程序員編程藝術(shù):第三章、尋找最小的k個數(shù)
作者:July。
時間:二零一一年四月二十八日。
致謝:litaoye, strugglever,yansha,luuillu,Sorehead,及狂想曲創(chuàng)作組。
微博:http://weibo.com/julyweibo。
出處:http://blog.csdn.net/v_JULY_v。
----------------------------------
前奏
@July_____:1、當(dāng)年明月:“我寫文章有個習(xí)慣,由于早年讀了太多學(xué)究書,所以很痛恨那些故作高深的文章,其實歷史本身很精彩,所有的歷史都可以寫得很好看,...。”2、IT技術(shù)文章,亦是如此,可以寫得很通俗,很有趣,而非故作高深。希望,我可以做到。
下面,我試圖用最清晰易懂,最易令人理解的思維或方式闡述有關(guān)尋找最小的k個數(shù)這個問題(這幾天一直在想,除了計數(shù)排序外,這題到底還有沒有其它的O(n)的算法? )。希望,有任何問題,歡迎不吝指正。謝謝。
尋找最小的k個數(shù)
題目描述:5.查找最小的k個元素
題目:輸入n個整數(shù),輸出其中最小的k個。
例如輸入1,2,3,4,5,6,7和8這8個數(shù)字,則最小的4個數(shù)字為1,2,3和4。
第一節(jié)、各種思路,各種選擇
0、 咱們先簡單的理解,要求一個序列中最小的k個數(shù),按照慣有的思維方式,很簡單,先對這個序列從小到大排序,然后輸出前面的最小的k個數(shù)即可。
1、 至于選取什么的排序方法,我想你可能會第一時間想到快速排序,我們知道,快速排序平均所費時間為n*logn,然后再遍歷序列中前k個元素輸出,即可,總的時間復(fù)雜度為O(n*logn+k)=O(n*logn)。
2、 咱們再進一步想想,題目并沒有要求要查找的k個數(shù),甚至后n-k個數(shù)是有序的,既然如此,咱們又何必對所有的n個數(shù)都進行排序列?
這時,咱們想到了用選擇或交換排序,即遍歷n個數(shù),先把最先遍歷到得k個數(shù)存入大小為k的數(shù)組之中,對這k個數(shù),利用選擇或交換排序,找到k個數(shù)中的最大數(shù)kmax(kmax設(shè)為k個元素的數(shù)組中最大元素),用時O(k)(你應(yīng)該知道,插入或選擇排序查找操作需要O(k)的時間),后再繼續(xù)遍歷后n-k個數(shù),x與kmax比較:如果x<kmax,則x代替kmax,并再次重新找出k個元素的數(shù)組中最大元素kmax‘(多謝kk791159796 提醒修正);如果x>kmax,則不更新數(shù)組。這樣,每次更新或不更新數(shù)組的所用的時間為O(k)或O(0),整趟下來,總的時間復(fù)雜度平均下來為:n*O(k)=O(n*k)。
3、 當(dāng)然,更好的辦法是維護k個元素的最大堆,原理與上述第2個方案一致,即用容量為k的最大堆存儲最先遍歷到的k個數(shù),并假設(shè)它們即是最小的k個數(shù),建堆費時O(k)后,有k1<k2<...<kmax(kmax設(shè)為大頂堆中最大元素)。繼續(xù)遍歷數(shù)列,每次遍歷一個元素x,與堆頂元素比較,x<kmax,更新堆(用時logk),否則不更新堆。這樣下來,總費時O(k+(n-k)*logk)=O(n*logk)。此方法得益于在堆中,查找等各項操作時間復(fù)雜度均為logk(不然,就如上述思路2所述:直接用數(shù)組也可以找出前k個小的元素,用時O(n*k))。
4、 按編程之美第141頁上解法二的所述,類似快速排序的劃分方法,N個數(shù)存儲在數(shù)組S中,再從數(shù)組中隨機選取一個數(shù)X(隨機選取樞紐元,可做到線性期望時間O(N)的復(fù)雜度,在第二節(jié)論述),把數(shù)組劃分為Sa和Sb倆部分,Sa<=X<=Sb,如果要查找的k個元素小于Sa的元素個數(shù),則返回Sa中較小的k個元素,否則返回Sa中k個小的元素+Sb中小的k-|Sa|個元素。像上述過程一樣,這個運用類似快速排序的partition的快速選擇SELECT算法尋找最小的k個元素,在最壞情況下亦能做到O(N)的復(fù)雜度。不過值得一提的是,這個快速選擇SELECT算法是選取數(shù)組中“中位數(shù)的中位數(shù)”作為樞紐元,而非隨機選取樞紐元。
5、 RANDOMIZED-SELECT,每次都是隨機選取數(shù)列中的一個元素作為主元,在0(n)的時間內(nèi)找到第k小的元素,然后遍歷輸出前面的k個小的元素。 如果能的話,那么總的時間復(fù)雜度為線性期望時間:O(n+k)=O(n)(當(dāng)k比較小時)。
Ok,稍后第二節(jié)中,我會具體給出RANDOMIZED-SELECT(A, p, r, i)的整體完整偽碼。在此之前,要明確一個問題:我們通常所熟知的快速排序是以固定的第一個或最后一個元素作為主元,每次遞歸劃分都是不均等的,最后的平均時間復(fù)雜度為:O(n*logn),但RANDOMIZED-SELECT與普通的快速排序不同的是,每次遞歸都是隨機選擇序列從第一個到最后一個元素中任一一個作為主元。
6、 線性時間的排序,即計數(shù)排序,時間復(fù)雜度雖能達到O(n),但限制條件太多,不常用。
7、 updated: huaye502在本文的評論下指出:“可以用最小堆初始化數(shù)組,然后取這個優(yōu)先隊列前k個值。復(fù)雜度O(n)+k*O(log n)”。huaye502的意思是針對整個數(shù)組序列建最小堆,建堆所用時間為O(n)(算法導(dǎo)論一書上第6章第6.3節(jié)已經(jīng)論證,在線性時間內(nèi),能將一個無序的數(shù)組建成一個最小堆),然后取堆中的前k個數(shù),總的時間復(fù)雜度即為:O(n+k*logn)。
關(guān)于上述第7點思路的繼續(xù)闡述:至于思路7的O(n+k*logn)是否小于上述思路3的O(n*logk),即O(n+k*logn)?< O(n*logk)。粗略數(shù)學(xué)證明可參看如下第一幅圖,我們可以這么解決:當(dāng)k是常數(shù),n趨向于無窮大時,求(n*logk)/(n+k*logn)的極限T,如果T>1,那么可得O(n*logk)>O(n+k*logn),也就是O(n+k*logn)< O(n*logk)。雖然這有違我們慣常的思維,然事實最終證明的確如此,這個極值T=logk>1,即采取建立n個元素的最小堆后取其前k個數(shù)的方法的復(fù)雜度小于采取常規(guī)的建立k個元素最大堆后通過比較尋找最小的k個數(shù)的方法的復(fù)雜度。但,最重要的是,如果建立n個元素的最小堆的話,那么其空間復(fù)雜度勢必為O(N),而建立k個元素的最大堆的空間復(fù)雜度為O(k)。所以,綜合考慮,我們一般還是選擇用建立k個元素的最大堆的方法解決此類尋找最小的k個數(shù)的問題。
也可以如gbb21所述粗略證明:要證原式k+n*logk-n-k*logn>0,等價于證(logk-1)n-k*logn+k>0。當(dāng)when n -> +/inf(n趨向于正無窮大)時,logk-1-0-0>0,即只要滿足logk-1>0即可。原式得證。即O(k+n*logk)>O(n+k*logn) =>O(n+k*logn)< O(n*logk),與上面得到的結(jié)論一致。
事實上,是建立最大堆還是建立最小堆,其實際的程序運行時間相差并不大,運行時間都在一個數(shù)量級上。因為后續(xù),我們還專門寫了個程序進行測試,即針對1000w的數(shù)據(jù)尋找其中最小的k個數(shù)的問題,采取兩種實現(xiàn),一是采取常規(guī)的建立k個元素最大堆后通過比較尋找最小的k個數(shù)的方案,一是采取建立n個元素的最小堆,然后取其前k個數(shù)的方法,發(fā)現(xiàn)兩相比較,運行時間實際上相差無幾。結(jié)果可看下面的第二幅圖。

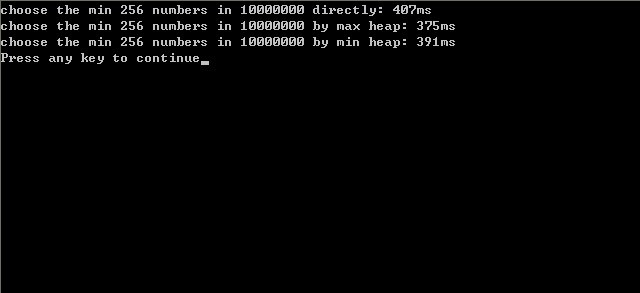
updated:
經(jīng)過和幾個朋友的討論,已經(jīng)證實,上述思路7lingyun310所述的思路應(yīng)該是完全可以的。下面,我來具體解釋下他的這種方法。
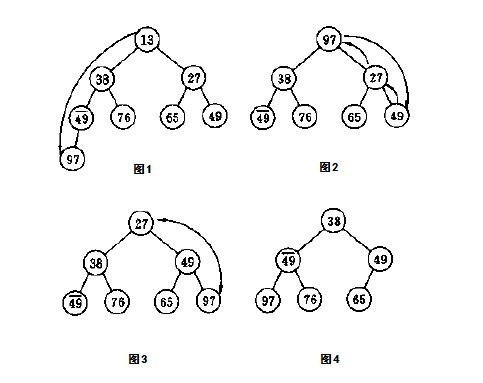
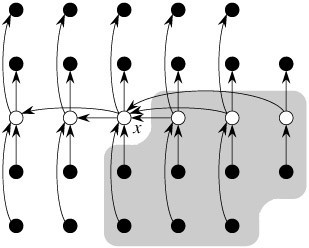
我們知道,n個元素的最小堆中,可以先取出堆頂元素得到我們第1小的元素,然后把堆中最后一個元素(較大的元素)上移至堆頂,成為新的堆頂元素(取出堆頂元素之后,把堆中下面的最后一個元素送到堆頂?shù)倪^程可以參考下面的第一幅圖。至于為什么是怎么做,為什么是把最后一個元素送到堆頂成為堆頂元素,而不是把原來堆頂元素的兒子送到堆頂呢?具體原因可參考相關(guān)書籍)。
此時,堆的性質(zhì)已經(jīng)被破壞了,所以此后要調(diào)整堆。怎么調(diào)整呢?就是一般人所說的針對新的堆頂元素shiftdown,逐步下移(因為新的堆頂元素由最后一個元素而來,比較大嘛,既然是最小堆,當(dāng)然大的元素就要下沉到堆的下部了)。下沉多少步呢?即如lingyun310所說的,下沉k次就足夠了。
下移k次之后,此時的堆頂元素已經(jīng)是我們要找的第2小的元素。然后,取出這個第2小的元素(堆頂元素),再次把堆中的最后一個元素送到堆頂,又經(jīng)過k-1次下移之后(此后下移次數(shù)逐步減少,k-2,k-3,...k=0后算法中斷)....,如此重復(fù)k-1趟操作,不斷取出的堆頂元素即是我們要找的最小的k個數(shù)。雖然上述算法中斷后整個堆已經(jīng)不是最小堆了,但是求得的k個最小元素已經(jīng)滿足我們題目所要求的了,就是說已經(jīng)找到了最小的k個數(shù),那么其它的咱們不管了。
我可以再舉一個形象易懂的例子。你可以想象在一個水桶中,有很多的氣泡,這些氣泡從上到下,總體的趨勢是逐漸增大的,但卻不是嚴(yán)格的逐次大(正好這也符合最小堆的性質(zhì))。ok,現(xiàn)在我們?nèi)〕龅谝粋€氣泡,那這個氣泡一定是水桶中所有氣泡中最小的,把它取出來,然后把最下面的那個大氣泡(但不一定是最大的氣泡)移到最上面去,此時違反了氣泡從上到下總體上逐步變大的趨勢,所以,要把這個大氣泡往下沉,下沉到哪個位置呢?就是下沉k次。下沉k次后,最上面的氣泡已經(jīng)肯定是最小的氣泡了,把他再次取出。然后又將最下面最后的那個氣泡移至最上面,移到最上面后,再次讓它逐次下沉,下沉k-1次...,如此循環(huán)往復(fù),最終取到最小的k個氣泡。
ok,所以,上面方法所述的過程,更進一步來說,其實是第一趟調(diào)整保持第0層到第k層是最小堆,第二趟調(diào)整保持第0層到第k-1層是最小堆...,依次類推。但這個思路只是下述思路8中正規(guī)的最小堆算法(因為它最終對全部元素都進行了調(diào)整,算法結(jié)束后,整個堆還是一個最小堆)的調(diào)優(yōu),時間復(fù)雜度O(n+k^2)沒有量級的提高,空間復(fù)雜度為O(N)也不會減少。
