3 字符編碼模型
程序員經(jīng)常會(huì)面對(duì)復(fù)雜的問題,而降低復(fù)雜性的最簡(jiǎn)單的方法就是分而治之。Peter Constable在他的文章"Character set encoding basics Understanding character set encodings and legacy encodings"中描述了字符編碼的四層模型。我覺得這種說法確實(shí)可以更清晰地展現(xiàn)字符編碼中發(fā)生的事情,所以在這里也介紹一下。
3.1 字符的范圍(Abstract character repertoire)
設(shè)計(jì)字符編碼的第一層就是確定字符的范圍,即要支持哪些字符。有些編碼方案的字符范圍是固定的,例如ASCII、ISO 8859 系列。有些編碼方案的字符范圍是開放的,例如Unicode的字符范圍就是世界上所有的字符。
3.2 用數(shù)字表示字符(Coded character set)
設(shè)計(jì)字符編碼的第二層是將字符和數(shù)字對(duì)應(yīng)起來。可以將這個(gè)層次理解成數(shù)學(xué)家(即從數(shù)學(xué)角度)看到的字符編碼。數(shù)學(xué)家看到的字符編碼是一個(gè)正整數(shù)。例如在Unicode中:漢字“字”對(duì)應(yīng)的數(shù)字是23383。漢字“ ”對(duì)應(yīng)的數(shù)字是134192。
”對(duì)應(yīng)的數(shù)字是134192。
在寫html文件時(shí),可以通過輸入"字"來插入字符“字”。不過在設(shè)計(jì)字符編碼時(shí),我們還是習(xí)慣用16進(jìn)制表示數(shù)字。即將23383寫成0x5BD7,將134192寫成0x20C30。
3.3 用基本數(shù)據(jù)類型表示字符(Character encoding form)
設(shè)計(jì)字符編碼的第三層是用編程語言中的基本數(shù)據(jù)類型來表示字符。可以將這個(gè)層次理解成程序員看到的字符編碼。在Unicode中,我們有很多方式將數(shù)字23383表示成程序中的數(shù)據(jù),包括:UTF-8、UTF-16、UTF-32。UTF是“UCS Transformation Format”的縮寫,可以翻譯成Unicode字符集轉(zhuǎn)換格式,即怎樣將Unicode定義的數(shù)字轉(zhuǎn)換成程序數(shù)據(jù)。例如,“漢字”對(duì)應(yīng)的數(shù)字是0x6c49和0x5b57,而編碼的程序數(shù)據(jù)是:
BYTE data_utf8[] = {0xE6, 0xB1, 0x89, 0xE5, 0xAD, 0x97}; // UTF-8編碼
WORD data_utf16[] = {0x6c49, 0x5b57}; // UTF-16編碼
DWORD data_utf32[] = {0x6c49, 0x5b57}; // UTF-32編碼
這里用BYTE、WORD、DWORD分別表示無符號(hào)8位整數(shù),無符號(hào)16位整數(shù)和無符號(hào)32位整數(shù)。UTF-8、UTF-16、UTF-32分別以BYTE、WORD、DWORD作為編碼單位。
“漢字”的UTF-8編碼需要6個(gè)字節(jié)。“漢字”的UTF-16編碼需要兩個(gè)WORD,大小是4個(gè)字節(jié)。“漢字”的UTF-32編碼需要兩個(gè)DWORD,大小是8個(gè)字節(jié)。4.2節(jié)會(huì)介紹將數(shù)字映射到UTF編碼的規(guī)則。
3.4 作為字節(jié)流的字符(Character encoding scheme)
字符編碼的第四層是計(jì)算機(jī)看到的字符,即在文件或內(nèi)存中的字節(jié)流。例如,“字”的UTF-32編碼是0x5b57,如果用little endian表示,字節(jié)流是“57 5b 00 00”。如果用big endian表示,字節(jié)流是“00 00 5b 57”。
字符編碼的第三層規(guī)定了一個(gè)字符由哪些編碼單位按什么順序表示。字符編碼的第四層在第三層的基礎(chǔ)上又考慮了編碼單位內(nèi)部的字節(jié)序。UTF-8的編碼單位是字節(jié),不受字節(jié)序的影響。UTF-16、UTF-32根據(jù)字節(jié)序的不同,又衍生出UTF-16LE、UTF-16BE、UTF-32LE、UTF-32BE四種編碼方案。LE和BE分別是Little Endian和Big Endian的縮寫。
3.5 小結(jié)
通過四層模型,我們又把字符編碼中發(fā)生的這些事情梳理了一遍。其實(shí)大多數(shù)代碼頁都不需要完整的四層模型,例如GB18030以字節(jié)為編碼單位,直接規(guī)定了字節(jié)序列和字符的映射關(guān)系,跳過了第二層,也不需要第四層。
4 再談Unicode
Unicode是國際組織制定的可以容納世界上所有文字和符號(hào)的字符編碼方案。Unicode用數(shù)字0-0x10FFFF來映射這些字符,最多可以容納1114112個(gè)字符,或者說有1114112個(gè)碼位。碼位就是可以分配給字符的數(shù)字。UTF-8、UTF-16、UTF-32都是將數(shù)字轉(zhuǎn)換到程序數(shù)據(jù)的編碼方案。
