文章中引用的代碼均來自https://github.com/vczh/tinymoe。
?
看了前面的三篇文章,大家應(yīng)該基本對Tinymoe的代碼有一個初步的感覺了。在正確分析"print sum from 1 to 100"之前,我們首先得分析"phrase sum from (lower bound) to (upper bound)"這樣的聲明。Tinymoe的函數(shù)聲明又很多關(guān)于block和sentence的配置,不過這里并不打算將所有細(xì)節(jié),我會將重點(diǎn)放在如何寫一個針對無歧義語法的遞歸下降語法分析器上。所以我們這里不會涉及sentence和block的什么category和cps的配置。
?
雖然"print sum from 1 to 100"無法用無歧義的語法分析的方法做出來,但是我們可以借用對"phrase sum from (lower bound) to (upper bound)"的語法分析的結(jié)果,動態(tài)構(gòu)造能夠分析"print sum from 1 to 100"的語法分析器。這種說法看起來好像很高大上,但是其實并沒有什么特別難的技巧。關(guān)于"構(gòu)造"的問題我將在下一篇文章《跟vczh看實例學(xué)編譯原理——三:Tinymoe與有歧義語法分析》詳細(xì)介紹。
?
在我之前的博客里我曾經(jīng)寫過《如何手寫語法分析器》,這篇文章講了一些簡單的寫遞歸下降語法分析器的規(guī)則,盡管很多人來信說這篇文章幫他們解決了很多問題,但實際上細(xì)節(jié)還不夠豐富,用來對編程語言做語法分析的話,還是會覺得復(fù)雜性太高。這篇文章也同時作為《如何手寫語法分析器》的補(bǔ)充。好了,我們開始進(jìn)入無歧義語法分析的主題吧。
?
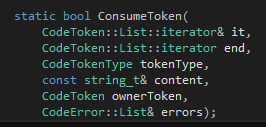
我們需要的第一個函數(shù)是用來讀token并判斷其內(nèi)容是不是我們希望看到的東西。這個函數(shù)比較特別,所以單獨(dú)拿出來講。在詞法分析里面我們已經(jīng)把文件分行,每一行一個CodeToken的列表。但是由于一個函數(shù)聲明獨(dú)占一行,因此在這里我們只需要對每一行進(jìn)行分析。我們判斷這一行是否以cps、category、symbol、type、phrase、sentence或block開頭,如果是那Tinymoe就認(rèn)為這一定是一個聲明,否則就是普通的代碼。所以這里假設(shè)我們找到了一行代碼以上面的這些token作為開頭,于是我們就要進(jìn)入語法分析的環(huán)節(jié)。作為整個分析器的基礎(chǔ),我們需要一個ConsumeToken的函數(shù):
?
?
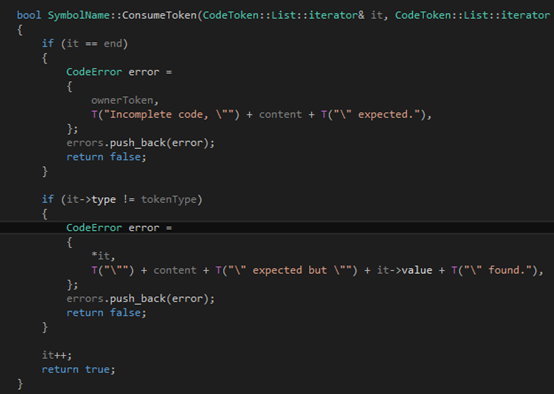
作為一個純粹的C++11的項目,我們應(yīng)該使用STL的迭代器。其實在寫語法分析器的時候,基于迭代器的代碼也比基于"token在數(shù)組里的下表"的代碼要簡單得多。這個函數(shù)所做的內(nèi)容是這樣的,它查看it指向的那個token,如果token的類型跟tokenType描述的一樣,他就it++然后返回true;否則就是用content和ownerToken來產(chǎn)生一個錯誤信息加入errors列表里,然后返回false。當(dāng)然,如果傳進(jìn)去的參數(shù)it本身就等于end,那自然要產(chǎn)生一個錯誤。自然,函數(shù)體也十分簡單:
?
