轉(zhuǎn)自:http://my.oschina.net/tuzibuluo/blog?catalog=127826
1.Writable接口 Hadoop 并沒(méi)有使用 JAVA 的序列化,而是引入了自己實(shí)的序列化系統(tǒng), package org.apache.hadoop.io 這個(gè)包中定義了大量的可序列化對(duì)象,這些對(duì)象都實(shí)現(xiàn)了 Writable 接口, Writable 接口是序列化對(duì)象的一個(gè)通用接口.我們來(lái)看下Writable 接口的定義。
public interface Writable{
void write(DataOutput out) throws IOException;
void readFields(DataInput in) throws IOException;
}
Writable接口抽象了兩個(gè)序列化的方法Write和ReadFields,分別對(duì)應(yīng)了序列化和反序列化,參數(shù)DataOutPut 為java.io包內(nèi)的IO類(lèi),Writable接口只是對(duì)象序列化的一個(gè)簡(jiǎn)單聲明。
2.WriteCompareable接口 WriteCompareable接口是Wirtable接口的二次封裝,提供了compareTo(T o)方法,用于序列化對(duì)象的比較的比較。因?yàn)閙apreduce中間有個(gè)基于key的排序階段。
public interface WritableComparable<T> extends Writable, Comparable<T> {
}
下面是io包簡(jiǎn)單的類(lèi)圖關(guān)系。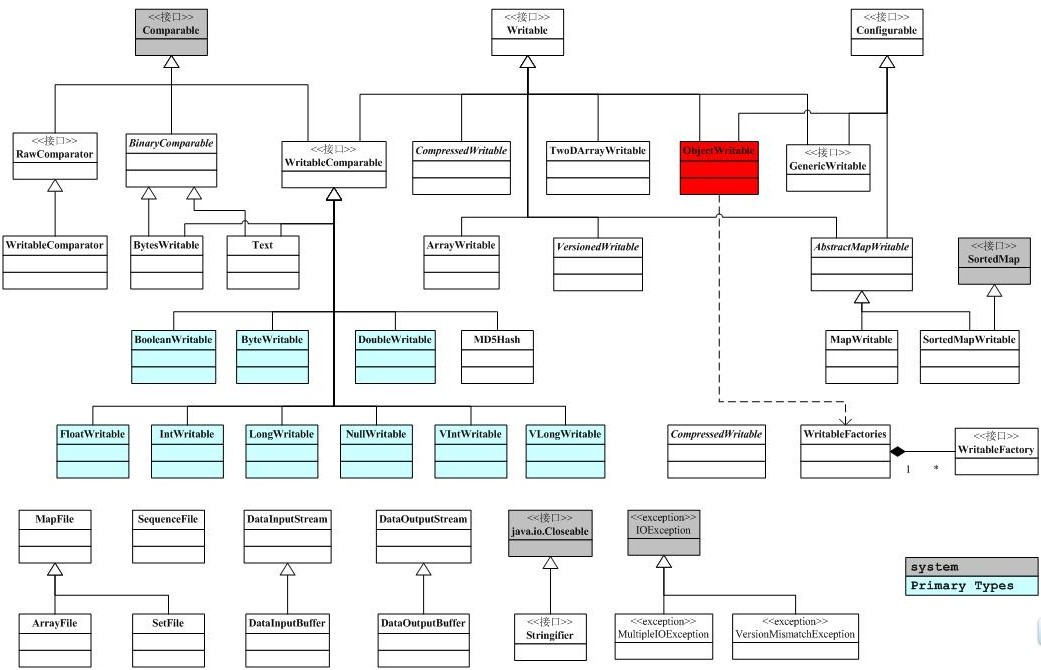
3.