Unicode字符集可以簡(jiǎn)寫為UCS(Unicode Character Set)。早期的Unicode標(biāo)準(zhǔn)有UCS-2、UCS-4的說法。UCS-2用兩個(gè)字節(jié)編碼,UCS-4用4個(gè)字節(jié)編碼。UCS-4根據(jù)最高位為0的最高字節(jié)分成2^7=128個(gè)group。每個(gè)group再根據(jù)次高字節(jié)分為256個(gè)平面(plane)。每個(gè)平面根據(jù)第3個(gè)字節(jié)分為256行 (row),每行有256個(gè)碼位(cell)。group 0的平面0被稱作BMP(Basic Multilingual Plane)。將UCS-4的BMP去掉前面的兩個(gè)零字節(jié)就得到了UCS-2。
Unicode標(biāo)準(zhǔn)計(jì)劃使用group 0 的17個(gè)平面: 從BMP(平面0)到平面16,即數(shù)字0-0x10FFFF。《談?wù)刄nicode編碼》主要介紹了BMP的編碼,本文將介紹完整的Unicode編碼,并從多個(gè)角度瀏覽Unicode。本文的介紹基于Unicode 5.0.0版本。
4.1 瀏覽Unicode
先看一些數(shù)字:每個(gè)平面有2^16=65536個(gè)碼位。Unicode計(jì)劃使用了17個(gè)平面,一共有17*65536=1114112個(gè)碼位。其實(shí),現(xiàn)在已定義的碼位只有238605個(gè),分布在平面0、平面1、平面2、平面14、平面15、平面16。其中平面15和平面16上只是定義了兩個(gè)各占65534個(gè)碼位的專用區(qū)(Private Use Area),分別是0xF0000-0xFFFFD和0x100000-0x10FFFD。所謂專用區(qū),就是保留給大家放自定義字符的區(qū)域,可以簡(jiǎn)寫為PUA。
平面0也有一個(gè)專用區(qū):0xE000-0xF8FF,有6400個(gè)碼位。平面0的0xD800-0xDFFF,共2048個(gè)碼位,是一個(gè)被稱作代理區(qū)(Surrogate)的特殊區(qū)域。它的用途將在4.2節(jié)介紹。
238605-65534*2-6400-2408=99089。余下的99089個(gè)已定義碼位分布在平面0、平面1、平面2和平面14上,它們對(duì)應(yīng)著Unicode目前定義的99089個(gè)字符,其中包括71226個(gè)漢字。平面0、平面1、平面2和平面14上分別定義了52080、3419、43253和337個(gè)字符。平面2的43253個(gè)字符都是漢字。平面0上定義了27973個(gè)漢字。
在更深入地了解Unicode字符前,我們先了解一下UCD。
4.1.1 什么是UCD
UCD是Unicode字符數(shù)據(jù)庫(Unicode Character Database)的縮寫。UCD由一些描述Unicode字符屬性和內(nèi)部關(guān)系的純文本或html文件組成。大家可以在Unicode組織的網(wǎng)站看到UCD的最新版本。
UCD中的文本文件大都是適合于程序分析的Unicode相關(guān)數(shù)據(jù)。其中的html文件解釋了數(shù)據(jù)庫的組織,數(shù)據(jù)的格式和含義。UCD中最龐大的文件無疑就是描述漢字屬性的文件Unihan.txt。在UCD 5.0,0中,Unihan.txt文件大小有28,221K字節(jié)。Unihan.txt中包含了很多有參考價(jià)值的索引,例如漢字部首、筆劃、拼音、使用頻度、四角號(hào)碼排序等。這些索引都是基于一些比較權(quán)威的辭典,但大多數(shù)索引只能檢索部分漢字。
我介紹UCD的目的主要是為了使用其中的兩個(gè)概念:Block和Script。
4.1.2 Block
UCD中的Blocks.txt將Unicode的碼位分割成一些連續(xù)的Block,并描述了每個(gè)Block的用途:
| 開始碼位 | 結(jié)束碼位 | Block名稱(英文) | Block名稱(中文) |
| 0000 | 007F | Basic Latin | 基本拉丁字母 |
| 0080 | 00FF | Latin-1 Supplement | 拉丁字母補(bǔ)充-1 |
| 0100 | 017F | Latin Extended-A | 拉丁字母擴(kuò)充-A |
| 0180 | 024F | Latin Extended-B | 拉丁字母擴(kuò)充-B |
| 0250 | 02AF | IPA Extensions | 國際音標(biāo)擴(kuò)充 |
| 02B0 | 02FF | Spacing Modifier Letters | 進(jìn)格修飾字符 |
| 0300 | 036F | Combining Diacritical Marks | 組合附加符號(hào) |
| 0370 | 03FF | Greek and Coptic | 希臘文和哥普特文 |
| 0400 | 04FF | Cyrillic | 西里爾文 |