那對于標(biāo)識符和數(shù)字怎么辦呢?明眼人肯定一眼就看出來,這是給檢查符號用的,譬如左括號、右括號、冒號和關(guān)鍵字等。在聲明里面我們是不需要太復(fù)雜的東西的,因此我們還需要兩外一個函數(shù)來輸入標(biāo)識符。Tinymoe事實上有兩個針對標(biāo)識符的語法分析函數(shù),第一個是讀入標(biāo)識符,第二個不僅要讀入標(biāo)識符還要判斷是否到了行末否則報錯:

?
在這里我需要強(qiáng)調(diào)一個重點(diǎn),在寫語法分析器的時候,函數(shù)的各式一定要整齊劃一。Tinymoe的語法分析函數(shù)有兩個格式,分別是針對parse一行的一個部分,和parse一個文件的一些行的。ParseToEnd和ParseToFarest就屬于parse一行的一個部分的函數(shù)。這種函數(shù)的格式如下:
返回值一定是語法樹的一個節(jié)點(diǎn)。在這里我們以share_ptr<SymbolName>作為標(biāo)識符的節(jié)點(diǎn)。一個標(biāo)識符可以含有多個標(biāo)識符token,譬如說the Chinese people、the real Tinymoe programmer什么的。因此我們可以簡單地推測SymbolName里面有一個vector<CodeToken>。這個定義可以在TinymoeLexicalAnalyzer.h的最后一部分找到。
前兩個參數(shù)分別是iterator&和指向末尾的iterator。末尾通常指"從這里開始我們不希望這個parser函數(shù)來讀",當(dāng)然這通常就意味著行末。我們把"末尾"這個概念抽取出來,在某些情況下可以得到極大的好處。
最后一個token一定是vector<CodeError>&,用來存放過程中遇到的錯誤。
?
除了函數(shù)格式以外,我們還需要所有的函數(shù)都遵循某些前置條件和后置條件。在語法分析里,如果你試圖分析一個結(jié)構(gòu)但是不幸出現(xiàn)了錯誤,這個時候,你有可能可以返回一個語法樹的節(jié)點(diǎn),你也有可能什么都返回不了。于是這里就有兩種情況:
你可以返回,那就證明雖然輸入的代碼有錯誤,但是你成功的進(jìn)行了錯誤恢復(fù)——實際上就是說,你覺得你自己可以猜測這份代碼的作者實際是要表達(dá)什么意思——于是你要移動第一個iterator,讓他指向你第一個還沒讀到的token,以便后續(xù)的語法分析過程繼續(xù)進(jìn)行下去。
你不能返回,那就證明你恢復(fù)不了,因此第一個iterator不能動。因為這個函數(shù)有可能只是為了測試一下當(dāng)前的輸入是否滿足一個什么結(jié)構(gòu)。既然他不是,而且你恢復(fù)不出來——也就是你猜測作者本來也不打算在這里寫某個結(jié)構(gòu)——因此iterator不能動,表示你什么都沒有讀。
?
當(dāng)你根據(jù)這樣的格式寫了很多語法分析函數(shù)之后,你會發(fā)現(xiàn)你可以很容易用簡單結(jié)構(gòu)的語法分析函數(shù),拼湊出一個復(fù)雜的語法分析函數(shù)。但是由于Tinymoe的聲明并沒有一個編程語言那么復(fù)雜,所以這種嵌套結(jié)構(gòu)出現(xiàn)的次數(shù)并不多,于是我們這里先跳過關(guān)于嵌套的討論,等到后面具體分析"函數(shù)指針類型的參數(shù)"的時候自然會涉及到。
?
