引是搜索引擎之基石。建成了倒排索引后��,用戶要查找某個query����,如在搜索框輸入某個關鍵詞:“結構之法”后����,搜索引擎不會再次使用爬蟲又一個一個去抓取每一個網頁,從上到下掃描網頁,看這個網頁有沒有出現這個關鍵詞,而是會在它預先生成的倒排索引文件中查找和匹配包含這個關鍵詞“結構之法”的所有網頁��。找到了之后��,再按相關性度排序�����,最終把排序后的結果顯示給用戶。

如下�����,即是一個倒排索引文件(不全)����,我們把它取名為big_index,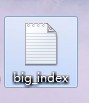 文件中每一較短的��,不包含有“#####”符號的便是某個關鍵詞�����,及這個關鍵詞的出現次數?����,F在要從這個大索引文件中提取出這些關鍵詞,--Firelf--,-11�����,-Winter-��,.,007�����,007:天降殺機����,02Chan..如何做到呢?一行一行的掃描整個索引文件么��?
文件中每一較短的��,不包含有“#####”符號的便是某個關鍵詞�����,及這個關鍵詞的出現次數?����,F在要從這個大索引文件中提取出這些關鍵詞,--Firelf--,-11�����,-Winter-��,.,007�����,007:天降殺機����,02Chan..如何做到呢?一行一行的掃描整個索引文件么��?
何意��?之前已經說過:倒排索引包含詞典和倒排記錄表兩個部分����,詞典一般有詞項(或稱為關鍵詞)和詞項頻率(即這個詞項或關鍵詞出現的次數)����,倒排記錄表則記錄著上述詞項(或關鍵詞)所出現的位置,或出現的文檔及網頁ID等相關信息�����。
最簡單的講�����,就是要提取詞典中的詞項(關鍵詞):--Firelf--����,-11��,-Winter-�����,.,007��,007:天降殺機����,02Chan...。
--Firelf--(關鍵詞) 8(出現次數)
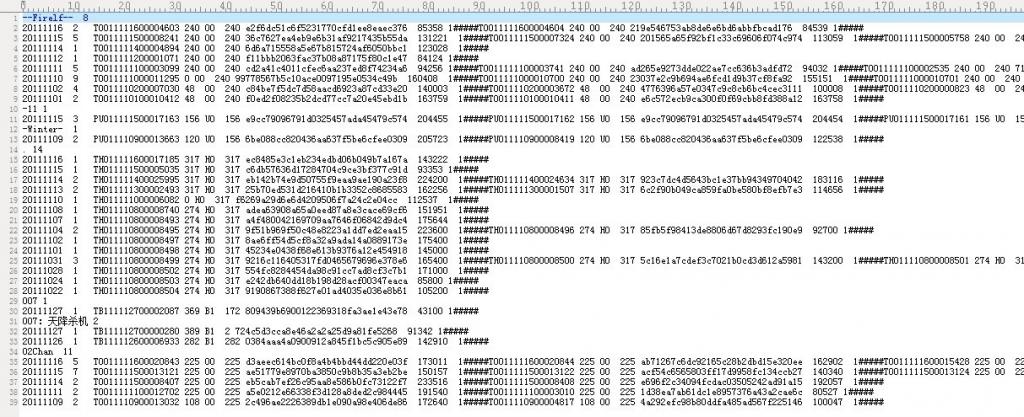
我們可以試著這么解決:通過查找#####便可判斷某一行出現的詞是不是關鍵詞��,但如果這樣做的話��,便要掃描整個索引文件的每一行����,代價實在巨大��。如何提高速度呢����?對了����,關鍵詞后面的那個出現次數為我們問題的解決起到了很好的作用,如下注釋所示:
// 本身沒有##### 的行判定為關鍵詞行��,后跟這個關鍵詞的行數N(即詞項頻率)
// 接下來�����,截取關鍵詞--Firelf--,然后讀取后面關鍵詞的行數N
// 再跳過N行(濾過和避免掃描中間的倒排記錄表信息)
// 讀取下一個關鍵詞..