| 0500 | 052F | Cyrillic Supplement | 西里爾文補(bǔ)充 |
| 0530 | 058F | Armenian | 亞美尼亞文 |
| 0590 | 05FF | Hebrew | 希伯來文 |
| 0600 | 06FF | Arabic | 基本阿拉伯文 |
| 0700 | 074F | Syriac | 敘利亞文 |
| 0750 | 077F | Arabic Supplement | 阿拉伯文補(bǔ)充 |
| 0780 | 07BF | Thaana | 塔納文 |
| 07C0 | 07FF | NKo | N'Ko字母表 |
| 0900 | 097F | Devanagari | 天成文書(梵文) |
| 0980 | 09FF | Bengali | 孟加拉文 |
| 0A00 | 0A7F | Gurmukhi | 錫克教文 |
| 0A80 | 0AFF | Gujarati | 古吉拉特文 |
| 0B00 | 0B7F | Oriya | 奧里亞文 |
| 0B80 | 0BFF | Tamil | 泰米爾文 |
| 0C00 | 0C7F | Telugu | 泰盧固文 |
| 0C80 | 0CFF | Kannada | 卡納達(dá)文 |
| 0D00 | 0D7F | Malayalam | 德拉維族文 |
| 0D80 | 0DFF | Sinhala | 僧伽羅文 |
| 0E00 | 0E7F | Thai | 泰文 |
| 0E80 | 0EFF | Lao | 老撾文 |
| 0F00 | 0FFF | Tibetan | 藏文 |
| 1000 | 109F | Myanmar | 緬甸文 |
| 10A0 | 10FF | Georgian | 格魯吉亞文 |
| 1100 | 11FF | Hangul Jamo | 朝鮮文 |
| 1200 | 137F | Ethiopic | 埃塞俄比亞文 |
| 1380 | 139F | Ethiopic Supplement | 埃塞俄比亞文補(bǔ)充 |
| 13A0 | 13FF | Cherokee | 切羅基文 |
| 1400 | 167F | Unified Canadian Aboriginal Syllabics | 加拿大印第安方言 |
| 1680 | 169F | Ogham | 歐甘文 |
| 16A0 | 16FF | Runic | 北歐古字 |
| 1700 | 171F | Tagalog | 塔加路文 |
| 1720 | 173F | Hanunoo | 哈努諾文 |
| 1740 | 175F | Buhid | 布迪文 |
| 1760 | 177F | Tagbanwa | Tagbanwa文 |
| 1780 | 17FF | Khmer | 高棉文 |
| 1800 | 18AF | Mongolian | 蒙古文 |
| 1900 | 194F | Limbu | 林布文 |
| 1950 | 197F | Tai Le | 德宏傣文 |
| 1980 | 19DF | New Tai Lue | 新傣文 |
| 19E0 | 19FF | Khmer Symbols | 高棉文 |
| 1A00 | 1A1F | Buginese | 布吉文 |
| 1B00 | 1B7F | Balinese | 巴厘文 |
| 1D00 | 1D7F | Phonetic Extensions | 拉丁字母音標(biāo)擴(kuò)充 |
| 1D80 | 1DBF | Phonetic Extensions Supplement | 拉丁字母音標(biāo)擴(kuò)充增補(bǔ) |
| 1DC0 | 1DFF | Combining Diacritical Marks Supplement | 組合附加符號(hào)補(bǔ)充 |
| 1E00 | 1EFF | Latin Extended Additional | 拉丁字母擴(kuò)充附加 |
| 1F00 | 1FFF | Greek Extended | 希臘文擴(kuò)充 |
| 2000 | 206F | General Punctuation | 一般標(biāo)點(diǎn)符號(hào) |
| 2070 | 209F | Superscripts and Subscripts | 上標(biāo)和下標(biāo) |
| 20A0 | 20CF | Currency Symbols | 貨幣符號(hào) |
| 20D0 | 20FF | Combining Diacritical Marks for Symbols | 符號(hào)用組合附加符號(hào) |
| 2100 | 214F | Letterlike Symbols | 似字母符號(hào) |
| 2150 | 218F | Number Forms | 數(shù)字形式 |
| 2190 | 21FF | Arrows | 箭頭符號(hào) |
| 2200 | 22FF | Mathematical Operators | 數(shù)學(xué)運(yùn)算符號(hào) |
| 2300 | 23FF | Miscellaneous Technical | 零雜技術(shù)用符號(hào) |
| 2400 | 243F | Control Pictures | 控制圖符 |