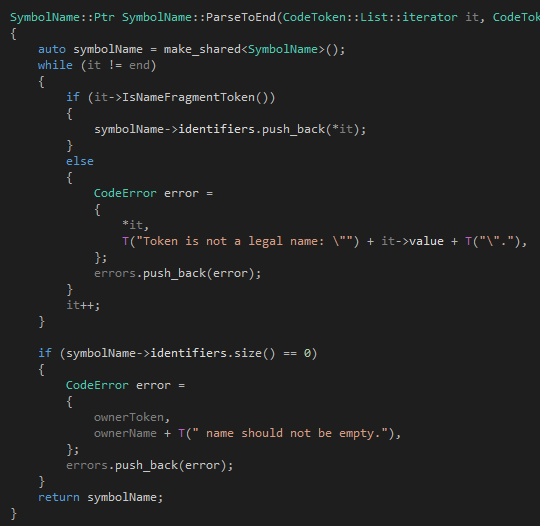
說了這么多,我覺得也應(yīng)該上ParseToEnd和ParseToFarest的代碼了。首先是ParseToEnd:
?
我們很快就可以發(fā)現(xiàn),其實語法分析器里面絕大多數(shù)篇幅的代碼都是關(guān)于錯誤處理的,真正處理正確代碼的部分其實很少。ParseToEnd做的事情不多,他就是從it開始一直讀到end的位置,把所有不是標(biāo)識符的token都扔掉,然后把所有遇到的標(biāo)識符token都連起來作為一個完整的標(biāo)識符。也就是說,ParseToEnd遇到類似"the real 100 Tinymoe programmer"的時候,他會返回"the real Tinymoe programmer",然后在"100"的地方報一個錯誤。
?
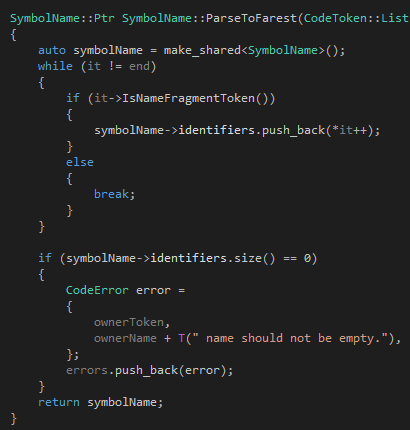
ParseToFarest的邏輯差不多:
?
只是當(dāng)這個函數(shù)遇到"the real 100 Tinymoe programmer"的時候,會返回"the real",然后把光標(biāo)移動到"100",但是沒有報錯。
?
看了這幾個基本的函數(shù)之后,我們可以進(jìn)入正題了。做語法分析器,當(dāng)然還是從文法開始。跟上一篇文章一樣,我們來嘗試直接構(gòu)造一下文法。但是語法分析器跟詞法分析器的文法的區(qū)別是,詞法分析其的文法可以 "定義函數(shù)"和"調(diào)用函數(shù)"。
?
首先,我們來看symbol的文法:
SymbolName ::= <identifier> { <identifier> }
Symbol ::= "symbol" SymbolName
?
其次,就是type的聲明。type是多行的,不過我們這里只關(guān)心開頭的一樣:
Type ::= "type" SymbolName [ ":" SymbolName ]
?
在這里,中括號代表可有可無,大括號代表重復(fù)0次或以上。現(xiàn)在讓我們來看函數(shù)的聲明。函數(shù)的生命略為復(fù)雜:
?
Function ::= ("phrase" | "sentence" | "block") { SymbolName | "(" Argument ")" } [ ":" SymbolName ]
Argument ::= ["list" | "expression" | "argument" | "assignable"] SymbolName
Argument ::= SymbolName
Argument ::= Function
?
Declaration ::= Symbol | Type | Function
?
在這里我們看到Function遞歸了自己,這是因為函數(shù)的參數(shù)可以是另一個函數(shù)。為了讓這個參數(shù)調(diào)用起來更加漂亮一點(diǎn),你可以把參數(shù)寫成函數(shù)的形式,譬如說:
pharse (the number) is odd : odd numbers
????return the number % 2 == 1
end
?
print all (phrase (the number) is wanted) in (numbers)
????repeat with the number in all numbers
????????if the number is wanted
????????????print the number
????????end
????end
end
?
print main
????print all odd numbers in array of (1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
end
?