有朋友指出,上述方法雖然減少了掃描的行數,但并沒有減少I0開銷��。讀者是否有更好地辦法����?歡迎隨時交流。
24.2、為提取出來的關鍵詞編碼
愛思考的朋友可能會問,上述從倒排索引文件中提取出那些關鍵詞(詞項)的操作是為了什么呢?其實如我個人微博上12月12日所述的Hash詞典編碼:
詞典文件的編碼:1�����、詞典怎么生成(存儲和構造詞典)����;2、如何運用hash對輸入的漢字進行編碼�����;3��、如何更好的解決沖突����,即不重復以及追加功能����。具體例子為:事先構造好詞典文件后,輸入一個詞,要求找到這個詞的編碼��,然后將其編碼輸出��。且要有不斷能添加詞的功能����,不得重復����。
步驟應該是如下:1、讀索引文件����;2��、提取索引中的詞出來;3��、詞典怎么生成��,存儲和構造詞典�����;4、詞典文件的編碼:不重復與追加功能。編碼比如��,輸入中國�����,他的編碼可以為10001�����,然后輸入銀行,他的編碼可以為10002����。只要實現不斷添加詞功能��,以及不重復即可,詞典類的大文件��,hash最重要的是怎樣避免沖突��。
也就是說,現在我要對上述提取出來后的關鍵詞進行編碼����,采取何種方式編碼呢�����?暫時用hash函數編碼。編碼之后的效果將是每一個關鍵詞都有一個特定的編碼��,如下圖所示(與上文big_index文件比較一下便知):
--Firelf-- 對應編碼為:135942
-11 對應編碼為:106101
....

但細心的朋友一看上圖便知�����,其中第34~39行顯示����,有重復的編碼�����,那么如何解決這個不重復編碼的問題呢��?
用hash表編碼?但其極易產生沖突碰撞��,為什么��?請看:
哈希表是一種查找效率極高的數據結構��,很多語言都在內部實現了哈希表。PHP中的哈希表是一種極為重要的數據結構����,不但用于表示Array數據類型�����,還在Zend虛擬機內部用于存儲上下文環境信息(執行上下文的變量及函數均使用哈希表結構存儲)��。
理想情況下哈希表插入和查找操作的時間復雜度均為O(1)��,任何一個數據項可以在一個與哈希表長度無關的時間內計算出一個哈希值(key),然后在常量時間內定位到一個桶(術語bucket,表示哈希表中的一個位置)�����。當然這是理想情況下,因為任何哈希表的長度都是有限的����,所以一定存在不同的數據項具有相同哈希值的情況��,此時不同數據項被定為到同一個桶,稱為碰撞(collision)����。
哈希表的實現需要解決碰撞問題��,碰撞解決大體有兩種思路,
- 第一種是根據某種原則將被碰撞數據定為到其它桶��,例如線性探測——如果數據在插入時發生了碰撞����,則順序查找這個桶后面的桶,將其放入第一個沒有被使用的桶�����;
- 第二種策略是每個桶不是一個只能容納單個數據項的位置��,而是一個可容納多個數據的數據結構(例如鏈表或紅黑樹)�����,所有碰撞的數據以某種數據結構的形式組織起來�����。
不論使用了哪種碰撞解決策略�����,都導致插入和查找操作的時間復雜度不再是O(1)。以查找為例,不能通過key定位到桶就結束����,必須還要比較原始key(即未做哈希之前的key)是否相等����,如果不相等��,則要使用與插入相同的算法繼續查找����,直到找到匹配的值或確認數據不在哈希表中��。
PHP是使用單鏈表存儲碰撞的數據����,因此實際上PHP哈希表的平均查找復雜度為O(L)��,其中L為桶鏈表的平均長度�����;而最壞復雜度為O(N)����,此時所有數據全部碰撞,哈希表退化成單鏈表��。下圖PHP中正常哈希表和退化哈希表的示意圖����。
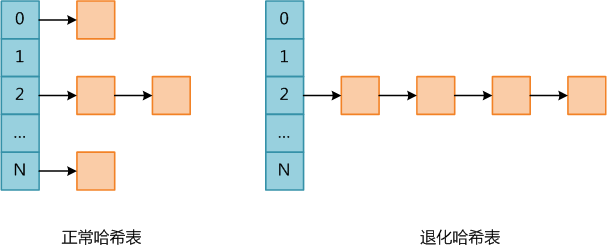
哈希表碰撞攻擊就是通過精心構造數據,使得所有數據全部碰撞�����,人為將哈希表變成一個退化的單鏈表,此時哈希表各種操作的時間均提升了一個數量級����,因此會消耗大量CPU資源����,導致系統無法快速響應請求��,從而達到拒絕服務攻擊(DoS)的目的�����。
可以看到,進行哈希碰撞攻擊的前提是哈希算法特別容易找出碰撞����,如果是MD5或者SHA1那基本就沒戲了�����,幸運的是(也可以說不幸的是)大多數編程語言使用的哈希算法都十分簡單(這是為了效率考慮)�����,因此可以不費吹灰之力之力構造出攻擊數據.(上述五段文字引自:http://www.codinglabs.org/html/hash-collisions-attack-on-php.html)����。