原理理解透了,那么寫代碼,就不難了,完整粗略代碼如下(有問題煩請批評指正):
- //copyright@ 泡泡魚
- //July、2010.06.02。
-
- //@lingyun310:先對元素數(shù)組原地建最小堆,O(n)。然后提取K次,但是每次提取時,
- //換到頂部的元素只需要下移頂多k次就足夠了,下移次數(shù)逐次減少。此種方法的復(fù)雜度為O(n+k^2)。
- #include <stdio.h>
- #include <stdlib.h>
- #define MAXLEN 123456
- #define K 100
-
- //
- void HeapAdjust(int array[], int i, int Length)
- {
- int child,temp;
- for(temp=array[i];2*i+1<Length;i=child)
- {
- child = 2*i+1;
- if(child<Length-1 && array[child+1]<array[child])
- child++;
- if (temp>array[child])
- array[i]=array[child];
- else
- break;
- array[child]=temp;
- }
- }
-
- void Swap(int* a,int* b)
- {
- *a=*a^*b;
- *b=*a^*b;
- *a=*a^*b;
- }
-
- int GetMin(int array[], int Length,int k)
- {
- int min=array[0];
- Swap(&array[0],&array[Length-1]);
-
- int child,temp;
- int i=0,j=k-1;
- for (temp=array[0]; j>0 && 2*i+1<Length; --j,i=child)
- {
- child = 2*i+1;
- if(child<Length-1 && array[child+1]<array[child])
- child++;
- if (temp>array[child])
- array[i]=array[child];
- else
- break;
- array[child]=temp;
- }
-
- return min;
- }
-
- void Kmin(int array[] , int Length , int k)
- {
- for(int i=Length/2-1;i>=0;--i)
- //初始建堆,時間復(fù)雜度為O(n)
- HeapAdjust(array,i,Length);
-
- int j=Length;
- for(i=k;i>0;--i,--j)
- //k次循環(huán),每次循環(huán)的復(fù)雜度最多為k次交換,復(fù)雜度為o(k^2)
- {
- int min=GetMin(array,j,i);
- printf("%d,", min);
- }
- }
-
- int main()
- {
- int array[MAXLEN];
- for(int i=MAXLEN;i>0;--i)
- array[MAXLEN-i] = i;
-
- Kmin(array,MAXLEN,K);
- return 0;
- }
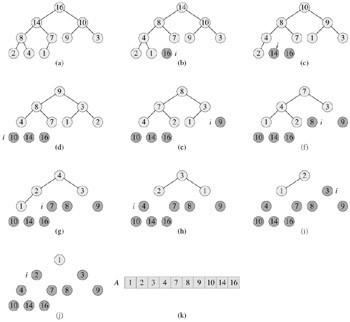
在算法導(dǎo)論第6章有下面這樣一張圖,因為開始時曾一直糾結(jié)過這個問題,“取出堆頂元素之后,把堆中下面的最后一個元素送到堆頂”。因為算法導(dǎo)論上下面這張圖給了我一個假象,從a)->b)中,讓我誤以為是取出堆頂元素之后,是把原來堆頂元素的兒子送到堆頂。而事實上不是這樣的。因為在下面的圖中,16被刪除后,堆中最后一個元素1代替16成為根結(jié)點,然后1下沉(注意下圖所示的過程是最大堆的堆排序過程,不再是上面的最小堆了,所以小的元素當(dāng)然要下移),14上移到堆頂。所以,圖中小圖圖b)是已經(jīng)在小圖a)之和被調(diào)整過的最大堆了,只是調(diào)整了logn次,非上面所述的k次。
ok,接下來,咱們再著重分析下上述思路4。或許,你不會相信上述思路4的觀點,但我馬上將用事實來論證我的觀點。這幾天,我一直在想,也一直在找資料查找類似快速排序的partition過程的分治算法(即上述在編程之美上提到的第4點思路),是否能做到O(N)的論述或證明,
然找了三天,不但在算法導(dǎo)論上找到了RANDOMIZED-SELECT,在平均情況下為線性期望時間O(N)的論證(請參考本文第二節(jié)),還在mark allen weiss所著的數(shù)據(jù)結(jié)構(gòu)與算法分析--c語言描述一書(還得多謝朋友sheguang提醒)中,第7章第7.7.6節(jié)(本文下面的第4節(jié)末,也有關(guān)此問題的闡述)也找到了在最壞情況下,為線性時間O(N)(是的,不含期望,是最壞情況下為O(N))的快速選擇算法(此算法,本文文末,也有闡述),請看下述文字(括號里的中文解釋為本人添加):
Quicksort can be modified to solve the selection problem, which we have seen in chapters 1 and 6. Recall that by using a priority queue, we can find the kth largest (or smallest) element in O(n + k log n)(即上述思路7). For the special case of finding the median, this gives an O(n log n) algorithm.
Since we can sort the file in O(nlog n) time, one might expect to obtain a better time bound for selection. The algorithm we present to find the kth smallest element in a set S is almost identical to quicksort. In fact, the first three steps are the same. We will call this algorithm quickselect(叫做快速選擇). Let |Si| denote the number of elements in Si(令|Si|為Si中元素的個數(shù)). The steps of quickselect are(快速選擇,即上述編程之美一書上的,思路4,步驟如下):
1. If |S| = 1, then k = 1 and return the elements in S as the answer. If a cutoff for small files is being used and |S| <=CUTOFF, then sort S and return the kth smallest element.
2. Pick a pivot element, v (- S.(選取一個樞紐元v屬于S)
3. Partition S - {v} into S1 and S2, as was done with quicksort.
(將集合S-{v}分割成S1和S2,就像我們在快速排序中所作的那樣)
4. If k <= |S1|, then the kth smallest element must be in S1. In this case, return quickselect (S1, k). If k = 1 + |S1|, then the pivot is the kth smallest element and we can return it as the answer. Otherwise, the kth smallest element lies in S2, and it is the (k - |S1| - 1)st smallest element in S2. We make a recursive call and return quickselect (S2, k - |S1| - 1).
(如果k<=|S1|,那么第k個最小元素必然在S1中。在這種情況下,返回quickselect(S1,k)。如果k=1+|S1|,那么樞紐元素就是第k個最小元素,即找到,直接返回它。否則,這第k個最小元素就在S2中,即S2中的第(k-|S1|-1)(多謝王洋提醒修正)個最小元素,我們遞歸調(diào)用并返回quickselect(S2,k-|S1|-1))。
In contrast to quicksort, quickselect makes only one recursive call instead of two. The worst case of quickselect is identical to that of quicksort and is O(n2). Intuitively, this is because quicksort's worst case is when one of S1 and S2 is empty; thus, quickselect(快速選擇) is not really saving a recursive call. The average running time, however, is O(n)(不過,其平均運行時間為O(N)。看到了沒,就是平均復(fù)雜度為O(N)這句話). The analysis is similar to quicksort's and is left as an exercise.
The implementation of quickselect is even simpler than the abstract description might imply. The code to do this shown in Figure 7.16. When the algorithm terminates, the kth smallest element is in position k. This destroys the original ordering; if this is not desirable, then a copy must be made.
并給出了代碼示例:
- //copyright@ mark allen weiss
- //July、updated,2011.05.05凌晨.