我們給"(the number) is odd"這個判斷一個數(shù)字是不是奇數(shù)的函數(shù),起了一個別名叫"odd numbers",這個別名不能被調(diào)用,但是他等價于一個只讀的變量保存著奇數(shù)函數(shù)的函數(shù)指針。于是我們就可以把它傳遞給"print all (…) in (…)"這個函數(shù)的第一個參數(shù)了。第一個參數(shù)聲明成函數(shù),所以我們可以在print函數(shù)內(nèi)直接調(diào)用這個參數(shù)指向的odd numbers函數(shù)。
?
事實上Tinymoe的SymbolName是可以包含關(guān)鍵字的,但是我為了不讓它寫的太長,于是我就簡單的寫成了上面的那條式子。那Argument是否可以包含關(guān)鍵字呢?答案當(dāng)然是可以的,只是當(dāng)它以list、expression、argument、assignable、phrase、sentence、block開始的時候,我們強(qiáng)行認(rèn)為他有額外的意義。
?
現(xiàn)在一個Tinymoe的聲明的第一行都由Declaration來定義。當(dāng)我們識別出一個正確的Declaration之后,我們就可以根據(jù)分析的結(jié)果來對后面的行進(jìn)行分析。譬如說symbol后面沒有東西,于是就這么完了。type后面都是成員函數(shù),所以我們一直找到"end"為止。函數(shù)的函數(shù)體就更復(fù)雜了,所以我們會直接跳到下一個看起來像Declaration的東西——也就是以symbol、type、phrase、sentence、block、cps、category開始的行。這些步驟都很簡單,所以問題的重點(diǎn)就是,如何根據(jù)Declaration的文法來處理輸入的字符串。
?
為了讓文法可以真正的運(yùn)行,我們需要把它做成狀態(tài)機(jī)。根據(jù)之前的描述,這個狀態(tài)及仍然需要有"定義函數(shù)"和"執(zhí)行函數(shù)"的能力。我們可以先假裝他們是正則表達(dá)式,然后把整個狀態(tài)機(jī)畫出來。這個時候,"函數(shù)"本身我們把它看成是一個跟標(biāo)識符無關(guān)的輸入,然后就可以得到下面的狀態(tài)機(jī):
?
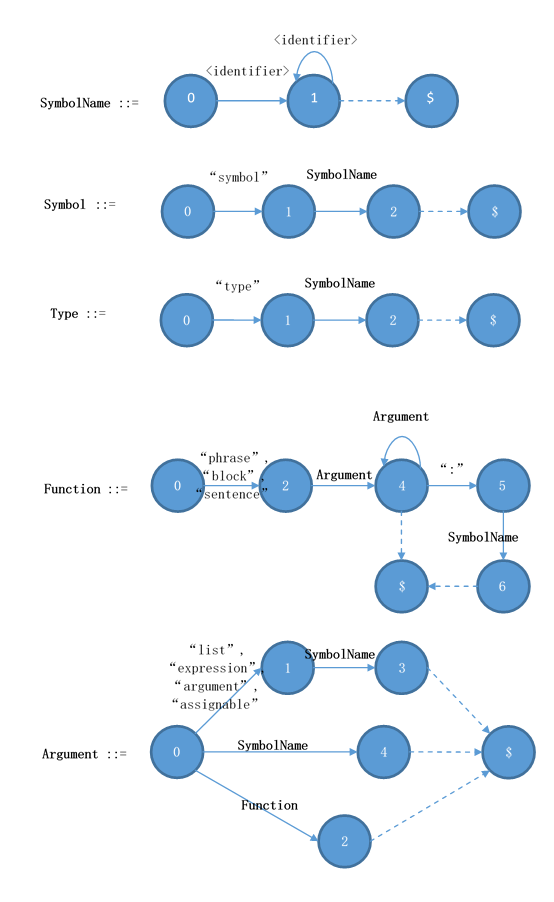
?