RawComparator接口 hadoop為序列化提供了優(yōu)化,類(lèi)型的比較對(duì)M/R而言至關(guān)重要,Key和Key的比較也是在排序階段完成的,hadoop提供了原生的比較器接口RawComparator<T>用于序列化字節(jié)間的比較,該接口允許其實(shí)現(xiàn)直接比較數(shù)據(jù)流中的記錄,無(wú)需反序列化為對(duì)象,RawComparator是一個(gè)原生的優(yōu)化接口類(lèi),它只是簡(jiǎn)單的提供了用于數(shù)據(jù)流中簡(jiǎn)單的數(shù)據(jù)對(duì)比方法,從而提供優(yōu)化:public interface RawComparator<T> extends Comparator<T> {
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2);
}
該接口并非被多數(shù)的衍生類(lèi)所實(shí)現(xiàn),其直接的子類(lèi)為WritableComparator,多數(shù)情況下是作為實(shí)現(xiàn)Writable接口的類(lèi)的內(nèi)置類(lèi),提供序列化字節(jié)的比較。下面是RawComparator接口內(nèi)置類(lèi)的實(shí)現(xiàn)類(lèi)圖: 首先,我們看 RawComparator的直接實(shí)現(xiàn)類(lèi)WritableComparator:
首先,我們看 RawComparator的直接實(shí)現(xiàn)類(lèi)WritableComparator:
WritableComparator類(lèi)似于一個(gè)注冊(cè)表,里面通過(guò)靜態(tài)map記錄了所有WritableComparator類(lèi)的集合。Comparators成員用一張Hash表記錄Key=Class,value=WritableComprator的注冊(cè)信息.
WritableComparator主要提供了兩個(gè)功能
1. 提供了對(duì)原始compare()方法的一個(gè)默認(rèn)實(shí)現(xiàn)
默認(rèn)實(shí)現(xiàn)是 先反序列化為對(duì)像 再通過(guò) 對(duì)像比較(有開(kāi)銷(xiāo)的問(wèn)題),所以一般都會(huì)被具體writeCompatable類(lèi)的Comparator類(lèi)覆蓋以加快效率。
public
int
compare(byte
[] b1, int
s1, int
l1, byte
[] b2, int
s2, int
l2) {
try
{
buffer.reset(b1, s1, l1); // parse key1
key1.readFields(buffer);
buffer.reset(b2, s2, l2); // parse key2
key2.readFields(buffer);
} catch
(IOException e) {
throw
new
RuntimeException(e);
}
return
compare(key1, key2); // compare them
}2. 充當(dāng)RawComparable實(shí)例的工廠,以注冊(cè)Writable的實(shí)現(xiàn)
例如,為了獲取IntWritable的Comparator,可以直接調(diào)用其get方法。
4.WritableComparator類(lèi)
接下來(lái)?yè)礻P(guān)鍵代碼來(lái)分析writableComparator類(lèi),該類(lèi)是RawComparator接口的直接子類(lèi)。
代碼1:registry 注冊(cè)器
// registry 注冊(cè)器:記載了WritableComparator類(lèi)的集合
private static HashMap<Class, WritableComparator>comparators = new HashMap<Class, WritableComparator>();
----------------------------------------------------------------
代碼2:獲取WritableComparator實(shí)例
說(shuō)明:hashMap作為容器類(lèi)線程不安全,故需要synchronized同步,get方法根據(jù)key=Class返回對(duì)應(yīng)的WritableComparator,若返回的是空值NUll,則調(diào)用protected Constructor進(jìn)行構(gòu)造,而其兩個(gè)protected的構(gòu)造函數(shù)實(shí)則是調(diào)用了newKey()方法進(jìn)行NewInstance
public static synchronized WritableComparator get(Class<? extends WritableComparable> c) {
WritableComparator comparator = comparators.get(c);
if (comparator == null)
comparator = new WritableComparator(c, true);
return comparator;
}
----------------------------------------------------------------
代碼3:WritableComparator構(gòu)造方法
new WritableComparator(c, true)
WritableComparator的構(gòu)造函數(shù)源碼如下:
/*
* keyClass,key1,key2和buffer都是用于WritableComparator的構(gòu)造函數(shù)
*/
private final Class<? extends WritableComparable> keyClass;
private final WritableComparable key1; //WritableComparable接口
private final WritableComparable key2;
private final DataInputBuffer buffer; //輸入緩沖流
protected WritableComparator(Class<? extends WritableComparable> keyClass,boolean createInstances) {
this.keyClass = keyClass;
if (createInstances) {
key1 = newKey();
key2 = newKey();
buffer = new DataInputBuffer();
} else {
key1 = key2 = null;
buffer = null;
}
}