-
- //q_select places the kth smallest element in a[k]
- void q_select( input_type a[], int k, int left, int right )
- {
- int i, j;
- input_type pivot;
- if( left + CUTOFF <= right )
- {
- pivot = median3( a, left, right );
- //取三數(shù)中值作為樞紐元,可以消除最壞情況而保證此算法是O(N)的。不過,這還只局限在理論意義上。
- //稍后,除了下文的第二節(jié)的隨機選取樞紐元,在第四節(jié)末,您將看到另一種選取樞紐元的方法。
-
- i=left; j=right-1;
- for(;;)
- {
- while( a[++i] < pivot );
- while( a[--j] > pivot );
- if (i < j )
- swap( &a[i], &a[j] );
- else
- break;
- }
- swap( &a[i], &a[right-1] ); /* restore pivot */
- if( k < i)
- q_select( a, k, left, i-1 );
- else
- if( k > i )
- q-select( a, k, i+1, right );
- }
- else
- insert_sort(a, left, right );
- }
- 與快速排序相比,快速選擇只做了一次遞歸調(diào)用而不是兩次。快速選擇的最壞情況和快速排序的相同,也是O(N^2),最壞情況發(fā)生在樞紐元的選取不當(dāng),以致S1,或S2中有一個序列為空。
- 這就好比快速排序的運行時間與劃分是否對稱有關(guān),劃分的好或?qū)ΨQ,那么快速排序可達最佳的運行時間O(n*logn),劃分的不好或不對稱,則會有最壞的運行時間為O(N^2)。而樞紐元的選取則完全決定快速排序的partition過程是否劃分對稱。
- 快速選擇也是一樣,如果樞紐元的選取不當(dāng),則依然會有最壞的運行時間為O(N^2)的情況發(fā)生。那么,怎么避免這個最壞情況的發(fā)生,或者說就算是最壞情況下,亦能保證快速選擇的運行時間為O(N)列?對了,關(guān)鍵,還是看你的樞紐元怎么選取。
- 像上述程序使用三數(shù)中值作為樞紐元的方法可以使得最壞情況發(fā)生的概率幾乎可以忽略不計。然而,稍后,在本文第四節(jié)末,及本文文末,您將看到:通過一種更好的方法,如“五分化中項的中項”,或“中位數(shù)的中位數(shù)”等方法選取樞紐元,我們將能徹底保證在最壞情況下依然是線性O(shè)(N)的復(fù)雜度。
至于編程之美上所述:從數(shù)組中隨機選取一個數(shù)X,把數(shù)組劃分為Sa和Sb倆部分,那么這個問題就轉(zhuǎn)到了下文第二節(jié)RANDOMIZED-SELECT,以線性期望時間做選擇,無論如何,編程之美上的解法二的復(fù)雜度為O(n*logk)都是有待商榷的。至于最壞情況下一種全新的,為O(N)的快速選擇算法,直接跳轉(zhuǎn)到本文第四節(jié)末,或文末部分吧)。
不過,為了公正起見,把編程之美第141頁上的源碼貼出來,由大家來評判:
- Kbig(S, k):
- if(k <= 0):
- return [] // 返回空數(shù)組
- if(length S <= k):
- return S
- (Sa, Sb) = Partition(S)
- return Kbig(Sa, k).Append(Kbig(Sb, k – length Sa)
-
- Partition(S):
- Sa = [] // 初始化為空數(shù)組
- Sb = [] // 初始化為空數(shù)組
- Swap(s[1], S[Random()%length S]) // 隨機選擇一個數(shù)作為分組標(biāo)準(zhǔn),以
- // 避免特殊數(shù)據(jù)下的算法退化,也可
- // 以通過對整個數(shù)據(jù)進行洗牌預(yù)處理
- // 實現(xiàn)這個目的
- p = S[1]
- for i in [2: length S]:
- S[i] > p ? Sa.Append(S[i]) : Sb.Append(S[i])
- // 將p加入較小的組,可以避免分組失敗,也使分組
- // 更均勻,提高效率
- length Sa < length Sb ? Sa.Append(p) : Sb.Append(p)
- return (Sa, Sb)
你已經(jīng)看到,它是隨機選取數(shù)組中的任一元素為樞紐的,這就是本文下面的第二節(jié)RANDOMIZED-SELECT的問題了,只是要修正的是,此算法的平均時間復(fù)雜度為線性期望O(N)的時間。而,稍后在本文的第四節(jié)或本文文末,您還將會看到此問題的進一步闡述(SELECT算法,即快速選擇算法),此SELECT算法能保證即使在最壞情況下,依然是線性O(shè)(N)的復(fù)雜度。
updated:
1、為了照顧手中沒編程之美這本書的friends,我拍了張照片,現(xiàn)貼于下供參考(提醒:1、書上為尋找最大的k個數(shù),而我們面對的問題是尋找最小的k個數(shù),兩種形式,一個本質(zhì)(該修改的地方,上文已經(jīng)全部修改)。2、書中描述與上文思路4并無原理性出入,不過,勿被圖中記的筆記所誤導(dǎo),因為之前也曾被書中的這個n*logk復(fù)雜度所誤導(dǎo)過。ok,相信,看完本文后,你不會再有此疑惑):

2、同時,在編程之美原書上此節(jié)的解法五的開頭提到,“上面類似快速排序的方法平均時間復(fù)雜度是線性的”,我想上面的類似快速排序的方法,應(yīng)該是指解法(即如上所述的類似快速排序partition過程的方法),但解法二得出的平均時間復(fù)雜度卻為O(N*logk),明擺著前后矛盾(參見下圖)。

3、此文創(chuàng)作后的幾天,已把本人的意見反饋給鄒欣等人,下面是編程之美bop1的改版修訂地址的頁面截圖(本人也在參加其改版修訂的工作),下面的文字是我的記錄(同時,本人聲明,此狂想曲系列文章系我個人獨立創(chuàng)作,與其它的事不相干):

第二節(jié)、Randomized-Select,線性期望時間
下面是RANDOMIZED-SELECT(A, p, r)完整偽碼(來自算法導(dǎo)論),我給了注釋,或許能給你點啟示。在下結(jié)論之前,我還需要很多的時間去思量,以確保結(jié)論之完整與正確。
PARTITION(A, p, r) //partition過程 p為第一個數(shù),r為最后一個數(shù)
1 x ← A[r] //以最后一個元素作為主元
2 i ← p - 1
3 for j ← p to r - 1
4 do if A[j] ≤ x
5 then i ← i + 1
6 exchange A[i] <-> A[j]
7 exchange A[i + 1] <-> A[r]
8 return i + 1
RANDOMIZED-PARTITION(A, p, r) //隨機快排的partition過程
1 i ← RANDOM(p, r) //i 隨機取p到r中個一個值
2 exchange A[r] <-> A[i] //以隨機的 i作為主元
3 return PARTITION(A, p, r) //調(diào)用上述原來的partition過程
RANDOMIZED-SELECT(A, p, r, i) //以線性時間做選擇,目的是返回數(shù)組A[p..r]中的第i 小的元素
1 if p = r //p=r,序列中只有一個元素
2 then return A[p]
3 q ← RANDOMIZED-PARTITION(A, p, r) //隨機選取的元素q作為主元
4 k ← q - p + 1 //k表示子數(shù)組 A[p…q]內(nèi)的元素個數(shù),處于劃分低區(qū)的元素個數(shù)加上一個主元元素
5 if i == k //檢查要查找的i 等于子數(shù)組中A[p....q]中的元素個數(shù)k
6 then return A[q] //則直接返回A[q]
7 else if i < k
8 then return RANDOMIZED-SELECT(A, p, q - 1, i)
//得到的k 大于要查找的i 的大小,則遞歸到低區(qū)間A[p,q-1]中去查找
9 else return RANDOMIZED-SELECT(A, q + 1, r, i - k)
//得到的k 小于要查找的i 的大小,則遞歸到高區(qū)間A[q+1,r]中去查找。
寫此文的目的,在于起一個拋磚引玉的作用。希望,能引起你的重視及好的思路,直到有個徹底明白的結(jié)果。
updated:算法導(dǎo)論原英文版有關(guān)于RANDOMIZED-SELECT(A, p, r)為O(n)的證明。為了一個徹底明白的闡述,我現(xiàn)將其原文的證明自個再翻譯加工后,闡述如下:
此RANDOMIZED-SELECT最壞情況下時間復(fù)雜度為Θ(n2),即使是要選擇最小元素也是如此,因為在劃分時可能極不走運,總是按余下元素中的最大元素進行劃分,而劃分操作需要O(n)的時間。
然而此算法的平均情況性能極好,因為它是隨機化的,故沒有哪一種特別的輸入會導(dǎo)致其最壞情況的發(fā)生。
算法導(dǎo)論上,針對此RANDOMIZED-SELECT算法平均時間復(fù)雜度為O(n)的證明,引用如下,或許,能給你我多點的啟示(本來想直接引用第二版中文版的翻譯文字,但在中英文對照閱讀的情況下,發(fā)現(xiàn)第二版中文版的翻譯實在不怎么樣,所以,得自己一個一個字的敲,最終敲完修正如下),分4步證明:
1、當(dāng)RANDOMIZED-SELECT作用于一個含有n個元素的輸入數(shù)組A[p ..r]上時,所需時間是一個隨機變量,記為T(n),我們可以這樣得到線性期望值E [T(n)]的下界:程序RANDOMIZED-PARTITION會以等同的可能性返回數(shù)組中任何一個元素為主元,因此,對于每一個k,(1 ≤k ≤n),子數(shù)組A[p ..q]有k個元素,它們?nèi)啃∮诨虻扔谥髟氐母怕蕿?/n.對k = 1, 2,...,n,我們定指示器Xk,為:
Xk = I{子數(shù)組A[p ..q]恰有k個元素} ,
我們假定元素的值不同,因此有
E[Xk]=1/n
當(dāng)調(diào)用RANDOMIZED-SELECT并且選擇A[q]作為主元元素的時候,我們事先不知道是否會立即找到我們所想要的第i小的元素,因為,我們很有可能需要在子數(shù)組A[p ..q - 1], 或A[q + 1 ..r]上遞歸繼續(xù)進行尋找.具體在哪一個子數(shù)組上遞歸尋找,視第i小的元素與A[q]的相對位置而定.