| 2440 | 245F | Optical Character Recognition | 光學(xué)字符識(shí)別 |
| 2460 | 24FF | Enclosed Alphanumerics | 帶括號(hào)的字母數(shù)字 |
| 2500 | 257F | Box Drawing | 制表符 |
| 2580 | 259F | Block Elements | 方塊元素 |
| 25A0 | 25FF | Geometric Shapes | 幾何形狀 |
| 2600 | 26FF | Miscellaneous Symbols | 零雜符號(hào) |
| 2700 | 27BF | Dingbats | 雜錦字型 |
| 27C0 | 27EF | Miscellaneous Mathematical Symbols-A | 零雜數(shù)學(xué)符號(hào)-A |
| 27F0 | 27FF | Supplemental Arrows-A | 箭頭符號(hào)補(bǔ)充-A |
| 2800 | 28FF | Braille Patterns | 盲文 |
| 2900 | 297F | Supplemental Arrows-B | 箭頭符號(hào)補(bǔ)充-B |
| 2980 | 29FF | Miscellaneous Mathematical Symbols-B | 零雜數(shù)學(xué)符號(hào)-B |
| 2A00 | 2AFF | Supplemental Mathematical Operators | 數(shù)學(xué)運(yùn)算符號(hào) |
| 2B00 | 2BFF | Miscellaneous Symbols and Arrows | 零雜符號(hào)和箭頭 |
| 2C00 | 2C5F | Glagolitic | 格拉哥里字母表 |
| 2C60 | 2C7F | Latin Extended-C | 拉丁字母擴(kuò)充-C |
| 2C80 | 2CFF | Coptic | 科普特文 |
| 2D00 | 2D2F | Georgian Supplement | 格魯吉亞文補(bǔ)充 |
| 2D30 | 2D7F | Tifinagh | 提非納字母 |
| 2D80 | 2DDF | Ethiopic Extended | 埃塞俄比亞文擴(kuò)充 |
| 2E00 | 2E7F | Supplemental Punctuation | 標(biāo)點(diǎn)符號(hào)補(bǔ)充 |
| 2E80 | 2EFF | CJK Radicals Supplement | 中日韓部首補(bǔ)充 |
| 2F00 | 2FDF | Kangxi Radicals | 康熙字典部首 |
| 2FF0 | 2FFF | Ideographic Description Characters | 漢字結(jié)構(gòu)描述字符 |
| 3000 | 303F | CJK Symbols and Punctuation | 中日韓符號(hào)和標(biāo)點(diǎn) |
| 3040 | 309F | Hiragana | 平假名 |
| 30A0 | 30FF | Katakana | 片假名 |
| 3100 | 312F | Bopomofo | 注音符號(hào) |
| 3130 | 318F | Hangul Compatibility Jamo | 朝鮮文兼容字母 |
| 3190 | 319F | Kanbun | 日文的漢字批注 |
| 31A0 | 31BF | Bopomofo Extended | 注音符號(hào)擴(kuò)充 |
| 31C0 | 31EF | CJK Strokes | 中日韓筆劃 |
| 31F0 | 31FF | Katakana Phonetic Extensions | 片假名音標(biāo)擴(kuò)充 |
| 3200 | 32FF | Enclosed CJK Letters and Months | 帶括號(hào)的中日韓字母及月份 |
| 3300 | 33FF | CJK Compatibility | 中日韓兼容字符 |
| 3400 | 4DBF | CJK Unified Ideographs Extension A | 中日韓統(tǒng)一表意文字?jǐn)U充A |
| 4DC0 | 4DFF | Yijing Hexagram Symbols | 易經(jīng)六十四卦象 |
| 4E00 | 9FFF | CJK Unified Ideographs | 中日韓統(tǒng)一表意文字 |
| A000 | A48F | Yi Syllables | 彝文音節(jié) |
| A490 | A4CF | Yi Radicals | 彝文字根 |
| A700 | A71F | Modifier Tone Letters | 聲調(diào)修飾字母 |
| A720 | A7FF | Latin Extended-D | 拉丁字母擴(kuò)充-D |
| A800 | A82F | Syloti Nagri | Syloti Nagri字母表 |
| A840 | A87F | Phags-pa | Phags-pa字母表 |