24.4����、暴雪的Hash算法
值得一提的是,在解決Hash沖突的時候��,搞的焦頭爛額��,結果今天上午在自己的博客內的一篇文章(十一����、從頭到尾徹底解析Hash表算法)內找到了解決辦法:網上流傳甚廣的暴雪的Hash算法����。 OK,接下來��,咱們回顧下暴雪的hash表算法:
“接下來����,咱們來具體分析一下一個最快的Hash表算法。
我們由一個簡單的問題逐步入手:有一個龐大的字符串數組����,然后給你一個單獨的字符串����,讓你從這個數組中查找是否有這個字符串并找到它����,你會怎么做��?
有一個方法最簡單����,老老實實從頭查到尾����,一個一個比較,直到找到為止,我想只要學過程序設計的人都能把這樣一個程序作出來,但要是有程序員把這樣的程序交給用戶����,我只能用無語來評價�����,或許它真的能工作����,但...也只能如此了�����。
最合適的算法自然是使用HashTable(哈希表)����,先介紹介紹其中的基本知識����,所謂Hash��,一般是一個整數����,通過某種算法�����,可以把一個字符串"壓縮" 成一個整數����。當然����,無論如何,一個32位整數是無法對應回一個字符串的����,但在程序中��,兩個字符串計算出的Hash值相等的可能非常小,下面看看在MPQ中的Hash算法:
函數prepareCryptTable以下的函數生成一個長度為0x500(合10進制數:1280)的cryptTable[0x500]
- //函數prepareCryptTable以下的函數生成一個長度為0x500(合10進制數:1280)的cryptTable[0x500]
- void prepareCryptTable()
- {
- unsigned long seed = 0x00100001, index1 = 0, index2 = 0, i;
-
- for( index1 = 0; index1 < 0x100; index1++ )
- {
- for( index2 = index1, i = 0; i < 5; i++, index2 += 0x100 )
- {
- unsigned long temp1, temp2;
-
- seed = (seed * 125 + 3) % 0x2AAAAB;
- temp1 = (seed & 0xFFFF) << 0x10;
-
- seed = (seed * 125 + 3) % 0x2AAAAB;
- temp2 = (seed & 0xFFFF);
-
- cryptTable[index2] = ( temp1 | temp2 );
- }
- }
- }
函數HashString以下函數計算lpszFileName 字符串的hash值,其中dwHashType 為hash的類型,
- //函數HashString以下函數計算lpszFileName 字符串的hash值����,其中dwHashType 為hash的類型�����,
- unsigned long HashString(const char *lpszkeyName, unsigned long dwHashType )
- {
- unsigned char *key = (unsigned char *)lpszkeyName;
- unsigned long seed1 = 0x7FED7FED;
- unsigned long seed2 = 0xEEEEEEEE;
- int ch;
-
- while( *key != 0 )
- {
- ch = *key++;
- seed1 = cryptTable[(dwHashType<<8) + ch] ^ (seed1 + seed2);
- seed2 = ch + seed1 + seed2 + (seed2<<5) + 3;
- }
- return seed1;
- }
- typedef struct
- {
- int nHashA;
- int nHashB;
- char bExists;
- ......