2、假設(shè)T(n)是單調(diào)遞增的,我們可以將遞歸所需時間的界限限定在輸入數(shù)組時可能輸入的所需遞歸調(diào)用的最大時間(此句話,原中文版的翻譯也是有問題的).換言之,我們斷定,為得到一個上界,我們假定第i小的元素總是在劃分的較大的一邊,對一個給定的RANDOMIZED-SELECT,指示器Xk剛好在一個k值上取1,在其它的k值時,都是取0.當(dāng)Xk =1時,可能要遞歸處理的倆個子數(shù)組的大小分別為k-1,和n-k,因此可得到遞歸式為
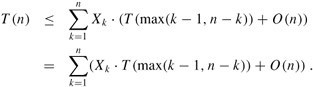
取期望值為:
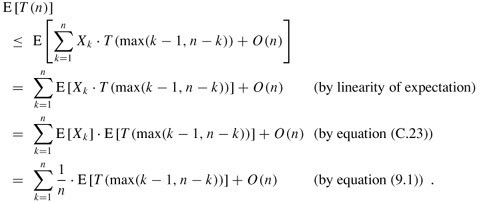
為了能應(yīng)用等式(C.23),我們依賴于Xk和T(max(k - 1,n - k))是獨立的隨機變量(這個可以證明,證明此處略)。
3、下面,我們來考慮下表達式max(k - 1,n -k)的結(jié)果.我們有:
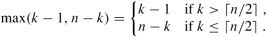
如果n是偶數(shù),從T(⌉)到T(n - 1)每個項在總和中剛好出現(xiàn)倆次,T(⌋)出現(xiàn)一次。因此,有

我們可以用替換法來解上面的遞歸式。假設(shè)對滿足這個遞歸式初始條件的某個常數(shù)c,有T(n) ≤cn。我們假設(shè)對于小于某個常數(shù)c(稍后再來說明如何選取這個常數(shù))的n,有T(n) =O(1)。 同時,還要選擇一個常數(shù)a,使得對于所有的n>0,由上式中O(n)項(用來描述這個算法的運行時間中非遞歸的部分)所描述的函數(shù),可由an從上方限界得到(這里,原中文版的翻譯的確是有點含糊)。利用這個歸納假設(shè),可以得到:
(此段原中文版翻譯有點問題,上述文字已經(jīng)修正過來,對應(yīng)的此段原英文為:We solve the recurrence by substitution. Assume thatT(n)≤cn for some constant c that satisfies the initial conditions of the recurrence. We assume thatT(n) =O(1) forn less than some constant; we shall pick this constant later. We also pick a constanta such that the function described by theO(n) term above (which describes the non-recursive component of the running time of the algorithm) is bounded from above byan for alln> 0. Using this inductive hypothesis, we have)
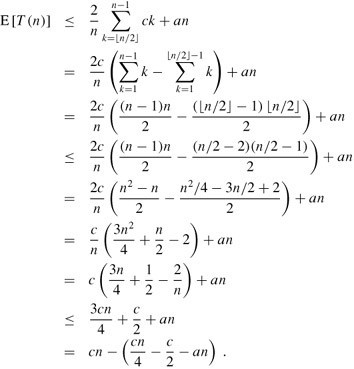
4、為了完成證明,還需要證明對足夠大的n,上面最后一個表達式最大為cn,即要證明:cn/4 -c/2 -an ≥ 0.如果在倆邊加上c/2,并且提取因子n,就可以得到n(c/4 -a) ≥c/2.只要我們選擇的常數(shù)c能滿足c/4 -a > 0, i.e.,即c > 4a,我們就可以將倆邊同時除以c/4 -a, 最終得到:
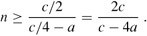
綜上,如果假設(shè)對n < 2c/(c -4a),有T(n) =O(1),我們就能得到E[T(n)] =O(n)。所以,最終我們可以得出這樣的結(jié)論,并確認(rèn)無疑:在平均情況下,任何順序統(tǒng)計量(特別是中位數(shù))都可以在線性時間內(nèi)得到。
結(jié)論: 如你所見,RANDOMIZED-SELECT有線性期望時間O(N)的復(fù)雜度,但此RANDOMIZED-SELECT算法在最壞情況下有O(N^2)的復(fù)雜度。所以,我們得找出一種在最壞情況下也為線性時間的算法。稍后,在本文的第四節(jié)末,及本文文末部分,你將看到一種在最壞情況下是線性時間O(N)的復(fù)雜度的快速選擇SELECT算法。
第三節(jié)、各執(zhí)己見,百家爭鳴
updated :本文昨晚發(fā)布后,現(xiàn)在朋友們之間,主要有以下幾種觀點(在徹底弄清之前,最好不要下結(jié)論):
luuillu:我不認(rèn)為隨機快排比直接快排的時間復(fù)雜度小。使用快排處理數(shù)據(jù)前,我們是不知道數(shù)據(jù)的排列規(guī)律的,因此一般情況下,被處理的數(shù)據(jù)本來就是一組隨機數(shù)據(jù),對于隨機數(shù)據(jù)再多進行一次隨機化處理,數(shù)據(jù)仍然保持隨機性,對排序沒有更好的效果。 對一組數(shù)據(jù)采用隨選主元的方法,在極端的情況下,也可能出現(xiàn)每次選出的主元恰好是從大到小排列的,此時時間復(fù)雜度為O(n^2).當(dāng)然這個概率極低。隨機選主元的好處在于,由于在現(xiàn)實中常常需要把一些數(shù)據(jù)保存為有序數(shù)據(jù),因此,快速排序碰到有序數(shù)據(jù)的概率就會高一些,使用隨機快排可以提高對這些數(shù)據(jù)的處理效率。這個概率雖然高一些,但仍屬于特殊情況,不影響一般情況的時間復(fù)雜度。我覺得樓主上面提到的的思路4和思路5的時間復(fù)雜度是一樣的。
571樓 得分:0 Sorehead 回復(fù)于:2011-03-09 16:29:58
關(guān)于第五題:
Sorehead: 這兩天我總結(jié)了一下,有以下方法可以實現(xiàn):
1、第一次遍歷取出最小的元素,第二次遍歷取出第二小的元素,依次直到第k次遍歷取出第k小的元素。這種方法最簡單,時間復(fù)雜度是O(k*n)。看上去效率很差,但當(dāng)k很小的時候可能是最快的。
2、對這n個元素進行排序,然后取出前k個數(shù)據(jù)即可,可以采用比較普遍的堆排序或者快速排序,時間復(fù)雜度是O(n*logn)。這種方法有著很大的弊端,題目并沒有要求這最小的k個數(shù)是排好序的,更沒有要求對其它數(shù)據(jù)進行排序,對這些數(shù)據(jù)進行排序某種程度上來講完全是一種浪費。而且當(dāng)k=1時,時間復(fù)雜度依然是O(n*logn)。
3、可以把快速排序改進一下,應(yīng)該和樓主的kth_elem一樣,這樣的好處是不用對所有數(shù)據(jù)都進行排序。平均時間復(fù)雜度應(yīng)該是O(n*logk)。(在本文最后一節(jié),你或?qū)⒖吹剑瑥?fù)雜度可能應(yīng)該為O(n))
4、使用我開始講到的平衡二叉樹或紅黑樹,樹只用來保存k個數(shù)據(jù)即可,這樣遍歷所有數(shù)據(jù)只需要一次。時間復(fù)雜度為O(n*logk)。后來我發(fā)現(xiàn)這個思路其實可以再改進,使用堆排序中的堆,堆中元素數(shù)量為k,這樣堆中最大元素就是頭節(jié)點,遍歷所有數(shù)據(jù)時比較次數(shù)更少,當(dāng)然時間復(fù)雜度并沒有變化。
5、使用計數(shù)排序的方法,創(chuàng)建一個數(shù)組,以元素值為該數(shù)組下標(biāo),數(shù)組的值為該元素在數(shù)組中出現(xiàn)的次數(shù)。這樣遍歷一次就可以得到這個數(shù)組,然后查詢這個數(shù)組就可以得到答案了。時間復(fù)雜度為O(n)。如果元素值沒有重復(fù)的,還可以使用位圖方式。這種方式有一定局限性,元素必須是正整數(shù),并且取值范圍不能太大,否則就造成極大的空間浪費,同時時間復(fù)雜度也未必就是O(n)了。當(dāng)然可以再次改進,使用一種比較合適的哈希算法來代替元素值直接作為數(shù)組下標(biāo)。
litaoye:按照算法導(dǎo)論上所說的,最壞情況下線性時間找第k大的數(shù)。證明一下:把數(shù)組中的元素,5個分為1組排序,排序需要進行7次比較(2^7 > 5!),這樣需要1.4 * n次比較,可以完成所有組的排序。取所有組的中位數(shù),形成一個新的數(shù)組,有n/5個元素,5個分為1組排序,重復(fù)上面的操作,直到只剩下小于5個元素,找出中位數(shù)。根據(jù)等比數(shù)列求和公式,求出整個過程的比較次數(shù):7/5 + 7/25 + 7/125 +...... = 7/4,用7/4 * n次比較可以找出中位數(shù)的中位數(shù)M。能夠證明,整個數(shù)組中>=M的數(shù)超過3*n / 10 - 6,<=M的數(shù)超過3*n / 10 - 6。以M為基準(zhǔn),執(zhí)行上面的PARTITION,每次至少可以淘汰3*n / 10 - 6,約等于3/10 * n個數(shù),也就是說是用(7/4 + 1) * n次比較之后,最壞情況下可以讓數(shù)據(jù)量變?yōu)樵瓉淼?/10,同樣根據(jù)等比數(shù)列求和公式,可以算出最壞情況下找出第k大的數(shù)需要的比較次數(shù),1 + 7/10 + 49/100 + .... = 10/3, 10/3 * 11/4 * n = 110/12 * n,也就是說整個過程是O(n)的,盡管隱含的常數(shù)比較大 。
總結(jié):
關(guān)于RANDOMIZED-SELECT(A, q + 1, r, i - k),期望運行時間為O(n)已經(jīng)沒有疑問了,更嚴(yán)格的論證在上面的第二節(jié)也已經(jīng)給出來了。
ok,現(xiàn)在,咱們剩下的問題是,除了此RANDOMIZED-SELECT(A, q + 1, r, i - k)方法(實用價值并不大)和計數(shù)排序,都可以做到O(n)之外,還有類似快速排序的partition過程,是否也能做到O(n)?
第四節(jié)、類似partition過程,最壞亦能做到O(n)?
我想,經(jīng)過上面的各路好漢的思路轟炸,您的頭腦和思維肯定有所混亂了。ok,下面,我盡量以通俗易懂的方式來繼續(xù)闡述咱們的問題。上面第三節(jié)的總結(jié)提出了一個問題,即類似快速排序的partition過程,是否也能做到O(n)?
我們說對n個數(shù)進行排序,快速排序的平均時間復(fù)雜度為O(n*logn),這個n*logn的時間復(fù)雜度是如何得來的列?
經(jīng)過之前我的有關(guān)快速排序的三篇文章,相信您已經(jīng)明了了以下過程:快速排序每次選取一個主元X,依據(jù)這個主元X,每次把整個序列劃分為A,B倆個部分,且有Ax<X<Bx。
假如我們每次劃分總是產(chǎn)生9:1 的劃分,那么,快速排序運行時間的遞歸式為:T(n)=T(9n/10)+T(n/10)+cn。形成的遞歸樹,(注:最后同樣能推出T(n)=n*logn,即如下圖中,每一層的代價為cn,共有l(wèi)ogn層(深度),所以,最后的時間復(fù)雜度為O(n)*logn)如下:
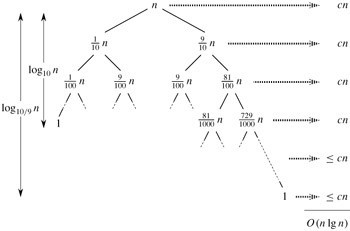
而我們知道,如果我們每次劃分都是平衡的,即每次都劃分為均等的兩部分元素(對應(yīng)上圖,第一層1/2,1/2,,第二層1/4,1/4.....),那么,此時快速排序的運行時間的遞歸式為:
T (n) ≤ 2T (n/2) + Θ(n) ,同樣,可推導(dǎo)出:T (n) = O(n lg n).