這樣我們的狀態(tài)機(jī)就暫時完成了。但是現(xiàn)在還不能直接把它轉(zhuǎn)換成代碼,因為當(dāng)我們遇到一個輸入,而我們可以選擇調(diào)用函數(shù),而且可以用的函數(shù)還不止一個的時候,那應(yīng)該怎么辦呢?答案就是要檢查我們的文法是不是有歧義。
?
文法的歧義是一個很有意思的問題。在我們真的實踐一個編譯器的時候,我們會遇到三種歧義:
文法本身就是有歧義的,譬如說C++著名的A* B;的問題。當(dāng)A是一個變量的時候,這是一個乘法表達(dá)式。當(dāng)A是一個類型的時候,這是一個變量聲明語句。如果我們在語法分析的時候不知道A到底指向的是什么東西,那我們根本無從得知這一句話到底要取什么意思,于是要么返回錯誤,要么兩個結(jié)果一起返回。這就是問法本身固有的歧義。
文法本身沒有歧義,但是在分析的過程中卻無法在走每一步的時候都能夠算出唯一的"下一個狀態(tài)"。譬如說C#著名的A<B>C;問題。當(dāng)A是一個變量的時候,這個語句是不成立的,因為C#的一個語句的根節(jié)點(diǎn)不能是一個操作符(這里是">")。當(dāng)A是一個類型的時候,這是一個變量聲明語句。從結(jié)果來看,這并沒有歧義,但是當(dāng)我們讀完A<B>的時候仍然不知道這個語句的結(jié)構(gòu)到底是取哪一種。實際上B作為類型參數(shù),他也可以有B<C>這樣的結(jié)構(gòu),因此這個B可以是任意長的。也就是說我們只有在">"結(jié)束之后再多讀幾個字符才能得到正確的判斷。譬如說C是"(1)",那我們知道A應(yīng)該是一個模板函數(shù)。如果C是一個名字,A多半應(yīng)該是一個類型。因此我們在做語法分析的時候,只能兩種情況一起考慮,并行處理。最后如果哪一個情況分析不下去了,就簡單的扔掉,剩下的就是我們所需要的。
文法本身沒有歧義,而且分析的過程中只要你每一步都往后多看最多N個token,酒可以算出唯一的"下一個狀態(tài)"到底是什么。這個想必大家都很熟悉,因為這個N就是LookAhead。所謂的LL(1)、SLR(1)、LR(1)、LALR(1)什么的,這個1其實就是N=1的情況。N當(dāng)然不一定是1,他也可以是一個很大的數(shù)字,譬如說8。一個文法的LookAhead是多少,這是文法本身固有的屬性。一個LR(2)的狀態(tài)機(jī)你非要在語法分析的時候只LookAhead一個token,那也會遇到第二種歧義的情況。如果C語言沒有typedef的話,那他就是一個帶有LookAhead的沒有歧義的語言了。
?
看一眼我們剛才寫出來的文法,明顯就是LookAhead=0的情況,而且連左遞歸都沒有,寫起來肯定很容易。那接下來我們要做的就是給"函數(shù)"算first set。一個函數(shù)的first set,顧名思義就是,他的第一個token都可以是什么。SymbolName、Symbol、Type、Function都不用看了,因為他們的文法第一個輸入都是token,那就是他們的first set。最后就剩下Argument。Argument的第一個token除了list、expression、argument和assignable以外,還有Function。因此Argument的first set就是這些token加上Function的first set。如果文法有左遞歸的話,也可以用類似的方法做,只要我們在函數(shù)A->B->C->…->A的時候,知道A正在計算于是返回空集就可以了。當(dāng)然,只有左遞歸才會遇到這種情況。
?