上述的keyClass,key1,key2,buffer是記錄HashMap對(duì)應(yīng)的key值,用于WritableComparator的構(gòu)造函數(shù),但由其構(gòu)造函數(shù)中我們可以看出WritableComparator根據(jù)Boolean createInstance來(lái)判斷是否實(shí)例化key1,key2和buffer,而key1,key2是用于接收比較的兩個(gè)key。在WritableComparator的構(gòu)造函數(shù)里面通過(guò)newKey()的方法去實(shí)例化實(shí)現(xiàn)WritableComparable接口的一個(gè)對(duì)象,下面是newKey()的源碼,通過(guò)hadoop自身的反射去實(shí)例化了一個(gè)WritableComparable接口對(duì)象。
public WritableComparable newKey() {
return ReflectionUtils.newInstance(keyClass, null);
}
----------------------------------------------------------------
代碼4:Compare()方法
(1). public int compare(Object a, Object b);
(2). public int compare(WritableComparable a, WritableComparable b);
(3). public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2);
三個(gè)compare()重載方法中,compare(Object a, Object b)利用子類(lèi)塑形為WritableComparable而調(diào)用了第2個(gè)compare方法,而第2個(gè)Compare()方法則調(diào)用了Writable.compaerTo();最后一個(gè)compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2)方法源碼如下:public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
try {
buffer.reset(b1, s1, l1); // parse key1
key1.readFields(buffer);
buffer.reset(b2, s2, l2); // parse key2
key2.readFields(buffer);
} catch (IOException e) {
throw new RuntimeException(e);
}
return compare(key1, key2); // compare them
}
Compare方法的一個(gè)缺省實(shí)現(xiàn)方式,根據(jù)接口key1,ke2反序列化為對(duì)象再進(jìn)行比較。
利用Buffer為橋接中介,把字節(jié)數(shù)組存儲(chǔ)為buffer后,調(diào)用key1(WritableComparable)的反序列化方法,再來(lái)比較key1,ke2,由此處可以看出,該compare方法是將要比較的二進(jìn)制流反序列化為對(duì)象,再調(diào)用方法第2個(gè)重載方法進(jìn)行比較。
----------------------------------------------------------------代碼5:方法define方法
該方法用于注冊(cè)WritebaleComparaor對(duì)象到注冊(cè)表中,注意同時(shí)該方法也需要同步,代碼如下:
public static synchronized void define(Class c, WritableComparator comparator) {
comparators.put(c, comparator);
}
----------------------------------------------------------------代碼6:余下諸如readInt的靜態(tài)方法 這些方法用于實(shí)現(xiàn)WritableComparable的各種實(shí)例,例如 IntWritable實(shí)例:內(nèi)部類(lèi)Comparator類(lèi)需要根據(jù)自己的IntWritable類(lèi)型重載WritableComparator里面的compare()方法,可以說(shuō)WritableComparator里面的compare()方法只是提供了一個(gè)缺省的實(shí)現(xiàn),而真正的compare()方法實(shí)現(xiàn)需要根據(jù)自己的類(lèi)型如IntWritable進(jìn)行重載,所以WritableComparator方法中的那些readInt..等方法只是底層的封裝的一個(gè)實(shí)現(xiàn),方便內(nèi)部Comparator進(jìn)行調(diào)用而已。
下面我們著重看下BooleanWritable類(lèi)的內(nèi)置RawCompartor<T>的實(shí)現(xiàn)過(guò)程:
public static class Comparator extends WritableComparator {
public Comparator() {//調(diào)用父類(lèi)的Constructor初始化keyClass=BooleanWrite.class
super(BooleanWritable.class);
}
//重寫(xiě)父類(lèi)的序列化比較方法,用些類(lèi)用到父類(lèi)提供的缺省方法
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
boolean a = (readInt(b1, s1) == 1) ? true : false;
boolean b = (readInt(b2, s2) == 1) ? true : false;
return ((a == b) ? 0 : (a == false) ? -1 : 1);
}
}
//注冊(cè)
static {
WritableComparator.define(BooleanWritable.class, new Comparator());
}
總結(jié):
hadoop 類(lèi)似于Java的類(lèi)包,即提供了Comparable接口(對(duì)應(yīng)于writableComparable接口)和Comparator類(lèi)(對(duì)應(yīng)于RawComparator類(lèi))用于實(shí)現(xiàn)序列化的比較,在hadoop 的IO包中已經(jīng)封裝了JAVA的基本數(shù)據(jù)類(lèi)型用于序列化和反序列化,一般自己寫(xiě)的類(lèi)實(shí)現(xiàn)序列化和反序列化需要繼承WritableComparable接口并且內(nèi)置一個(gè)Comparator(繼承于WritableComparator)的格式來(lái)實(shí)現(xiàn)自己的對(duì)象。