這就是快速排序的平均時間復(fù)雜度的由來。
那么,咱們要面對的問題是什么,要尋找n個數(shù)的序列中前k個元素。如何找列?假設(shè)咱們首先第一次對n個數(shù)運用快速排序的partition過程劃分,主元為Xm,此刻找到的主元元素Xm肯定為序列中第m小的元素,此后,分為三種情況:
1、如果m=k,即返回的主元即為我們要找的第k小的元素,那么直接返回主元Xm即可,然后直接輸出Xm前面的m-1個元素,這m個元素,即為所求的前k個最小的元素。
2、如果m>k,那么接下來要到低區(qū)間A[0....m-1]中尋找,丟掉高區(qū)間;
3、如果m<k,那么接下來要到高區(qū)間A[m+1...n-1]中尋找,丟掉低區(qū)間。
當(dāng)m一直>k的時候,好說,區(qū)間總是被不斷的均分為倆個區(qū)間(理想情況),那么最后的時間復(fù)雜度如luuillu所說,T(n)=n + T(n/2) = n + n/2 + n/4 + n/8 + ...+1 . 式中一共logn項。可得出:T(n)為O(n)。
但當(dāng)m<k的時候,上述情況,就不好說了。正如luuillu所述:當(dāng)m<k,那么接下來要到高區(qū)間A[m+1...n-1]中尋找,新區(qū)間的長度為n-m-1, 需要尋找 k-m個數(shù)。此時可令:k=k-m, m=n-m-1, 遞歸調(diào)用原算法處理,本次執(zhí)行次數(shù)為 m,當(dāng)m減到1算法停止(當(dāng)m<k 時 ,k=m-k.這個判斷過程實際上相當(dāng)于對m取模運算,即:k=k%m;)。
最終在高區(qū)間找到的k-m個數(shù),加上在低區(qū)間的k個數(shù),即可找到最小的k個數(shù),是否也能得出T(n)=O(n),則還有待驗證(本文已經(jīng)全面更新,所有的論證,都已經(jīng)給出,確認(rèn)無誤的是:類似快速排序的partition過程,明確的可以做到O(N))。
Ok,如果在評論里回復(fù),有諸多不便,歡迎到此帖子上回復(fù):微軟100題維護地址,我會隨時追蹤這個帖子。謝謝。
- //求取無序數(shù)組中第K個數(shù),本程序樞紐元的選取有問題,不作推薦。
- //copyright@ 飛羽
- //July、yansha,updated,2011.05.18。
- #include <iostream>
- #include <time.h>
- using namespace std;
-
- int kth_elem(int a[], int low, int high, int k)
- {
- int pivot = a[low];
- //這個程序之所以做不到O(N)的最最重要的原因,就在于這個樞紐元的選取。
- //而這個程序直接選取數(shù)組中第一個元素作為樞紐元,是做不到平均時間復(fù)雜度為 O(N)的。
-
- //要 做到,就必須 把上面選取樞紐元的 代碼改掉,要么是隨機選擇數(shù)組中某一元素作為樞紐元,能達到線性期望的時間
- //要么是選取數(shù)組中中位數(shù)的中位數(shù)作為樞紐元,保證最壞情況下,依然為線性O(shè)(N)的平均時間復(fù)雜度。
- int low_temp = low;
- int high_temp = high;
- while(low < high)
- {
- while(low < high && a[high] >= pivot)
- --high;
- a[low] = a[high];
- while(low < high && a[low] < pivot)
- ++low;
- a[high] = a[low];
- }
- a[low] = pivot;
-
- //以下就是主要思想中所述的內(nèi)容
- if(low == k - 1)
- return a[low];
- else if(low > k - 1)
- return kth_elem(a, low_temp, low - 1, k);
- else
- return kth_elem(a, low + 1, high_temp, k);
- }
-
- int main() //以后盡量不再用隨機產(chǎn)生的數(shù)組進行測試,沒多大必要。
- {
- for (int num = 5000; num < 50000001; num *= 10)
- {
- int *array = new int[num];
-
- int j = num / 10;
- int acc = 0;
- for (int k = 1; k <= num; k += j)
- {
- // 隨機生成數(shù)據(jù)
- srand(unsigned(time(0)));
- for(int i = 0; i < num; i++)
- array[i] = rand() * RAND_MAX + rand();
- //”如果數(shù)組本身就是利用隨機化產(chǎn)生的話,那么選擇其中任何一個元素作為樞軸都可以看作等價于隨機選擇樞軸,
- //(雖然這不叫隨機選擇樞紐)”,這句話,是完全不成立的,是錯誤的。
-
- //“因為你總是選擇 隨機數(shù)組中第一個元素 作為樞紐元,不是 隨機選擇樞紐元”
- //相當(dāng)于把上面這句話中前面的 “隨機” 兩字去掉,就是:
- //因為 你總是選擇數(shù)組中第一個元素作為樞紐元,不是 隨機選擇樞紐元。
- //所以,這個程序,始終做不到平均時間復(fù)雜度為O(N)。
-
- //隨機數(shù)組和給定一個非有序而隨機手動輸入的數(shù)組,是一個道理。稍后,還將就程序的運行結(jié)果繼續(xù)解釋這個問題。
- //July、updated,2011.05.18。
-
- // 計算一次查找所需的時鐘周期數(shù)
- clock_t start = clock();
- int data = kth_elem(array, 0, num - 1, k);
- clock_t end = clock();
- acc += (end - start);
- }
- cout << "The average time of searching a date in the array size of " << num << " is " << acc / 10 << endl;
- }
- return 0;
- }
關(guān)于上述程序的更多闡述,請參考此文
第三章續(xù)、Top K算法問題的實現(xiàn)中,第一節(jié)有關(guān)實現(xiàn)三的說明。
updated:
近日,再次在Mark Allen Weiss的數(shù)據(jù)結(jié)構(gòu)與算法分析一書上,第10章,第10.2.3節(jié)看到了關(guān)于此分治算法的應(yīng)用,平均時間復(fù)雜度為O(N)的闡述與證明,可能本文之前的敘述將因此而改寫(July、updated,2011.05.05):
The selection problem requires us to find the kth smallest element in a list S of n elements(要求我們找出含N個元素的表S中的第k個最小的元素). Of particular interest is the special case of finding the median. This occurs when k = |-n/2-|(向上取整).(我們對找出中間元素的特殊情況有著特別的興趣,這種情況發(fā)生在k=|-n/2-|的時候)
In Chapters 1, 6, 7 we have seen several solutions to the selection problem. The solution in Chapter 7 uses a variation of quicksort and runs in O(n) average time(第7章中的解法,即本文上面第1節(jié)所述的思路4,用到快速排序的變體并以平均時間O(N)運行). Indeed, it is described in Hoare's original paper on quicksort.
Although this algorithm runs in linear average time, it has a worst case of O (n2)(但它有一個O(N^2)的最快情況). Selection can easily be solved in O(n log n) worst-case time by sorting the elements, but for a long time it was unknown whether or not selection could be accomplished in O(n) worst-case time. The quickselect algorithm outlined in Section 7.7.6 is quite efficient in practice, so this was mostly a question of theoretical interest.
Recall that the basic algorithm is a simple recursive strategy. Assuming that n is larger than the cutoff point where elements are simply sorted, an element v, known as the pivot, is chosen. The remaining elements are placed into two sets, S1 and S2. S1 contains elements that are guaranteed to be no larger than v, and S2 contains elements that are no smaller than v. Finally, if k <= |S1|, then the kth smallest element in S can be found by recursively computing the kth smallest element in S1. If k = |S1| + 1, then the pivot is the kth smallest element. Otherwise, the kth smallest element in S is the (k - |S1| -1 )st smallest element in S2. The main difference between this algorithm and quicksort is that there is only one subproblem to solve instead of two(這個快速選擇算法與快速排序之間的主要區(qū)別在于,這里求解的只有一個子問題,而不是兩個子問題)。
定理10.9
The running time of quickselect using median-of-median-of-five partitioning is O(n)。
The basic idea is still useful. Indeed, we will see that we can use it to improve the expected number of comparisons that quickselect makes. To get a good worst case, however, the key idea is to use one more level of indirection. Instead of finding the median from a sample of random elements, we will find the median from a sample of medians.
The basic pivot selection algorithm is as follows:
1. Arrange the n elements into |_n/5_| groups of 5 elements, ignoring the (at most four) extra elements.
2. Find the median of each group. This gives a list M of |_n/5_| medians.
3. Find the median of M. Return this as the pivot, v.
We will use the term median-of-median-of-five partitioning to describe the quickselect algorithm that uses the pivot selection rule given above. (我們將用術(shù)語“五分化中項的中項”來描述使用上面給出的樞紐元選擇法的快速選擇算法)。We will now show that median-of-median-of-five partitioning guarantees that each recursive subproblem is at most roughly 70 percent as large as the original(現(xiàn)在我們要證明,“五分化中項的中項”,得保證每個遞歸子問題的大小最多為原問題的大約70%). We will also show that the pivot can be computed quickly enough to guarantee an O (n) running time for the entire selection algorithm(我們還要證明,對于整個選擇算法,樞紐元可以足夠快的算出,以確保O(N)的運行時間。看到了沒,這再次佐證了我們的類似快速排序的partition過程的分治方法為O(N)的觀點)。
..........