- } SOMESTRUCTRUE;
- //一種可能的結構體定義?
- //函數GetHashTablePos下述函數為在Hash表中查找是否存在目標字符串����,有則返回要查找字符串的Hash值�����,無則,return -1.
- int GetHashTablePos( har *lpszString, SOMESTRUCTURE *lpTable )
- //lpszString要在Hash表中查找的字符串��,lpTable為存儲字符串Hash值的Hash表��。
- {
- int nHash = HashString(lpszString); //調用上述函數HashString�����,返回要查找字符串lpszString的Hash值。
- int nHashPos = nHash % nTableSize;
-
- if ( lpTable[nHashPos].bExists && !strcmp( lpTable[nHashPos].pString, lpszString ) )
- { //如果找到的Hash值在表中存在�����,且要查找的字符串與表中對應位置的字符串相同�����,
- return nHashPos; //返回找到的Hash值
- }
- else
- {
- return -1;
- }
- }
- //函數GetHashTablePos中,lpszString 為要在hash表中查找的字符串����;lpTable 為存儲字符串hash值的hash表����;nTableSize 為hash表的長度:
- int GetHashTablePos( char *lpszString, MPQHASHTABLE *lpTable, int nTableSize )
- {
- const int HASH_OFFSET = 0, HASH_A = 1, HASH_B = 2;
-
- int nHash = HashString( lpszString, HASH_OFFSET );
- int nHashA = HashString( lpszString, HASH_A );
- int nHashB = HashString( lpszString, HASH_B );
- int nHashStart = nHash % nTableSize;
- int nHashPos = nHashStart;
-
- while ( lpTable[nHashPos].bExists )
- {
- // 如果僅僅是判斷在該表中時候存在這個字符串��,就比較這兩個hash值就可以了�����,不用對結構體中的字符串進行比較。
- // 這樣會加快運行的速度����?減少hash表占用的空間�����?這種方法一般應用在什么場合?
- if ( lpTable[nHashPos].nHashA == nHashA
- && lpTable[nHashPos].nHashB == nHashB )
- {
- return nHashPos;
- }
- else
- {
- nHashPos = (nHashPos + 1) % nTableSize;
- }
-
- if (nHashPos == nHashStart)
- break;
- }
- return -1;
- }
上述程序解釋:
- 計算出字符串的三個哈希值(一個用來確定位置�����,另外兩個用來校驗)
- 察看哈希表中的這個位置
- 哈希表中這個位置為空嗎��?如果為空��,則肯定該字符串不存在����,返回-1����。
- 如果存在��,則檢查其他兩個哈希值是否也匹配�����,如果匹配,則表示找到了該字符串�����,返回其Hash值��。
- 移到下一個位置����,如果已經移到了表的末尾��,則反繞到表的開始位置起繼續查詢
- 看看是不是又回到了原來的位置����,如果是��,則返回沒找到
- 回到3��。
24.4、不重復Hash編碼
有了上面的暴雪Hash算法����。咱們的問題便可解決了。不過,有兩點必須先提醒讀者:1����、Hash表起初要初始化�����;2、暴雪的Hash算法對于查詢那樣處理可以,但對插入就不能那么解決。
關鍵主體代碼如下:
- //函數prepareCryptTable以下的函數生成一個長度為0x500(合10進制數:1280)的cryptTable[0x500]
- void prepareCryptTable()
- {
- unsigned long seed = 0x00100001, index1 = 0, index2 = 0, i;
-
- for( index1 = 0; index1 <0x100; index1++ )
- {
- for( index2 = index1, i = 0; i < 5; i++, index2 += 0x100)
- {
- unsigned long temp1, temp2;
- seed = (seed * 125 + 3) % 0x2AAAAB;