| AC00 | D7AF | Hangul Syllables | 朝鮮文音節(jié) |
| D800 | DB7F | High Surrogates | 高位替代 |
| DB80 | DBFF | High Private Use Surrogates | 高位專用替代 |
| DC00 | DFFF | Low Surrogates | 低位替代 |
| E000 | F8FF | Private Use Area | 專用區(qū) |
| F900 | FAFF | CJK Compatibility Ideographs | 中日韓兼容表意文字 |
| FB00 | FB4F | Alphabetic Presentation Forms | 字母變體顯現(xiàn)形式 |
| FB50 | FDFF | Arabic Presentation Forms-A | 阿拉伯文變體顯現(xiàn)形式-A |
| FE00 | FE0F | Variation Selectors | 字型變換選取器 |
| FE10 | FE1F | Vertical Forms | 豎排標(biāo)點(diǎn)符號(hào) |
| FE20 | FE2F | Combining Half Marks | 組合半角標(biāo)示 |
| FE30 | FE4F | CJK Compatibility Forms | 中日韓兼容形式 |
| FE50 | FE6F | Small Form Variants | 小型變體形式 |
| FE70 | FEFF | Arabic Presentation Forms-B | 阿拉伯文變體顯現(xiàn)形式-B |
| FF00 | FFEF | Halfwidth and Fullwidth Forms | 半角及全角字符 |
| FFF0 | FFFF | Specials | 特殊區(qū)域 |
| 10000 | 1007F | Linear B Syllabary | 線形文字B音節(jié)文字 |
| 10080 | 100FF | Linear B Ideograms | 線形文字B表意文字 |
| 10100 | 1013F | Aegean Numbers | 愛琴海數(shù)字 |
| 10140 | 1018F | Ancient Greek Numbers | 古希臘數(shù)字 |
| 10300 | 1032F | Old Italic | 古意大利文 |
| 10330 | 1034F | Gothic | 哥特文 |
| 10380 | 1039F | Ugaritic | 烏加里特楔形文字 |
| 103A0 | 103DF | Old Persian | 古波斯文 |
| 10400 | 1044F | Deseret | 德塞雷特大學(xué)音標(biāo) |
| 10450 | 1047F | Shavian | 肅伯納速記符號(hào) |
| 10480 | 104AF | Osmanya | Osmanya字母表 |
| 10800 | 1083F | Cypriot Syllabary | 塞浦路斯音節(jié)文字 |
| 10900 | 1091F | Phoenician | 腓尼基文 |
| 10A00 | 10A5F | Kharoshthi | 迦婁士悌文 |
| 12000 | 123FF | Cuneiform | 楔形文字 |
| 12400 | 1247F | Cuneiform Numbers and Punctuation | 楔形文字?jǐn)?shù)字和標(biāo)點(diǎn) |
| 1D000 | 1D0FF | Byzantine Musical Symbols | 東正教音樂符號(hào) |
| 1D100 | 1D1FF | Musical Symbols | 音樂符號(hào) |
| 1D200 | 1D24F | Ancient Greek Musical Notation | 古希臘音樂符號(hào) |
| 1D300 | 1D35F | Tai Xuan Jing Symbols | 太玄經(jīng)符號(hào) |
| 1D360 | 1D37F | Counting Rod Numerals | 算籌 |
| 1D400 | 1D7FF | Mathematical Alphanumeric Symbols | 數(shù)學(xué)用字母數(shù)字符號(hào) |
| 20000 | 2A6DF | CJK Unified Ideographs Extension B | 中日韓統(tǒng)一表意文字?jǐn)U充 B |
| 2F800 | 2FA1F | CJK Compatibility Ideographs Supplement | 中日韓兼容表意文字補(bǔ)充 |
| E0000 | E007F | Tags | 標(biāo)簽 |
| E0100 | E01EF | Variation Selectors Supplement | 字型變換選取器補(bǔ)充 |
| F0000 | FFFFF | Supplementary Private Use Area-A | 補(bǔ)充專用區(qū)-A |
| 100000 | 10FFFF | Supplementary Private Use Area-B | 補(bǔ)充專用區(qū)-B |