證明從略,更多,請參考Mark Allen Weiss的數(shù)據(jù)結(jié)構(gòu)與算法分析--c語言描述一書上,第10章,第10.2.3節(jié)。
updated again:
為了給讀者一個徹徹底底、明明白白的論證,我還是決定把書上面的整個論證過程全程貼上來,下面,接著上面的內(nèi)容,然后直接從其中文譯本上截兩張圖來說明好了(更清晰明了):


關(guān)于上圖提到的定理10.8,如下圖所示,至于證明,留給讀者練習(xí)(可參考本文第二節(jié)關(guān)于RANDOMIZED-SELECT為線性時間的證明):
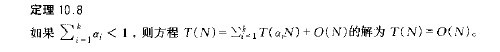
ok,第四節(jié),有關(guān)此問題的更多論述,請參見下面的本文文末updated again部分。
第五節(jié)、堆結(jié)構(gòu)實現(xiàn),處理海量數(shù)據(jù)
文章,可不能這么完了,咱們還得實現(xiàn)一種靠譜的方案,從整個文章來看,處理這個尋找最小的k個數(shù),最好的方案是第一節(jié)中所提到的思路3:當(dāng)然,更好的辦法是維護k個元素的最大堆,原理與上述第2個方案一致,即用容量為k的最大堆存儲最小的k個數(shù),此時,k1<k2<...<kmax(kmax設(shè)為大頂堆中最大元素)。遍歷一次數(shù)列,n,每次遍歷一個元素x,與堆頂元素比較,x<kmax,更新堆(用時logk),否則不更新堆。這樣下來,總費時O(n*logk)。
為什么?道理很簡單,如果要處理的序列n比較小時,思路2(選擇排序)的n*k的復(fù)雜度還能說得過去,但當(dāng)n很大的時候列?同時,別忘了,如果選擇思路1(快速排序),還得在數(shù)組中存儲n個數(shù)。當(dāng)面對海量數(shù)據(jù)處理的時候列?n還能全部存放于電腦內(nèi)存中么?(或許可以,或許很難)。
ok,相信你已經(jīng)明白了我的意思,下面,給出借助堆(思路3)這個數(shù)據(jù)結(jié)構(gòu),來尋找最小的k個數(shù)的完整代碼,如下:
- //借助堆,查找最小的k個數(shù)
- //copyright@ yansha &&July
- //July、updated,2011.04.28。
- #include <iostream>
- #include <assert.h>
- using namespace std;
- void MaxHeap(int heap[], int i, int len);
- /*-------------------
- BUILD-MIN-HEAP(A)
- 1 heap-size[A] ← length[A]
- 2 for i ← |_length[A]/2_| downto 1
- 3 do MAX-HEAPIFY(A, i)
- */
- // 建立大根堆
- void BuildHeap(int heap[], int len)
- {
- if (heap == NULL)
- return;
-
- int index = len / 2;
- for (int i = index; i >= 1; i--)
- MaxHeap(heap, i, len);
- }
- /*----------------------------
- PARENT(i)
- return |_i/2_|
- LEFT(i)
- return 2i
- RIGHT(i)
- return 2i + 1
- MIN-HEAPIFY(A, i)
- 1 l ← LEFT(i)
- 2 r ← RIGHT(i)
- 3 if l ≤ heap-size[A] and A[l] < A[i]
- 4 then smallest ← l
- 5 else smallest ← i
- 6 if r ≤ heap-size[A] and A[r] < A[smallest]
- 7 then smallest ← r
- 8 if smallest ≠ i
- 9 then exchange A[i] <-> A[smallest]
- 10 MIN-HEAPIFY(A, smallest)
- */
- //調(diào)整大根堆
- void MaxHeap(int heap[], int i, int len)
- {
- int largeIndex = -1;
- int left = i * 2;
- int right = i * 2 + 1;
-
- if (left <= len && heap[left] > heap[i])
- largeIndex = left;
- else
- largeIndex = i;
-
- if (right <= len && heap[right] > heap[largeIndex])
- largeIndex = right;
-
- if (largeIndex != i)
- {
- swap(heap[i], heap[largeIndex]);
- MaxHeap(heap, largeIndex, len);
- }
- }
- int main()
- {
- // 定義數(shù)組存儲堆元素
- int k;
- cin >> k;
- int *heap = new int [k+1]; //注,只需申請存儲k個數(shù)的數(shù)組
- FILE *fp = fopen("data.txt", "r"); //從文件導(dǎo)入海量數(shù)據(jù)(便于測試,只截取了9M的數(shù)據(jù)大小)
- assert(fp);
-
- for (int i = 1; i <= k; i++)
- fscanf(fp, "%d ", &heap[i]);
-
- BuildHeap(heap, k); //建堆
-
- int newData;
- while (fscanf(fp, "%d", &newData) != EOF)
- {
- if (newData < heap[1]) //如果遇到比堆頂元素kmax更小的,則更新堆
- {
- heap[1] = newData;
- MaxHeap(heap, 1, k); //調(diào)整堆
- }
-
- }
-
- for (int j = 1; j <= k; j++)
- cout << heap[j] << " ";
- cout << endl;
-
- fclose(fp);
- return 0;
- }
咱們用比較大量的數(shù)據(jù)文件測試一下,如這個數(shù)據(jù)文件:
輸入k=4,即要從這大量的數(shù)據(jù)中尋找最小的k個數(shù),可得到運行結(jié)果,如下圖所示:
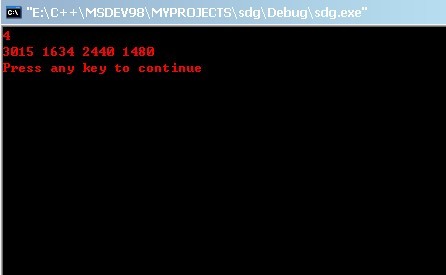
至于,這4個數(shù),到底是不是上面大量數(shù)據(jù)中最小的4個數(shù),這個,咱們就無從驗證了,非人力之所能及也。畢。
第六節(jié)、stl之_nth_element ,逐步實現(xiàn)
以下代碼摘自stl中_nth_element的實現(xiàn),且逐步追蹤了各項操作,其完整代碼如下:
- //_nth_element(...)的實現(xiàn)
- template <class RandomAccessIterator, class T>
- void __nth_element(RandomAccessIterator first, RandomAccessIterator nth,
- RandomAccessIterator last, T*) {
- while (last - first > 3) {
- RandomAccessIterator cut = __unguarded_partition //下面追蹤__unguarded_partition
- (first, last, T(__median(*first, *(first + (last - first)/2),
- *(last - 1))));
- if (cut <= nth)
- first = cut;
- else
- last = cut;
- }
- __insertion_sort(first, last); //下面追蹤__insertion_sort(first, last)
- }
-
- //__unguarded_partition()的實現(xiàn)
- template <class RandomAccessIterator, class T>
- RandomAccessIterator __unguarded_partition(RandomAccessIterator first,
- RandomAccessIterator last,
- T pivot) {
- while (true) {
- while (*first < pivot) ++first;
- --last;
- while (pivot < *last) --last;
- if (!(first < last)) return first;
- iter_swap(first, last);
- ++first;
- }
- }
-
- //__insertion_sort(first, last)的實現(xiàn)
- template <class RandomAccessIterator>
- void __insertion_sort(RandomAccessIterator first, RandomAccessIterator last) {
- if (first == last) return;
- for (RandomAccessIterator i = first + 1; i != last; ++i)
- __linear_insert(first, i, value_type(first)); //下面追蹤__linear_insert
- }
-
- //_linear_insert()的實現(xiàn)
- template <class RandomAccessIterator, class T>
- inline void __linear_insert(RandomAccessIterator first,
- RandomAccessIterator last, T*) {
- T value = *last;
- if (value < *first) {
- copy_backward(first, last, last + 1); //這個追蹤,待續(xù)
- *first = value;
- }
- else
- __unguarded_linear_insert(last, value); //最后,再追蹤__unguarded_linear_insert
- }
-
- //_unguarded_linear_insert()的實現(xiàn)
- template <class RandomAccessIterator, class T>
- void __unguarded_linear_insert(RandomAccessIterator last, T value) {
- RandomAccessIterator next = last;
- --next;
- while (value < *next) {
- *last = *next;
- last = next;
- --next;
- }
- *last = value;
- }
第七節(jié)、再探Selection_algorithm,類似partition方法O(n)再次求證
網(wǎng)友反饋:
stupidcat:用類似快排的partition的方法,只求2邊中的一邊,在O(N)時間得到第k大的元素v;
弄完之后,vector<int> &data的前k個元素,就是最小的k個元素了。
時間復(fù)雜度是O(N),應(yīng)該是最優(yōu)的算法了。并給出了代碼示例:
- //copyright@ stupidcat
- //July、updated,2011.05.08
- int Partition(vector<int> &data, int headId, int tailId)
- //這里,采用的是算法導(dǎo)論上的partition過程方法
- {
- int posSlow = headId - 1, posFast = headId; //一前一后,倆個指針
- for (; posFast < tailId; ++posFast)
- {
- if (data[posFast] < data[tailId]) //以最后一個元素作為主元
- {
- ++posSlow;
- swap(data[posSlow], data[posFast]);
- }
- }
- ++posSlow;
- swap(data[posSlow], data[tailId]);
- return posSlow; //寫的不錯,命名清晰
- }
-
- void FindKLeast(vector<int> &data, int headId, int tailId, int k)
- //尋找第k小的元素
- {
- if (headId < tailId)
- {
- int midId = Partition(data, headId, tailId);
- //可惜這里,沒有隨機或中位數(shù)的方法選取樞紐元(主元),使得本程序思路雖對,卻不達O(N)的目標(biāo)
-
- if (midId > k)
- {
- FindKLeast(data, headId, midId - 1, k); //k<midid,直接在低區(qū)間找
- }
-
- else
- {
- if (midId < k)
- {
- FindKLeast(data, midId + 1, tailId, k); //k>midid,遞歸到高區(qū)間找
- }
- }
- }
- }
-
- void FindKLeastNumbers(vector<int> &data, unsigned int k)
- {
- int len = data.size();
- if (k > len)
- {
- throw new std::exception("Invalid argument!");
- }
- FindKLeast(data, 0, len - 1, k);
- }
看來,這個問題,可能會因此糾纏不清了,近日,在維基百科的英文頁面上,找到有關(guān)Selection_algorithm的資料,上面給出的示例代碼為:
- function partition(list, left, right, pivotIndex)
- pivotValue := list[pivotIndex]
- swap list[pivotIndex] and list[right] // Move pivot to end
- storeIndex := left
- for i from left to right
- if list[i] < pivotValue
- swap list[storeIndex] and list[i]
- increment storeIndex
- swap list[right] and list[storeIndex] // Move pivot to its final place
- return storeIndex
-
- function select(list, left, right, k)
- if left = right
- return list[left]
- select pivotIndex between left and right
- pivotNewIndex := partition(list, left, right, pivotIndex)
- pivotDist := pivotNewIndex - left + 1
- if pivotDist = k
- return list[pivotNewIndex]
- else if k < pivotDist
- return select(list, left, pivotNewIndex - 1, k)
- else
- return select(list, pivotNewIndex + 1, right, k - pivotDist)
這個算法,其實就是在本人這篇文章:當(dāng)今世界最受人們重視的十大經(jīng)典算法里提到的:第三名:BFPRT 算法:
A worst-case linear algorithm for the general case of selecting the kth largest element was published by Blum,
Floyd, Pratt, Rivest and Tarjan in their 1973 paper "Time bounds for selection",
sometimes called BFPRT after the last names of the authors.
