NameNode中幾個關鍵的數據結構
FSImage
Namenode會將HDFS的文件和目錄元數據存儲在一個叫fsimage的二進制文件中,每次保存fsimage之后到下次保存之間的所有hdfs操作,將會記錄在editlog文件中,當editlog達到一定的大小(bytes,由fs.checkpoint.size參數定義)或從上次保存過后一定時間段過后(sec,由fs.checkpoint.period參數定義),namenode會重新將內存中對整個HDFS的目錄樹和文件元數據刷到fsimage文件中。Namenode就是通過這種方式來保證HDFS中元數據信息的安全性。
Fsimage是一個二進制文件,當中記錄了HDFS中所有文件和目錄的元數據信息,在我的hadoop的HDFS版中,該文件的中保存文件和目錄的格式如下:

當namenode重啟加載fsimage時,就是按照如下格式協議從文件流中加載元數據信息。從fsimag的存儲格式可以看出,fsimage保存有如下信息:
1. 首先是一個image head,其中包含:
a) imgVersion(int):當前image的版本信息
b) namespaceID(int):用來確保別的HDFS instance中的datanode不會誤連上當前NN。
c) numFiles(long):整個文件系統中包含有多少文件和目錄
d) genStamp(long):生成該image時的時間戳信息。
2. 接下來便是對每個文件或目錄的源數據信息,如果是目錄,則包含以下信息:
a) path(String):該目錄的路徑,如”/user/build/build-index”
b) replications(short):副本數(目錄雖然沒有副本,但這里記錄的目錄副本數也為3)
c) mtime(long):該目錄的修改時間的時間戳信息
d) atime(long):該目錄的訪問時間的時間戳信息
e) blocksize(long):目錄的blocksize都為0
f) numBlocks(int):實際有多少個文件塊,目錄的該值都為-1,表示該item為目錄
g) nsQuota(long):namespace Quota值,若沒加Quota限制則為-1
h) dsQuota(long):disk Quota值,若沒加限制則也為-1
i) username(String):該目錄的所屬用戶名
j) group(String):該目錄的所屬組
k) permission(short):該目錄的permission信息,如644等,有一個short來記錄。
3. 若從fsimage中讀到的item是一個文件,則還會額外包含如下信息:
a) blockid(long):屬于該文件的block的blockid,
b) numBytes(long):該block的大小
c) genStamp(long):該block的時間戳
當該文件對應的numBlocks數不為1,而是大于1時,表示該文件對應有多個block信息,此時緊接在該fsimage之后的就會有多個blockid,numBytes和genStamp信息。
因此,在namenode啟動時,就需要對fsimage按照如下格式進行順序的加載,以將fsimage中記錄的HDFS元數據信息加載到內存中。
BlockMap
從以上fsimage中加載如namenode內存中的信息中可以很明顯的看出,在fsimage中,并沒有記錄每一個block對應到哪幾個datanodes的對應表信息,而只是存儲了所有的關于namespace的相關信息。而真正每個block對應到datanodes列表的信息在hadoop中并沒有進行持久化存儲,而是在所有datanode啟動時,每個datanode對本地磁盤進行掃描,將本datanode上保存的block信息匯報給namenode,namenode在接收到每個datanode的塊信息匯報后,將接收到的塊信息,以及其所在的datanode信息等保存在內存中。HDFS就是通過這種塊信息匯報的方式來完成 block -> datanodes list的對應表構建。Datanode向namenode匯報塊信息的過程叫做blockReport,而namenode將block -> datanodes list的對應表信息保存在一個叫BlocksMap的數據結構中。
BlocksMap的內部數據結構如下:
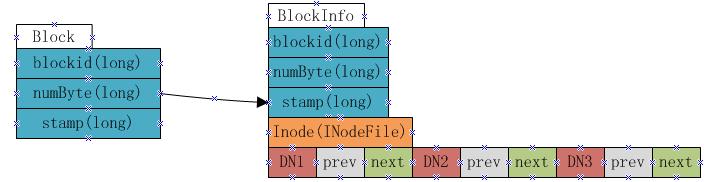
如上圖顯示,BlocksMap實際上就是一個Block對象對BlockInfo對象的一個Map表,其中Block對象中只記錄了blockid,block大小以及時間戳信息,這些信息在fsimage中都有記錄。而BlockInfo是從Block對象繼承而來,因此除了Block對象中保存的信息外,還包括代表該block所屬的HDFS文件的INodeFile對象引用以及該block所屬datanodes列表的信息(即上圖中的DN1,DN2,DN3,該數據結構會在下文詳述)。
因此在namenode啟動并加載fsimage完成之后,實際上BlocksMap中的key,也就是Block對象都已經加載到BlocksMap中,每個key對應的value(BlockInfo)中,除了表示其所屬的datanodes列表的數組為空外,其他信息也都已經成功加載。所以可以說:fsimage加載完畢后,BlocksMap中僅缺少每個塊對應到其所屬的datanodes list的對應關系信息。所缺這些信息,就是通過上文提到的從各datanode接收blockReport來構建。當所有的datanode匯報給namenode的blockReport處理完畢后,BlocksMap整個結構也就構建完成。
BlockMap中datanode列表數據結構
在BlockInfo中,將該block所屬的datanodes列表保存在一個Object[]數組中,但該數組不僅僅保存了datanodes列表,還包含了額外的信息。實際上該數組保存了如下信息:

上圖表示一個block包含有三個副本,分別放置在DN1,DN2和DN3三個datanode上,每個datanode對應一個三元組,該三元組中的第二個元素,即上圖中prev block所指的是該block在該datanode上的前一個BlockInfo引用。第三個元素,也就是上圖中next Block所指的是該block在該datanode上的下一個BlockInfo引用。每個block有多少個副本,其對應的BlockInfo對象中就會有多少個這種三元組。
Namenode采用這種結構來保存block->datanode list的目的在于節約namenode內存。由于namenode將block->datanodes的對應關系保存在了內存當中,隨著HDFS中文件數的增加,block數也會相應的增加,namenode為了保存block->datanodes的信息已經耗費了相當多的內存,如果還像這種方式一樣的保存datanode->block list的對應表,勢必耗費更多的內存,而且在實際應用中,要查一個datanode上保存的block list的應用實際上非常的少,大部分情況下是要根據block來查datanode列表,所以namenode中通過上圖的方式來保存block->datanode list的對應關系,當需要查詢datanode->block list的對應關系時,只需要沿著該數據結構中next Block的指向關系,就能得出結果,而又無需保存datanode->block list在內存中。
NameNode啟動過程
fsimage加載過程
Fsimage加載過程完成的操作主要是為了:
1. 從fsimage中讀取該HDFS中保存的每一個目錄和每一個文件
2. 初始化每個目錄和文件的元數據信息
3. 根據目錄和文件的路徑,構造出整個namespace在內存中的鏡像
4. 如果是文件,則讀取出該文件包含的所有blockid,并插入到BlocksMap中。
整個加載流程如下圖所示:
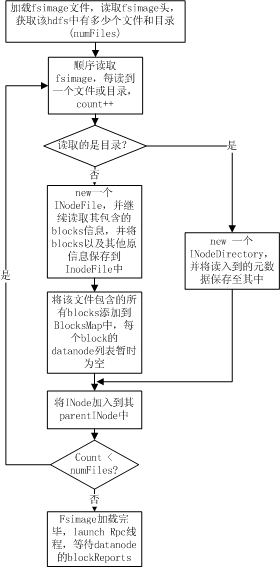
如上圖所示,namenode在加載fsimage過程其實非常簡單,就是從fsimage中不停的順序讀取文件和目錄的元數據信息,并在內存中構建整個namespace,同時將每個文件對應的blockid保存入BlocksMap中,此時BlocksMap中每個block對應的datanodes列表暫時為空。當fsimage加載完畢后,整個HDFS的目錄結構在內存中就已經初始化完畢,所缺的就是每個文件對應的block對應的datanode列表信息。這些信息需要從datanode的blockReport中獲取,所以加載fsimage完畢后,namenode進程進入rpc等待狀態,等待所有的datanodes發送blockReports。
blockReport階段
每個datanode在啟動時都會掃描其機器上對應保存hdfs block的目錄下(dfs.data.dir)所保存的所有文件塊,然后通過namenode的rpc調用將這些block信息以一個long數組的方式發送給namenode,namenode在接收到一個datanode的blockReport rpc調用后,從rpc中解析出block數組,并將這些接收到的blocks插入到BlocksMap表中,由于此時BlocksMap缺少的僅僅是每個block對應的datanode信息,而namenoe能從report中獲知當前report上來的是哪個datanode的塊信息,所以,blockReport過程實際上就是namenode在接收到塊信息匯報后,填充BlocksMap中每個block對應的datanodes列表的三元組信息的過程。其流程如下圖所示:
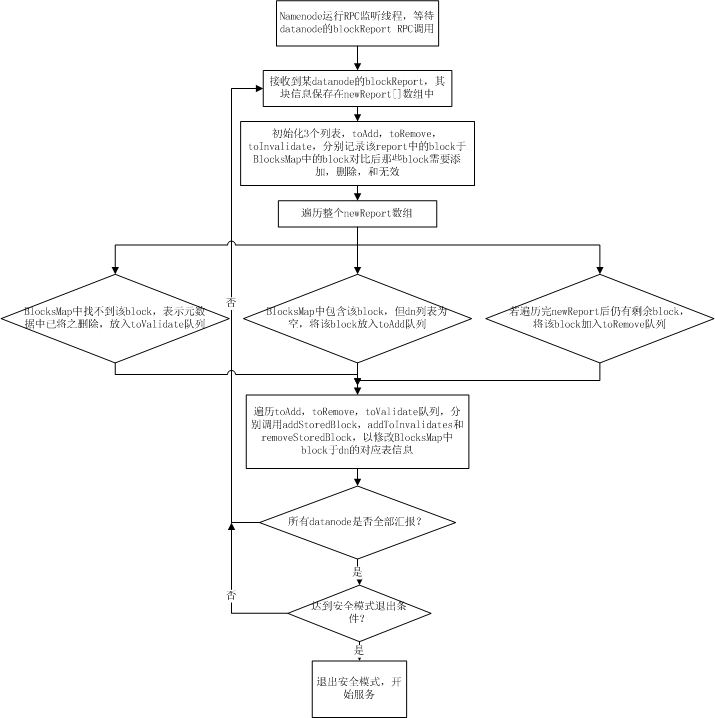
當所有的datanode匯報完block,namenode針對每個datanode的匯報進行過處理后,namenode的啟動過程到此結束。此時BlocksMap中block->datanodes的對應關系已經初始化完畢。如果此時已經達到安全模式的推出閾值,則hdfs主動退出安全模式,開始提供服務。
對namenode的整個啟動過程有了詳細了解之后,就可以對其啟動過程中各階段各函數的調用耗時進行profiling的采集,數據的profiling仍然分為兩個階段,即fsimage加載階段和blockReport階段。
fsimage加載階段性能數據采集和瓶頸分析
以下是對建庫集群真實的fsimage加載過程的的性能采集數據:

從上圖可以看出,fsimage的加載過程那個中,主要耗時的操作分別分布在FSDirectory.addToParent,FSImage.readString,以及PermissionStatus.read三個操作,這三個操作分別占用了加載過程的73%,15%以及8%,加起來總共消耗了整個加載過程的96%。而其中FSImage.readString和PermissionStatus.read操作都是從fsimage的文件流中讀取數據(分別是讀取String和short)的操作,這種操作優化的空間不大,但是通過調整該文件流的Buffer大小來提高少許性能。而FSDirectory.addToParent的調用卻占用了整個加載過程的73%,所以該調用中的優化空間比較大。
以下是addToParent調用中的profiling數據:

從以上數據可以看出addToParent調用占用的73%的耗時中,有66%都耗在了INode.getPathComponents調用上,而這66%分別有36%消耗在INode.getPathNames調用,30%消耗在INode.getPathComponents調用。這兩個耗時操作的具體分布如以下數據所示:
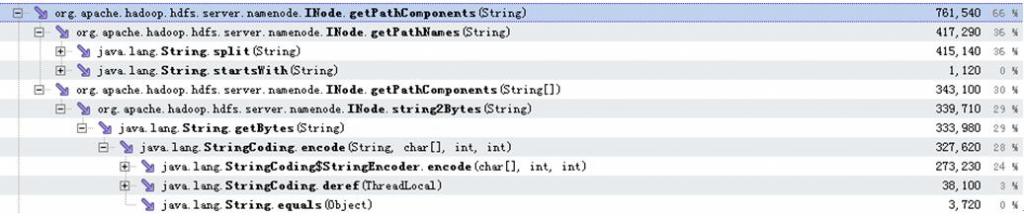
可以看出,消耗了36%的處理時間的INode.getPathNames操作,全部都是在通過String.split函數調用來對文件或目錄路徑進行切分。另外消耗了30%左右的處理時間在INode.getPathComponents中,該函數中最終耗時都耗在獲取字符串的byte數組的java原生操作中。
blockReport階段性能數據采集和瓶頸分析
由于blockReport的調用是通過datanode調用namenode的rpc調用,所以在namenode進入到等待blockreport階段后,會分別開啟rpc調用的監聽線程和rpc調用的處理線程。其中rpc處理和rpc鑒定的調用耗時分布如下圖所示:

而其中rpc的監聽線程的優化是另外一個話題,在其他的issue中再詳細討論,且由于blockReport的操作實際上是觸發的rpc處理線程,所以這里只關心rpc處理線程的性能數據。
在namenode處理blockReport過程中的調用耗時性能數據如下:

可以看出,在namenode啟動階段,處理從各個datanode匯報上來的blockReport耗費了整個rpc處理過程中的絕大部分時間(48/49),blockReport處理邏輯中的耗時分布如下圖:

從上圖數據中可以發現,blockReport階段中耗時分布主要耗時在FSNamesystem.addStoredBlock調用以及DatanodeDescriptor.reportDiff過程中,分別耗時37/48和10/48,其中FSNamesystem.addStoredBlock所進行的操作時對每一個匯報上來的block,將其于匯報上來的datanode的對應關系初始化到namenode內存中的BlocksMap表中。所以對于每一個block就會調用一次該方法。所以可以看到該方法在整個過程中調用了774819次,而另一個耗時的操作,即DatanodeDescriptor.reportDiff,該操作的過程在上文中有詳細介紹,主要是為了將該datanode匯報上來的blocks跟namenode內存中的BlocksMap中進行對比,以決定那個哪些是需要添加到BlocksMap中的block,哪些是需要添加到toRemove隊列中的block,以及哪些是添加到toValidate隊列中的block。由于這個操作需要針對每一個匯報上來的block去查詢BlocksMap,以及namenode中的其他幾個map,所以該過程也非常的耗時。而且從調用次數上可以看出,reportDiff調用在啟動過程中僅調用了14次(有14個datanode進行塊匯報),卻耗費了10/48的時間。所以reportDiff也是整個blockReport過程中非常耗時的瓶頸所在。
同時可以看到,出了reportDiff,addStoredBlock的調用耗費了37%的時間,也就是耗費了整個blockReport時間的37/48,該方法的調用目的是為了將從datanode匯報上來的每一個block插入到BlocksMap中的操作。從該方法調用的運行數據如下圖所示:

從上圖可以看出,addStoredBlock中,主要耗時的兩個階段分別是FSNamesystem.countNode和DatanodeDescriptor.addBlock,后者是java中的插表操作,而FSNamesystem.countNode調用的目的是為了統計在BlocksMap中,每一個block對應的各副本中,有幾個是live狀態,幾個是decommission狀態,幾個是Corrupt狀態。而在namenode的啟動初始化階段,用來保存corrput狀態和decommission狀態的block的map都還是空狀態,并且程序邏輯中要得到的僅僅是出于live狀態的block數,所以,這里的countNoes調用在namenode啟動初始化階段并無需統計每個block對應的副本中的corrrput數和decommission數,而僅僅需要統計live狀態的block副本數即可,這樣countNodes能夠在namenode啟動階段變得更輕量,以節省啟動時間。
瓶頸分析總結
從profiling數據和瓶頸分歧情況來看,fsimage加載階段的瓶頸除了在分切路徑的過程中不夠優以外,其他耗時的地方幾乎都是在java原生接口的調用中,如從字節流讀數據,以及從String對象中獲取byte[]數組的操作。
而blockReport階段的耗時其實很大的原因是跟當前的namenode設計以及內存結構有關,比較明顯的不優之處就是在namenode啟動階段的countNode和reportDiff的必要性,這兩處在namenode初始化時的blockReport階段有一些不必要的操作浪費了時間。可以針對namenode啟動階段將必要的操作抽取出來,定制成namenode啟動階段才調用的方式,以優化namenode啟動性能。
Ref: http://blog.csdn.net/ae86_fc/article/details/5842020