Block是Unicode字符的一個(gè)屬性。屬于同一個(gè)Block的字符有著相近的用途。Block表中的開始碼位、結(jié)束碼位只是用來劃分出一塊區(qū)域,在開始碼位和結(jié)束碼位之間可能還有很多未定義的碼位。使用UniToy,大家可以按照Block瀏覽Unicode字符,既可以按列表顯示:
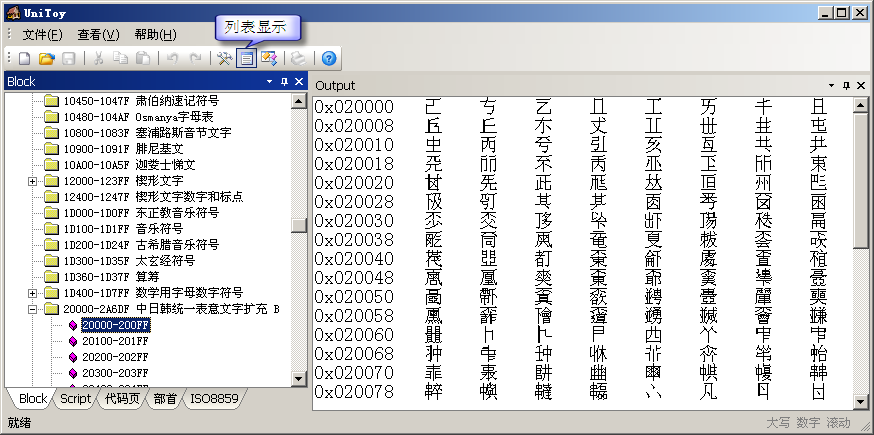
也可以顯示每個(gè)字符的詳細(xì)信息: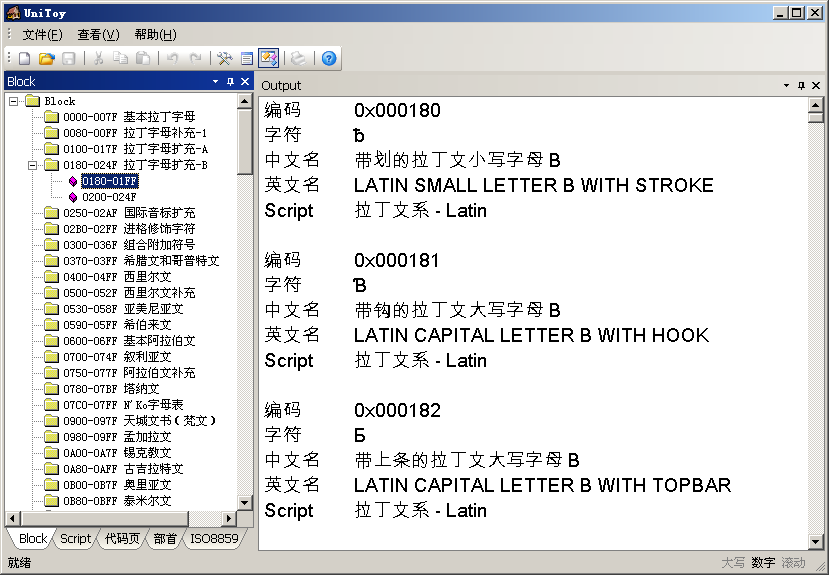
4.1.3 Script
Unicode中每個(gè)字符都有一個(gè)Script屬性,這個(gè)屬性表明字符所屬的文字系統(tǒng)。Unicode目前支持以下Script:
| Script名稱(英文) | Script名稱(中文) | Script包含的字符數(shù) |
| Arabic | 阿拉伯文 | 966 |
| Armenian | 亞美尼亞文 | 90 |
| Balinese | 巴厘文 | 121 |
| Bengali | 孟加拉文 | 91 |
| Bopomofo | 漢語注音符號(hào) | 64 |
| Braille | 盲文 | 256 |
| Buginese | 布吉文 | 30 |
| Buhid | 布迪文 | 20 |
| Canadian Aboriginal | 加拿大印第安方言 | 630 |
| Cherokee | 切羅基文 | 85 |
| Common | Common | 5020 |
| Coptic | 科普特文 | 128 |
| Cuneiform | 楔形文字 | 982 |
| Cypriot | 塞浦路斯音節(jié)文字 | 55 |
| Cyrillic | 西里爾文 | 277 |
| Deseret | 德塞雷特大學(xué)音標(biāo) | 80 |
| Devanagari | 天成文書(梵文) | 107 |
| Ethiopic | 埃塞俄比亞文 | 461 |
| Georgian | 格魯吉亞文 | 120 |
| Gothic | 哥特文 | 94 |
| Glagolitic | 格拉哥里字母表 | 27 |
| Greek | 希臘文 | 506 |
| Gujarati | 古吉拉特文 | 83 |
| Gurmukhi | 錫克教文 | 77 |
| Han | 漢文 | 71570 |
| Hangul | 韓文書寫系統(tǒng) | 11619 |
| Hanunoo | 哈努諾文 | 21 |
| Hebrew | 希伯來文 | 133 |
| Hiragana | 平假名 | 89 |
| Inherited | Inherited | 461 |
| Kannada | 卡納達(dá)文 | 86 |
| Katakana | 片假名 | 164 |
| Kharoshthi | 迦婁士悌文 | 65 |
| Khmer | 高棉文 | 146 |
| Lao | 老撾文 | 65 |
| Latin | 拉丁文系 | 1070 |
| Limbu | 林布文(尼泊爾東部) | 66 |
| Linear B | 線形文字B | 211 |
| Malayalam | 德拉維族文(印度) | 78 |
| Mongolian | 蒙古文 | 152 |
| Myanmar | 緬甸文 | 78 |
| New Tai Lue | 新傣文 | 80 |
| Nko | N'Ko字母表 | 59 |
| Ogham | 歐甘文字 | 29 |
| Old Italic | 古意大利文 | 35 |
| Old Persian | 古波斯文 | 50 |
| Oriya | 奧里亞文 | 81 |
| Osmanya | Osmanya字母表 | 40 |
| Phags Pa | Phags Pa字母表(蒙古) | 56 |
| Phoenician | 腓尼基文 | 27 |
| Runic | 古代北歐文 | 78 |
| Shavian | 肅伯納速記符號(hào) | 48 |
| Sinhala | 僧伽羅文 | 80 |
| Syloti Nagri | Syloti Nagri字母表(印度) | 44 |
| Syriac | 敘利亞文 | 77 |
| Tagalog | 塔加路文(菲律賓) | 20 |
| Tagbanwa | Tagbanwa文(菲律賓) | 18 |
| Tai Le | 德宏傣文 | 35 |
| Tamil | 泰米爾文 | 71 |
| Telugu | 泰盧固文(印度) | 80 |
| Thaana | 馬爾代夫書寫體 | 50 |
| Thai | 泰國文 | 86 |
| Tibetan | 藏文 | 195 |
| Tifinagh | 提非納字母表 | 55 |
| Ugaritic | 烏加里特楔形文字 | 31 |
| Yi | 彝文 | 1220 |
其中,有兩個(gè)Script值有著特殊的含義:
- Common:Script屬性為Common的字符可能在多個(gè)文字系統(tǒng)中使用,不是某個(gè)文字系統(tǒng)特有的。例如:空格、數(shù)字等。