- temp1 = (seed & 0xFFFF)<<0x10;
- seed = (seed * 125 + 3) % 0x2AAAAB;
- temp2 = (seed & 0xFFFF);
- cryptTable[index2] = ( temp1 | temp2 );
- }
- }
- }
-
- //函數HashString以下函數計算lpszFileName 字符串的hash值,其中dwHashType 為hash的類型����,
- unsigned long HashString(const char *lpszkeyName, unsigned long dwHashType )
- {
- unsigned char *key = (unsigned char *)lpszkeyName;
- unsigned long seed1 = 0x7FED7FED;
- unsigned long seed2 = 0xEEEEEEEE;
- int ch;
-
- while( *key != 0 )
- {
- ch = *key++;
- seed1 = cryptTable[(dwHashType<<8) + ch] ^ (seed1 + seed2);
- seed2 = ch + seed1 + seed2 + (seed2<<5) + 3;
- }
- return seed1;
- }
-
- /////////////////////////////////////////////////////////////////////
- //function: 哈希詞典 編碼
- //parameter:
- //author: lei.zhou
- //time: 2011-12-14
- /////////////////////////////////////////////////////////////////////
- MPQHASHTABLE TestHashTable[nTableSize];
- int TestHashCTable[nTableSize];
- int TestHashDTable[nTableSize];
- key_list test_data[nTableSize];
-
- //直接調用上面的hashstring,nHashPos就是對應的HASH值。
- int insert_string(const char *string_in)
- {
- const int HASH_OFFSET = 0, HASH_C = 1, HASH_D = 2;
- unsigned int nHash = HashString(string_in, HASH_OFFSET);
- unsigned int nHashC = HashString(string_in, HASH_C);
- unsigned int nHashD = HashString(string_in, HASH_D);
- unsigned int nHashStart = nHash % nTableSize;
- unsigned int nHashPos = nHashStart;
- int ln, ires = 0;
-
- while (TestHashTable[nHashPos].bExists)
- {
- // if (TestHashCTable[nHashPos] == (int) nHashC && TestHashDTable[nHashPos] == (int) nHashD)
- // break;
- // //...
- // else
- //如之前所提示讀者的那般��,暴雪的Hash算法對于查詢那樣處理可以,但對插入就不能那么解決
- nHashPos = (nHashPos + 1) % nTableSize;
-
- if (nHashPos == nHashStart)
- break;
- }
-
- ln = strlen(string_in);
- if (!TestHashTable[nHashPos].bExists && (ln < nMaxStrLen))
- {
- TestHashCTable[nHashPos] = nHashC;
- TestHashDTable[nHashPos] = nHashD;
-
- test_data[nHashPos] = (KEYNODE *) malloc (sizeof(KEYNODE) * 1);
- if(test_data[nHashPos] == NULL)
- {
- printf("10000 EMS ERROR !!!!\n");
- return 0;
- }
-
- test_data[nHashPos]->pkey = (char *)malloc(ln+1);
- if(test_data[nHashPos]->pkey == NULL)