It is based on the quickselect algorithm and is also known as the median-of-medians algorithm.
同時據(jù)維基百科上指出,若能選取一個好的pivot,則此算法能達到O(n)的最佳時間復(fù)雜度。
The median-calculating recursive call does not exceed worst-case linear behavior
because the list of medians is 20% of the size of the list,
while the other recursive call recurs on at most 70% of the list, making the running time
T(n) ≤ T(n/5) + T(7n/10) + O(n)
The O(n) is for the partitioning work (we visited each element a constant number of times,
in order to form them into O(n) groups and take each median in O(1) time).
From this, one can then show that T(n) ≤ c*n*(1 + (9/10) + (9/10)2 + ...) = O(n).
當(dāng)然,上面也提到了用堆這個數(shù)據(jù)結(jié)構(gòu),掃描一遍數(shù)組序列,建k個元素的堆O(k)的同時,調(diào)整堆(logk),然后再遍歷剩下的n-k個元素,根據(jù)其與堆頂元素的大小比較,決定是否更新堆,更新一次logk,所以,最終的時間復(fù)雜度為O(k*logk+(n-k)*logk)=O(n*logk)。
Another simple method is to add each element of the list into an ordered set data structure,
such as a heap or self-balancing binary search tree, with at most k elements.
Whenever the data structure has more than k elements, we remove the largest element,
which can be done in O(log k) time. Each insertion operation also takes O(log k) time,
resulting in O(nlog k) time overall.
而如果上述類似快速排序的partition過程的BFPRT 算法成立的話,則將最大限度的優(yōu)化了此尋找第k個最小元素的算法復(fù)雜度(經(jīng)過第1節(jié)末+第二節(jié)+第4節(jié)末的updated,以及本節(jié)的論證,現(xiàn)最終確定,運用類似快速排序的partition算法尋找最小的k個元素能做到O(N)的復(fù)雜度,并確認(rèn)無疑。July、updated,2011.05.05.凌晨)。
updated again:
為了再次佐證上述論證之不可懷疑的準(zhǔn)確性,我再原文引用下第九章第9.3節(jié)全部內(nèi)容(最壞情況線性時間的選擇),如下(我酌情對之參考原中文版做了翻譯,下文中括號內(nèi)的中文解釋,為我個人添加):
9.3 Selection in worst-case linear time(最壞情況下線性時間的選擇算法)
We now examine a selection algorithm whose running time isO(n) in the worst case(現(xiàn)在來看,一個最壞情況運行時間為O(N)的選擇算法SELECT). Like RANDOMIZED-SELECT, the algorithm SELECT finds the desired element by recursively partitioning the input array. The idea behind the algorithm, however, is toguarantee a good split when the array is partitioned. SELECT uses the deterministic partitioning algorithm PARTITION from quicksort (seeSection 7.1), modified to take the element to partition around as an input parameter(像RANDOMIZED-SELECT一樣,SELECTT通過輸入數(shù)組的遞歸劃分來找出所求元素,但是,該算法的基本思想是要保證對數(shù)組的劃分是個好的劃分。SECLECT采用了取自快速排序的確定性劃分算法partition,并做了修改,把劃分主元元素作為其參數(shù)).
The SELECT algorithm determines theith smallest of an input array ofn > 1 elements by executing the following steps. (Ifn = 1, then SELECT merely returns its only input value as theith smallest.)(算法SELECT通過執(zhí)行下列步驟來確定一個有n>1個元素的輸入數(shù)組中的第i小的元素。(如果n=1,則SELECT返回它的唯一輸入數(shù)值作為第i個最小值。))
- Divide then elements of the input array into⌋ groups of 5 elements each and at most one group made up of the remainingn mod 5 elements.
- Find the median of each of the⌉ groups by first insertion sorting the elements of each group (of which there are at most 5) and then picking the median from the sorted list of group elements.
- Use SELECT recursively to find the medianx of the⌉ medians found in step 2. (If there are an even number of medians, then by our convention,x is the lower median.)
- Partition the input array around the median-of-mediansx using the modified version of PARTITION. Letk be one more than the number of elements on the low side of the partition, so thatx is thekth smallest element and there aren-k elements on the high side of the partition.(利用修改過的partition過程,按中位數(shù)的中位數(shù)x對輸入數(shù)組進行劃分,讓k比劃低去的元素數(shù)目多1,所以,x是第k小的元素,并且有n-k個元素在劃分的高區(qū))
- Ifi =k, then returnx. Otherwise, use SELECT recursively to find theith smallest element on the low side ifi <k, or the (i -k)th smallest element on the high side ifi >k.(如果要找的第i小的元素等于程序返回的k,即i=k,則返回x。否則,如果i<k,則在低區(qū)遞歸調(diào)用SELECT以找出第i小的元素,如果i>k,則在高區(qū)間找第(i-k)個最小元素)

(以上五個步驟,即本文上面的第四節(jié)末中所提到的所謂“五分化中項的中項”的方法。)
To analyze the running time of SELECT, we first determine a lower bound on the number of elements that are greater than the partitioning element x. (為了分析SELECT的運行時間,先來確定大于劃分主元元素x的的元素數(shù)的一個下界)Figure 9.1 is helpful in visualizing this bookkeeping. At least half of the medians found in step 2 are greater than[1] the median-of-medians x. Thus, at least half of the ⌉ groupscontribute 3 elements that are greater than x, except for the one group that has fewer than 5 elements if 5 does not dividen exactly, and the one group containingx itself. Discounting these two groups, it follows that the number of elements greater thanx is at least:
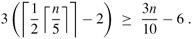
(Figure 9.1: 對上圖的解釋或稱對SELECT算法的分析:n個元素由小圓圈來表示,并且每一個組占一縱列。組的中位數(shù)用白色表示,而各中位數(shù)的中位數(shù)x也被標(biāo)出。(當(dāng)尋找偶數(shù)數(shù)目元素的中位數(shù)時,使用下中位數(shù))。箭頭從比較大的元素指向較小的元素,從中可以看出,在x的右邊,每一個包含5個元素的組中都有3個元素大于x,在x的左邊,每一個包含5個元素的組中有3個元素小于x。大于x的元素以陰影背景表示。 )
Similarly, the number of elements that are less thanx is at least 3n/10 - 6. Thus, in the worst case, SELECT is called recursively on at most 7n/10 + 6 elements in step 5.
We can now develop a recurrence for the worst-case running timeT(n) of the algorithm SELECT. Steps 1, 2, and 4 take O(n) time. (Step 2 consists ofO(n) calls of insertion sort on sets of sizeO(1).) Step 3 takes timeT(⌉), and step 5 takes time at mostT(7n/10+ 6), assuming thatT is monotonically increasing. We make the assumption, which seems unmotivated at first, that any input of 140 or fewer elements requiresO(1) time; the origin of the magic constant 140 will be clear shortly. We can therefore obtain the recurrence:
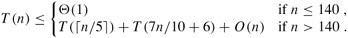
We show that the running time is linear by substitution. More specifically, we will show thatT(n) ≤cn for some suitably large constant c and alln > 0. We begin by assuming thatT(n) ≤cn for some suitably large constantc and alln ≤ 140; this assumption holds ifc is large enough. We also pick a constanta such that the function described by theO(n) term above (which describes the non-recursive component of the running time of the algorithm) is bounded above byan for alln > 0. Substituting this inductive hypothesis into the right-hand side of the recurrence yields
T(n) | ≤ | c⌉ +c(7n/10 + 6) +an |
| ≤ | cn/5 +c + 7cn/10 + 6c +an |
| = | 9cn/10 + 7c +an |
| = | cn + (-cn/10 + 7c +an) , |
which is at mostcn if
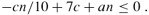
Inequality (9.2) is equivalent to the inequalityc ≥ 10a(n/(n - 70)) when n > 70. Because we assume thatn ≥ 140, we have n/(n - 70) ≤ 2, and so choosing c ≥ 20a will satisfyinequality (9.2). (Note that there is nothing special about the constant 140; we could replace it by any integer strictly greater than 70 and then choosec accordingly.) The worst-case running time of SELECT is therefore linear(因此,此SELECT的最壞情況的運行時間是線性的).
As in a comparison sort (seeSection 8.1), SELECT and RANDOMIZED-SELECT determine information about the relative order of elements only by comparing elements. Recall fromChapter 8 that sorting requiresΩ(n lgn) time in the comparison model, even on average (see Problem 8-1). The linear-time sorting algorithms in Chapter 8 make assumptions about the input. In contrast, the linear-time selection algorithms in this chapter do not require any assumptions about the input. They are not subject to the Ω(nlgn) lower bound because they manage to solve the selection problem without sorting.