- Inherited:Script屬性為Inherited的字符會(huì)繼承前一個(gè)字符的Script屬性。主要是一些組合用符號(hào),例如:在“組合附加符號(hào)”區(qū)(0x300-0x36f),字符的Script屬性都是Inherited。
UCD中的Script.txt列出了每個(gè)字符的Script屬性。使用UniToy可以按照Script屬性查看字符。例如:
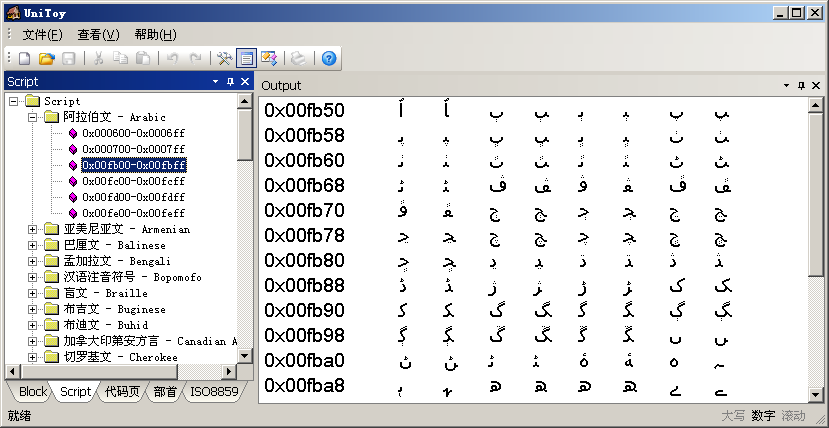
左側(cè)Script窗口中,第一層節(jié)點(diǎn)是按英文字母順序排列的Script屬性。第二層節(jié)點(diǎn)是包含該Script文字的行(row),點(diǎn)擊后顯示該行內(nèi)屬于這個(gè)Script的字符。這樣,就可以集中查看屬于同一文字系統(tǒng)的字符。
4.1.4 Unicode中的漢字
前面提過,在Unicode已定義的99089個(gè)字符中,有71226個(gè)字符是漢字。它們的分布如下:
| Block名稱 | 開始碼位 | 結(jié)束碼位 | 數(shù)量 |
| 中日韓統(tǒng)一表意文字?jǐn)U充A | 3400 | 4db5 | 6582 | |
| 中日韓統(tǒng)一表意文字 | 4e00 | 9fbb | 20924 | |
| 中日韓兼容表意文字 | f900 | fa2d | 302 | |
| 中日韓兼容表意文字 | fa30 | fa6a | 59 | |
| 中日韓兼容表意文字 | fa70 | fad9 | 106 |
| 中日韓統(tǒng)一表意文字?jǐn)U充B | 20000 | 2a6d6 | 42711 | |
| 中日韓兼容表意文字補(bǔ)充 | 2f800 | 2fa1d | 542 |
UCD的Unihan.txt中的部首偏旁索引(kRSUnicode)可以檢索全部71226個(gè)漢字。kRSUnicode的部首是按照康熙字典定義的,共214個(gè)部首。簡(jiǎn)體字按照簡(jiǎn)體部首對(duì)應(yīng)的繁體部首檢索。UniToy整理了康熙字典部首對(duì)應(yīng)的簡(jiǎn)體部首,提供了按照部首檢索漢字的功能:
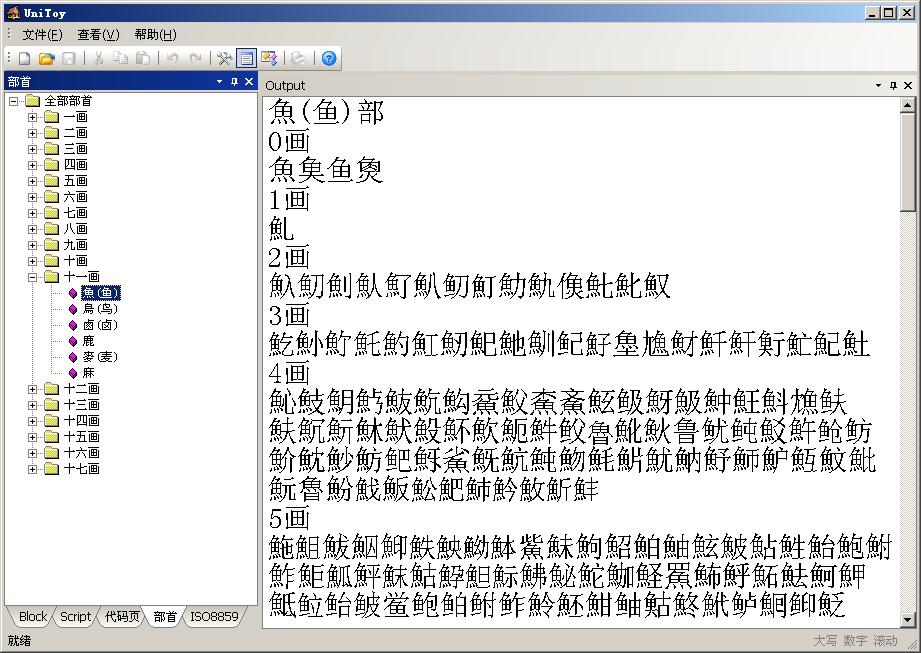
4.2 UTF編碼
在字符編碼的四個(gè)層次中,第一層的范圍和第二層的編碼在4.1節(jié)已經(jīng)詳細(xì)討論過了。本節(jié)討論第三層的UTF編碼和第四層的字節(jié)序,主要談?wù)劦谌龑拥腢TF編碼,即怎樣將Unicode定義的編碼轉(zhuǎn)換成程序數(shù)據(jù)。
4.2.1 UTF-8
UTF-8以字節(jié)為單位對(duì)Unicode進(jìn)行編碼。從Unicode到UTF-8的編碼方式如下:
| Unicode編碼(16進(jìn)制) | UTF-8 字節(jié)流(二進(jìn)制) |
| 000000 - 00007F | 0xxxxxxx |
| 000080 - 0007FF | 110xxxxx 10xxxxxx |
| 000800 - 00FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 010000 - 10FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
UTF-8的特點(diǎn)是對(duì)不同范圍的字符使用不同長(zhǎng)度的編碼。對(duì)于0x00-0x7F之間的字符,UTF-8編碼與ASCII編碼完全相同。UTF-8編碼的最大長(zhǎng)度是4個(gè)字節(jié)。從上表可以看出,4字節(jié)模板有21個(gè)x,即可以容納21位二進(jìn)制數(shù)字。Unicode的最大碼位0x10FFFF也只有21位。
例1:“漢”字的Unicode編碼是0x6C49。0x6C49在0x0800-0xFFFF之間,使用用3字節(jié)模板了:1110xxxx 10xxxxxx 10xxxxxx。將0x6C49寫成二進(jìn)制是:0110 1100 0100 1001, 用這個(gè)比特流依次代替模板中的x,得到:11100110 10110001 10001001,即E6 B1 89。
例2:“”字的Unicode編碼是0x20C30。0x20C30在0x010000-0x10FFFF之間,使用用4字節(jié)模板了:11110xxx 10xxxxxx 10xxxxxx 10xxxxxx。將0x20C30寫成21位二進(jìn)制數(shù)字(不足21位就在前面補(bǔ)0):0 0010 0000 1100 0011 0000,用這個(gè)比特流依次代替模板中的x,得到:11110000 10100000 10110000 10110000,即F0 A0 B0 B0。
4.2.2 UTF-16
UniToy有個(gè)“輸出編碼”功能,可以輸出當(dāng)前選擇的文本編碼。因?yàn)閁niToy內(nèi)部采用UTF-16編碼,所以輸出的編碼就是文本的UTF-16編碼。例如:如果我們輸出“漢”字的UTF-16編碼,可以看到0x6C49,這與“漢”字的Unicode編碼是一致的。如果我們輸出“”字的UTF-16編碼,可以看到0xD843, 0xDC30。“”字的Unicode編碼是0x20C30,它的UTF-16編碼是怎樣得到的呢?