- {
- printf("10000 EMS ERROR !!!!\n");
- return 0;
- }
-
- memset(test_data[nHashPos]->pkey, 0, ln+1);
- strncpy(test_data[nHashPos]->pkey, string_in, ln);
- *((test_data[nHashPos]->pkey)+ln) = 0;
- test_data[nHashPos]->weight = nHashPos;
-
- TestHashTable[nHashPos].bExists = 1;
- }
- else
- {
- if(TestHashTable[nHashPos].bExists)
- printf("30000 in the hash table %s !!!\n", string_in);
- else
- printf("90000 strkey error !!!\n");
- }
- return nHashPos;
- }
接下來要讀取索引文件big_index對其中的關鍵詞進行編碼(為了簡單起見,直接一行一行掃描讀寫,沒有跳過行數了):
- void bigIndex_hash(const char *docpath, const char *hashpath)
- {
- FILE *fr, *fw;
- int len;
- char *pbuf, *p;
- char dockey[TERM_MAX_LENG];
-
- if(docpath == NULL || *docpath == '\0')
- return;
-
- if(hashpath == NULL || *hashpath == '\0')
- return;
-
- fr = fopen(docpath, "rb"); //讀取文件docpath
- fw = fopen(hashpath, "wb");
- if(fr == NULL || fw == NULL)
- {
- printf("open read or write file error!\n");
- return;
- }
-
- pbuf = (char*)malloc(BUFF_MAX_LENG);
- if(pbuf == NULL)
- {
- fclose(fr);
- return ;
- }
-
- memset(pbuf, 0, BUFF_MAX_LENG);
-
- while(fgets(pbuf, BUFF_MAX_LENG, fr))
- {
- len = GetRealString(pbuf);
- if(len <= 1)
- continue;
- p = strstr(pbuf, "#####");
- if(p != NULL)
- continue;
-
- p = strstr(pbuf, " ");
- if (p == NULL)
- {
- printf("file contents error!");
- }
-
- len = p - pbuf;
- dockey[0] = 0;
- strncpy(dockey, pbuf, len);
-
- dockey[len] = 0;
-
- int num = insert_string(dockey);
-
- dockey[len] = ' ';
- dockey[len+1] = '\0';
- char str[20];
- itoa(num, str, 10);
-
- strcat(dockey, str);
- dockey[len+strlen(str)+1] = '\0';
- fprintf (fw, "%s\n", dockey);
-
- }
- free(pbuf);
- fclose(fr);
- fclose(fw);
- }
主函數已經很簡單了�����,如下:
- int main()
- {
- prepareCryptTable(); //Hash表起初要初始化
-
- //現在要把整個big_index文件插入hash表��,以取得編碼結果
- bigIndex_hash("big_index.txt", "hashpath.txt");
- system("pause");
-
- return 0;
- }
程序運行后生成的hashpath.txt文件如下:

如上所示�����,采取暴雪的Hash算法并在插入的時候做適當處理,當再次對上文中的索引文件big_index進行Hash編碼后����,沖突問題已經得到初步解決����。當然�����,還有待更進一步更深入的測試。
后續添上數目索引1~10000...
后來又為上述文件中的關鍵詞編了碼一個計數的內碼�����,不過��,奇怪的是�����,同樣的代碼�����,在Dev C++ 與VS2010上運行結果卻不同(左邊dev上計數從"1"開始,VS上計數從“1994014002”開始)�����,如下圖所示:
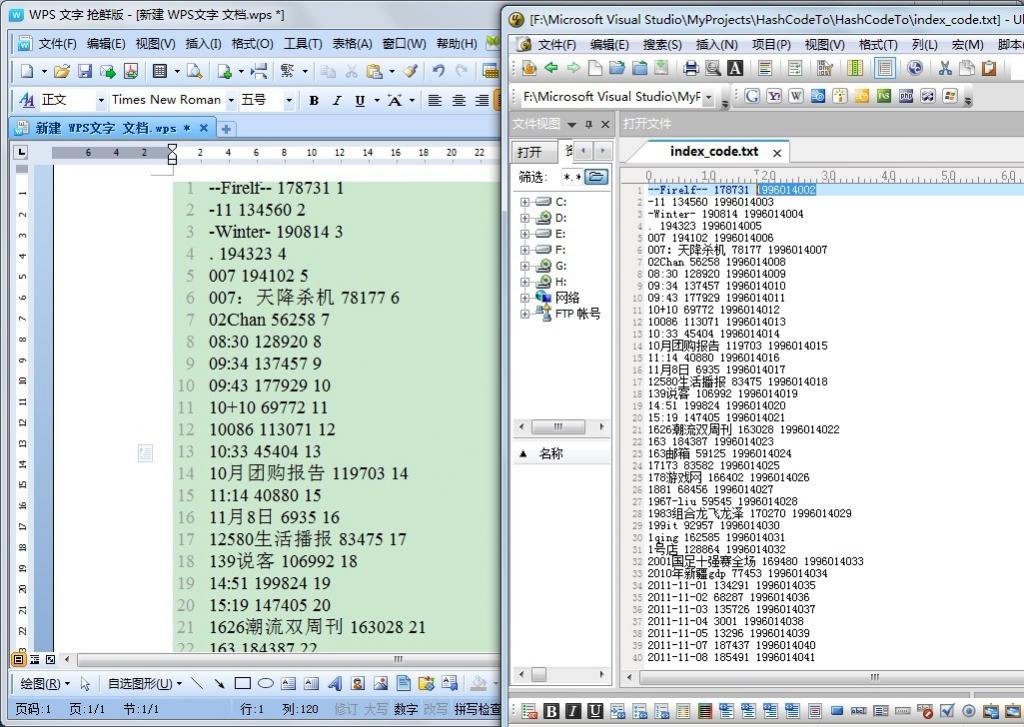
在上面的bigIndex_hashcode函數的基礎上����,修改如下,即可得到上面的效果:
- void bigIndex_hashcode(const char *in_file_path, const char *out_file_path)
- {
- FILE *fr, *fw;
- int len, value;
- char *pbuf, *pleft, *p;
- char keyvalue[TERM_MAX_LENG], str[WORD_MAX_LENG];
-
- if(in_file_path == NULL || *in_file_path == '\0') {
- printf("input file path error!\n");
- return;
- }
-
- if(out_file_path == NULL || *out_file_path == '\0') {
- printf("output file path error!\n");
- return;
- }
-
- fr = fopen(in_file_path, "r"); //讀取in_file_path路徑文件
- fw = fopen(out_file_path, "w");
-
- if(fr == NULL || fw == NULL)
- {
- printf("open read or write file error!\n");
- return;
- }
-
- pbuf = (char*)malloc(BUFF_MAX_LENG);
- pleft = (char*)malloc(BUFF_MAX_LENG);
- if(pbuf == NULL || pleft == NULL)
- {
- printf("allocate memory error!");
- fclose(fr);
- return ;
- }
-
- memset(pbuf, 0, BUFF_MAX_LENG);
-
- int offset = 1;
- while(fgets(pbuf, BUFF_MAX_LENG, fr))
- {
- if (--offset > 0)
- continue;
-
- if(GetRealString(pbuf) <= 1)
- continue;
-
- p = strstr(pbuf, "#####");
- if(p != NULL)
- continue;
-
- p = strstr(pbuf, " ");
- if (p == NULL)
- {
- printf("file contents error!");
- }
-
- len = p - pbuf;
-
- // 確定跳過行數
- strcpy(pleft, p+1);
- offset = atoi(pleft) + 1;
-
- strncpy(keyvalue, pbuf, len);
- keyvalue[len] = '\0';
- value = insert_string(keyvalue);
-
- if (value != -1) {
-
- // key value中插入空格
- keyvalue[len] = ' ';
- keyvalue[len+1] = '\0';
-
- itoa(value, str, 10);
- strcat(keyvalue, str);
-
- keyvalue[len+strlen(str)+1] = ' ';
- keyvalue[len+strlen(str)+2] = '\0';
-
- keysize++;
- itoa(keysize, str, 10);
- strcat(keyvalue, str);
-
- // 將key value寫入文件
- fprintf (fw, "%s\n", keyvalue);
-
- }
- }
- free(pbuf);
- fclose(fr);
- fclose(fw);
- }
小結
本文有一點值得一提的是��,在此前的這篇文章(十一����、從頭到尾徹底解析Hash表算法)之中,只是對Hash表及暴雪的Hash算法有過學習和了解,但尚未真正運用過它�����,而今在本章中體現�����,證明還是之前寫的文章,及之前對Hash表等算法的學習還是有一定作用的��。同時��,也順便對暴雪的Hash函數算是做了個測試�����,其的確能解決一般的沖突性問題,創造這個算法的人不簡單吶��。
后記
再次感謝老大xiaoqi�����,以及藝術室內朋友xiaolin��,555,yansha的指導�����。沒有他們的幫助����,我將寸步難行。日后��,自己博客內的文章要經?���;仡櫍煤皿w會����。同時,寫作本文時,剛接觸倒排索引等相關問題不久�����,若有任何問題�����,歡迎隨時交流或批評指正����。謝謝��。完����。