5.WritableFactory接口 作為工廠模式的WritableFactory,其抽象為一個(gè)接口,提供了具體的Writable對(duì)象創(chuàng)建實(shí)例的抽象方法newInstance(),代碼如下: public interface WritableFactory {
/** Return a new instance. */
Writable newInstance();
}
WritableFactories類(lèi)類(lèi)似于WritableComparator類(lèi)利用HashMap注冊(cè)記錄著所有實(shí)現(xiàn)上述接口的WritableFactory的集合,與之不同的是WritableFactories是一個(gè)單例模式,所有的方法都是靜態(tài)的。關(guān)鍵代碼://提供了一個(gè)key=class,value=WritableFactory的注冊(cè)表
private static final HashMap<Class, WritableFactory> CLASS_TO_FACTORY = new HashMap<Class, WritableFactory>();
public static Writable newInstance(Class<? extends Writable> c, Configuration conf) {
WritableFactory factory = WritableFactories.getFactory(c);
if (factory != null) {
//該方法的newInstanceof是調(diào)用了factory.newInstance()即你了實(shí)現(xiàn)的WritableFactory的newInstance()方法
Writable result = factory.newInstance();
if (result instanceof Configurable) {
((Configurable) result).setConf(conf);
}
return result;
} else {
return ReflectionUtils.newInstance(c, conf);
}
}
6.InputBuffer和DataInputBuffer類(lèi)
類(lèi)似于JAVA.IO 的裝飾器模式, InputBuffer輸入緩沖和DataInputBuffer數(shù)據(jù)緩沖的實(shí)現(xiàn)封裝于內(nèi)部類(lèi)Buffer,該類(lèi)的功能只是提供一個(gè)空的緩沖區(qū),用于存儲(chǔ)數(shù)據(jù)。Buffer代碼如下:
private static class Buffer extends ByteArrayInputStream {
public Buffer() {
super(new byte[] {});
}
public void reset(byte[] input, int start, int length) {
this.buf = input;
this.count = start+length;
this.mark = start;
this.pos = start;
}
public int getPosition() { return pos; }
public int getLength() { return count; }
}
InputBuffer和DataInputBuffer的方法委托于內(nèi)部類(lèi)private Buffer buffer,例如InputBuffer部分代碼:
/** Returns the current position in the input. */
public int getPosition() { return buffer.getPosition(); }
/** Returns the length of the input. */
public int getLength() { return buffer.getLength(); }
DataInputBuffer 內(nèi)置的Buffer代碼如下
private static class Buffer extends ByteArrayInputStream {
public Buffer() {
super(new byte[] {});
}
public void reset(byte[] input, int start, int length) {
this.buf = input;
this.count = start+length;
this.mark = start;
this.pos = start;
}
public byte[] getData() { return buf; }
public int getPosition() { return pos; }
public int getLength() { return count; }
}
兩個(gè)類(lèi)封裝的Buffer一樣,而其方法也都委托依賴于buffer,只是InputBuffer和DataInputBuffer繼承于不同的類(lèi),如下:
DataInputBuffer:
public class DataInputBuffer extends DataInputStream {
}
InputBuffer:
public class InputBuffer extends FilterInputStream {
}
7.OutputBuffer和DataOutputBuffe
類(lèi)似于上文的InputBuffer和DataInputBuffer,hadoop 的OutputBuffer和DataOutputBuffer的實(shí)現(xiàn)與之相似,同樣是利用內(nèi)部類(lèi)的引用,而關(guān)鍵的代碼在于內(nèi)部類(lèi)Buffer:
private static class Buffer extends ByteArrayOutputStream {
public byte[] getData() { return buf; }
public int getLength() { return count; }
public void reset() { count = 0; }
public void write(InputStream in, int len) throws IOException {
int newcount = count + len;
if (newcount > buf.length) {
byte newbuf[] = new byte[Math.max(buf.length << 1, newcount)];
System.arraycopy(buf, 0, newbuf, 0, count);
buf = newbuf;
}
IOUtils.readFully(in, buf, count, len);
count = newcount;
}
}
先是判斷buf數(shù)組的length,倘若空間不足,則new newbuf[] 利用Sysytem的數(shù)組拷貝實(shí)現(xiàn)內(nèi)容的復(fù)制。