4.2.2.1 編碼規(guī)則
UTF-16編碼以16位無符號(hào)整數(shù)為單位。我們把Unicode編碼記作U。編碼規(guī)則如下:
- 如果U<0x10000,U的UTF-16編碼就是U對(duì)應(yīng)的16位無符號(hào)整數(shù)(為書寫簡(jiǎn)便,下文將16位無符號(hào)整數(shù)記作WORD)。
- 如果U≥0x10000,我們先計(jì)算U'=U-0x10000,然后將U'寫成二進(jìn)制形式:yyyy yyyy yyxx xxxx xxxx,U的UTF-16編碼(二進(jìn)制)就是:110110yyyyyyyyyy110111xxxxxxxxxx。
為什么U'可以被寫成20個(gè)二進(jìn)制位?Unicode的最大碼位是0x10ffff,減去0x10000后,U'的最大值是0xfffff,所以肯定可以用20個(gè)二進(jìn)制位表示。例如:“”字的Unicode編碼是0x20C30,減去0x10000后,得到0x10C30,寫成二進(jìn)制是:0001 0000 1100 0011 0000。用前10位依次替代模板中的y,用后10位依次替代模板中的x,就得到:1101100001000011 1101110000110000,即0xD843 0xDC30。
4.2.2.2 代理區(qū)(Surrogate)
按照上述規(guī)則,Unicode編碼0x10000-0x10FFFF的UTF-16編碼有兩個(gè)WORD,第一個(gè)WORD的高6位是110110,第二個(gè)WORD的高6位是110111。可見,第一個(gè)WORD的取值范圍(二進(jìn)制)是11011000 00000000到11011011 11111111,即0xD800-0xDBFF。第二個(gè)WORD的取值范圍(二進(jìn)制)是11011100 00000000到11011111 11111111,即0xDC00-0xDFFF。
為了將一個(gè)WORD的UTF-16編碼與兩個(gè)WORD的UTF-16編碼區(qū)分開來,Unicode編碼的設(shè)計(jì)者將0xD800-0xDFFF保留下來,并稱為代理區(qū)(Surrogate):
| D800 | DB7F | High Surrogates | 高位替代 |
| DB80 | DBFF | High Private Use Surrogates | 高位專用替代 |
| DC00 | DFFF | Low Surrogates | 低位替代 |
高位替代就是指這個(gè)范圍的碼位是兩個(gè)WORD的UTF-16編碼的第一個(gè)WORD。低位替代就是指這個(gè)范圍的碼位是兩個(gè)WORD的UTF-16編碼的第二個(gè)WORD。那么,高位專用替代是什么意思?我們來解答這個(gè)問題,順便看看怎么由UTF-16編碼推導(dǎo)Unicode編碼。
解:如果一個(gè)字符的UTF-16編碼的第一個(gè)WORD在0xDB80到0xDBFF之間,那么它的Unicode編碼在什么范圍內(nèi)?我們知道第二個(gè)WORD的取值范圍是0xDC00-0xDFFF,所以這個(gè)字符的UTF-16編碼范圍應(yīng)該是0xDB80 0xDC00到0xDBFF 0xDFFF。我們將這個(gè)范圍寫成二進(jìn)制:
1101101110000000 11011100 00000000 - 1101101111111111 1101111111111111
按照編碼的相反步驟,取出高低WORD的后10位,并拼在一起,得到
1110 0000 0000 0000 0000 - 1111 1111 1111 1111 1111
即0xe0000-0xfffff,按照編碼的相反步驟再加上0x10000,得到0xf0000-0x10ffff。這就是UTF-16編碼的第一個(gè)WORD在0xdb80到0xdbff之間的Unicode編碼范圍,即平面15和平面16。因?yàn)閁nicode標(biāo)準(zhǔn)將平面15和平面16都作為專用區(qū),所以0xDB80到0xDBFF之間的保留碼位被稱作高位專用替代。
4.2.3 UTF-32
UTF-32編碼以32位無符號(hào)整數(shù)為單位。Unicode的UTF-32編碼就是其對(duì)應(yīng)的32位無符號(hào)整數(shù)。
4.2.4 字節(jié)序
根據(jù)字節(jié)序的不同,UTF-16可以被實(shí)現(xiàn)為UTF-16LE或UTF-16BE,UTF-32可以被實(shí)現(xiàn)為UTF-32LE或UTF-32BE。例如:
| 字符 | Unicode編碼 | UTF-16LE | UTF-16BE | UTF32-LE | UTF32-BE |
| 漢 | 0x6C49 | 49 6C | 6C 49 | 49 6C 00 00 | 00 00 6C 49 |
| 0x20C30 | 43 D8 30 DC | D8 43 DC 30 | 30 0C 02 00 | 00 02 0C 30 |
那么,怎么判斷字節(jié)流的字節(jié)序呢?
Unicode標(biāo)準(zhǔn)建議用BOM(Byte Order Mark)來區(qū)分字節(jié)序,即在傳輸字節(jié)流前,先傳輸被作為BOM的字符"零寬無中斷空格"。這個(gè)字符的編碼是FEFF,而反過來的FFFE(UTF-16)和FFFE0000(UTF-32)在Unicode中都是未定義的碼位,不應(yīng)該出現(xiàn)在實(shí)際傳輸中。下表是各種UTF編碼的BOM:
| UTF編碼 | Byte Order Mark |
| UTF-8 | EF BB BF |
| UTF-16LE | FF FE |
| UTF-16BE | FE FF |
| UTF-32LE | FF FE 00 00 |
| UTF-32BE | 00 00 FE FF |
5 結(jié)束語
程序員的工作就是將復(fù)雜的世界簡(jiǎn)單地表達(dá)出來,希望這篇文章也能做到這一點(diǎn)。本文的初稿完成于2007年2月14日。我會(huì)在我的個(gè)人主頁http://www.fmddlmyy.cn維護(hù)這篇文章的最新版本。