(與比較排序(算法導(dǎo)論8.1節(jié))中的一樣,SELECT和RANDOMIZED-SELECT僅通過元素間的比較來確定它們之間的相對次序。在算法導(dǎo)論第8章中,我們知道在比較模型中,即使在平均情況下,排序仍然要O(n*logn)的時間。第8章得線性時間排序算法在輸入上做了假設(shè)。相反地,本節(jié)提到的此類似partition過程的SELECT算法不需要關(guān)于輸入的任何假設(shè),它們不受下界O(n*logn)的約束,因為它們沒有使用排序就解決了選擇問題(看到了沒,道出了此算法的本質(zhì)阿))
Thus, the running time is linear because these algorithms do not sort; the linear-time behavior is not a result of assumptions about the input, as was the case for the sorting algorithms inChapter 8. Sorting requiresΩ(n lgn) time in the comparison model, even on average (see Problem 8-1), and thus the method of sorting and indexing presented in the introduction to this chapter is asymptotically inefficient.(所以,本節(jié)中的選擇算法之所以具有線性運行時間,是因為這些算法沒有進行排序;線性時間的結(jié)論并不需要在輸入上所任何假設(shè),即可得到。.....)
ok,綜述全文,根據(jù)選取不同的元素作為主元(或樞紐)的情況,可簡單總結(jié)如下:
1、RANDOMIZED-SELECT,以序列中隨機選取一個元素作為主元,可達到線性期望時間O(N)的復(fù)雜度。
這個在本文第一節(jié)有關(guān)編程之美第2.5節(jié)關(guān)于尋找最大的k個元素(但其n*logk的復(fù)雜度是嚴(yán)重錯誤的,待勘誤,應(yīng)以算法導(dǎo)論上的為準(zhǔn),隨機選取主元,可達線性期望時間的復(fù)雜度),及本文第二節(jié)中涉及到的算法導(dǎo)論上第九章第9.2節(jié)中(以線性期望時間做選擇),都是以隨機選取數(shù)組中任一元素作為樞紐元的。
2、SELECT,快速選擇算法,以序列中“五分化中項的中項”,或“中位數(shù)的中位數(shù)”作為主元(樞紐元),則不容置疑的可保證在最壞情況下亦為O(N)的復(fù)雜度。
這個在本文第四節(jié)末,及本文第七節(jié),本文文末中都有所闡述,具體涉及到了算法導(dǎo)論一書中第九章第9.3節(jié)的最快情況線性時間的選擇,及Mark Allen Weiss所著的數(shù)據(jù)結(jié)構(gòu)與算法分析--c語言描述一書的第10章第10.2.3節(jié)(選擇問題)中,都有所闡述。
本文結(jié)論:至此,可以毫無保留的確定此問題之結(jié)論:運用類似快速排序的partition的快速選擇SELECT算法尋找最小的k個元素能做到O(N)的復(fù)雜度。RANDOMIZED-SELECT可能會有O(N^2)的最壞的時間復(fù)雜度,但上面的SELECT算法,采用如上所述的“中位數(shù)的中位數(shù)”的取元方法,則可保證此快速選擇算法在最壞情況下是線性時間O(N)的復(fù)雜度。
最終驗證:
1、我想,我想,是的,僅僅是我猜想,你可能會有這樣的疑問:經(jīng)過上文大量嚴(yán)謹(jǐn)?shù)恼撟C之后,利用SELECT算法,以序列中“五分化中項的中項”,或“中位數(shù)的中位數(shù)”作為主元(樞紐元),的的確確在最壞情況下O(N)的時間復(fù)雜度內(nèi)找到第k小的元素,但是,但是,咱們的要面對的問題是什么?咱們是要找最小的k個數(shù)阿!不是找第k小的元素,而是找最小的k個數(shù)(即不是要你找1個數(shù),而是要你找k個數(shù))?哈哈,問題提的非常之好阿。
2、事實上,在最壞情況下,能在O(N)的時間復(fù)雜度內(nèi)找到第k小的元素,那么,亦能保證最壞情況下在O(N)的時間復(fù)雜度內(nèi)找到前最小的k個數(shù),咱們得找到一個理論依據(jù),即一個證明(我想,等你看到找到前k個數(shù)的時間復(fù)雜度與找第k小的元素,最壞情況下,同樣是O(N)的時間復(fù)雜度后,你便會100%的相信本文的結(jié)論了,然后可以通告全世界,你找到了這個世界上最靠譜的中文算法blog,ok,這是后話)。
算法導(dǎo)論第9章第9.3節(jié)練習(xí)里,有2個題目,與我們將要做的證明是一個道理,請看:
Exercises 9.3-4: ⋆
Suppose that an algorithm uses only comparisons to find the ith smallest element in a set of n elements. Show that it can also find the i - 1 smaller elements and the n - i larger elements without performing any additional comparisons.(假設(shè)對一個含有n個元素的集合,某算法只需比較來確定第i小的元素。證明:無需另外的比較操作,它也能找到比i 小的i-1個元素和比i大的n-i個元素)。
Exercises 9.3-7
Describe an O(n)-time algorithm that, given a set S of n distinct numbers and a positive integer k ≤ n, determines the k numbers in S that are closest to the median of S.(給出一個O(N)時間的算法,在給定一個有n個不同數(shù)字的集合S以及一個正整數(shù)K<=n后,它能確定出S中最接近其中位數(shù)的k個數(shù)。)
怎么樣,能證明么?既然通過本文,咱們已經(jīng)證明了上述的SELECT算法在最壞情況下O(N)的時間內(nèi)找到第k小的元素,那么距離咱們確切的問題:尋找最小的k個數(shù)的證明,只差一步之遙了。
給點提示:
1、找到了第K小的數(shù)Xk 為O(n),再遍歷一次數(shù)組,找出所有比k小的元素O(N)(比較Xk與數(shù)組中各數(shù)的大小,凡是比Xk小的元素,都是我們要找的元素),最終時間復(fù)雜度即為: O(N)(找到第k小的元素) + 遍歷整個數(shù)組O(N)=O(N)。這個結(jié)論非常之簡單,也無需證明(但是,正如上面的算法導(dǎo)論練習(xí)題9.3-7所述,能否在找到第k小的元素后,能否不需要再比較元素列?)。
2、我們的問題是,找到 第k小的元素后Xk,是否Xk之前的元素就是我們 要找的最小 的k個數(shù),即,Xk前面的數(shù),是否都<=Xk?因為 那樣的話,復(fù)雜度則 變?yōu)椋篛(N)+O(K)(遍歷找到的第k小元素 前面的k個元素)=O(N+K)=O(N),最壞情況下,亦是線性時間。
終極結(jié)論:證明只有一句話:因為本文我們所有的討論都是基于快速排序的partition方法,而這個方法,每次劃分之后,都保證了 樞紐元Xk的前邊元素統(tǒng)統(tǒng)小于Xk,后邊元素統(tǒng)統(tǒng)大于Xk(當(dāng)然,如果你是屬于那種打破沙鍋問到底的人,你可能還想要我證明partition過程中樞紐元素為何能把整個序列分成左小右大兩個部分。但這個不屬于本文討論范疇。讀者可參考算法導(dǎo)論第7章第7.1節(jié)關(guān)于partition過程中循環(huán)不變式的證明)。所以,正如本文第一節(jié)思路5所述在0(n)的時間內(nèi)找到第k小的元素,然后遍歷輸出前面的k個小的元素。如此,再次驗證了咱們之前得到的結(jié)論:運用類似快速排序的partition的快速選擇SELECT算法尋找最小的k個元素,在最壞情況下亦能做到O(N)的復(fù)雜度。
5、RANDOMIZED-SELECT,每次都是隨機選取數(shù)列中的一個元素作為主元,在0(n)的時間內(nèi)找到第k小的元素,然后遍歷輸出前面的k個小的元素。 如果能的話,那么總的時間復(fù)雜度為線性期望時間:O(n+k)=O(n)(當(dāng)k比較小時)。
所以列,所以,恭喜你,你找到了這個世界上最靠譜的中文算法blog。
updated:
我假設(shè),你并不認(rèn)為并贊同上述那句話:你找到了這個世界上最靠譜的中文算法blog。ok,我再給你一個證據(jù):我再次在編程珠璣II上找到了SELECT算法能在平均時間O(N)內(nèi)找出第k小元素的第三個證據(jù)。同時,依據(jù)書上所說,由于SELECT算法采取partition過程劃分整個數(shù)組元素,所以在找到第k小的元素Xk之后,Xk+Xk前面的k個元素即為所要查找的k個元素(下圖為編程珠璣II第15章第15.2節(jié)的截圖,同時各位還可看到,快速排序是遞歸的對倆個子序列進行操作,而選擇算法只對含有K的那一部分重復(fù)操作)。

再多余的話,我不想說了。我知道我的確是一個庸人自擾的P民,即沒有問題的事情卻硬要弄出一堆問題出來,然后再矢志不渝的論證自己的觀點不容置疑之正確性。ok,畢。
備注:
- 快速選擇SELECT算法,雖然復(fù)雜度平均是o(n),但這個系數(shù)比較大,與用一個最大堆0(n*logk)不見得就有優(yōu)勢)
- 當(dāng)K很小時,O(N*logK)與O(N)等價,當(dāng)K很大時,當(dāng)然也就不能忽略掉了。也就是說,在我們這個具體尋找k個最小的數(shù)的問題中,當(dāng)我們無法確定K 的具體值時(是小是大),咱們便不能簡單的從表面上忽略。也就是說:O(N*logK)就是O(N*logK),非O(N)。
- 如果n=1024,k=n-1,最差情況下需比較2n次,而nlog(k-1)=10n,所以不相同。實際上,這個算法時間復(fù)雜度與k沒有直接關(guān)系。且只在第一次劃分的時候用到了K,后面幾次劃分,是根據(jù)實際情況確定的,與K無關(guān)了。
- 但k=n/2時也不是nlogk,因為只在第一次劃分的時候用到了K,后面幾次劃分,是根據(jù)實際情況確定的,與K無關(guān)了。比如a[1001].k=500,第一次把把a劃分成兩部分,b和c ,不妨設(shè)b元素個數(shù)為400個,c中元素為600個,則下一步應(yīng)該舍掉a,然后在c中尋找top100,此時k已經(jīng)變成了100,因此與k無關(guān)。
- 所以,咱們在表述快速選擇算法的平均時間復(fù)雜度時,還是要寫成O(N)的,斷不可寫成O(N*logK)的。
參考文獻:
1、Mark Allen Weiss的數(shù)據(jù)結(jié)構(gòu)與算法分析--c語言描述,第7章第7.7.6節(jié),線性期望時間的選擇算法,第10章第10.2.3節(jié),選擇問題
2、算法導(dǎo)論,第九章第9.2節(jié),以線性期望時間做選擇,第九章第9.3節(jié),最快情況線性時間的選擇
3、編程之美第一版,第141頁,第2.5節(jié) 尋找最大的k個數(shù)(找最大或最小,一個道理)
4、維基百科,http://en.wikipedia.org/wiki/Selection_algorithm。
5、M. Blum, R.W. Floyd, V. Pratt, R. Rivest and R. Tarjan, "Time bounds for selection,"
J. Comput. System Sci. 7 (1973) 448-461.
6、當(dāng)今世界最受人們重視的十大經(jīng)典算法里提到的,BFPRT 算法。
7、編程珠璣II 第15章第15.2節(jié)程序。順便大贊此書。July、updated,2011.05.07。
預(yù)告: 程序員面試題狂想曲、第四章(更多有關(guān)海量數(shù)據(jù)處理,及Top K 算法問題(此問題已作為第三章續(xù)),第四章,擇日發(fā)布。),五月份發(fā)布(近期內(nèi)事情較多,且昨夜因修正此文足足熬到了凌晨4點(但室內(nèi)并無海棠花),寫一篇文章太耗精力和時間,見諒。有關(guān)本人動態(tài),可關(guān)注本人微博:http://weibo.com/julyweibo。謝謝。July、updated,2011.05.05)。
ok,有任何問題,歡迎隨時指出。謝謝。完。