然后我們檢查一下每一個狀態(tài),可以發(fā)現(xiàn),任何一個狀態(tài)出去的所有邊,他接受的token或者函數(shù)的first set都是沒有交集的。譬如Argument的0狀態(tài),第一條邊接受的token、第二條邊接受的SymbolName的first set,和第三條邊接受的Function的first set,是沒有交集的,所以我們就可以斷定,這個文法一定沒有歧義。按照上次狀態(tài)機(jī)到代碼的寫法,我們可以機(jī)械的寫出代碼了。寫代碼的時候,我們把每一個文法的函數(shù),都寫成一個C++的函數(shù)。每到一個狀態(tài)的時候,我們看一下當(dāng)前的token是什么,然后再決定走哪條邊。如果選中的邊是token邊,那我們就跳過一個token。如果選中的邊是函數(shù)邊,那我們不跳過token,轉(zhuǎn)而調(diào)用那個函數(shù),讓函數(shù)自己去跳token。《如何手寫語法分析器》用的也是一樣的方法,如果對這個過程不清楚的,可以再看一遍這個文章。
?
于是我們到了定義語法樹的時候了。幸運(yùn)的是,我們可以直接從文法上看到語法樹的形狀,然后稍微做一點(diǎn)微調(diào)就可以了。我們把每一個函數(shù)都看成一個類,然后使用下面的規(guī)則:
對于A、A B、A B C等的情況,我們轉(zhuǎn)換成class里面有若干個成員變量。
對于A | B的情況,我們把它做成繼承,A的語法樹和B的語法樹繼承自一個基類,然后這個基類的指針就放在class里面做成員變量。
對于{ A },或者A { A }的情況,那個成員變量就是一個vector。
對于[ A ]的情況,我們就當(dāng)A看,區(qū)別只是,這個成員變量可以填nullptr。
?
對于每一個函數(shù),要不要用shared_ptr來裝則見仁見智。于是我們可以直接通過上面的文法得到我們所需要的語法樹:
?
首先是SymbolName:
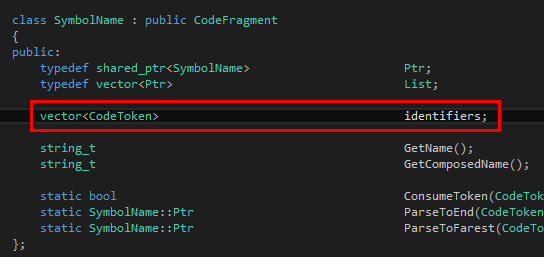
?
其次是Symbol:
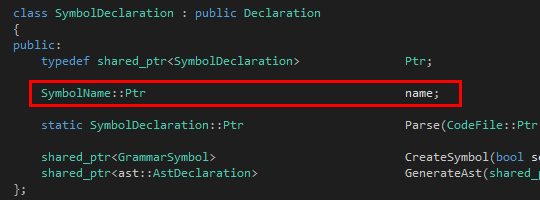
?
然后是Type:
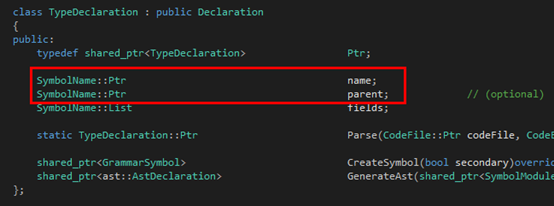
?
接下來是Argument:
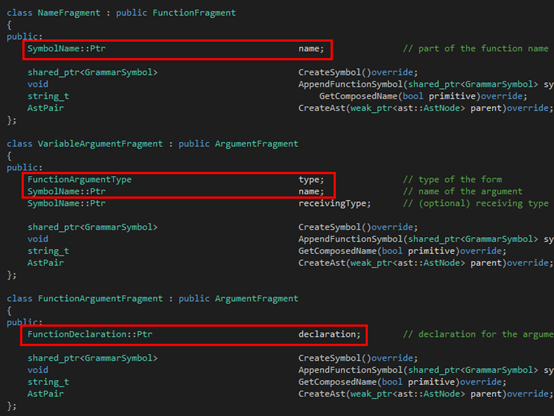
?
最后是Function:
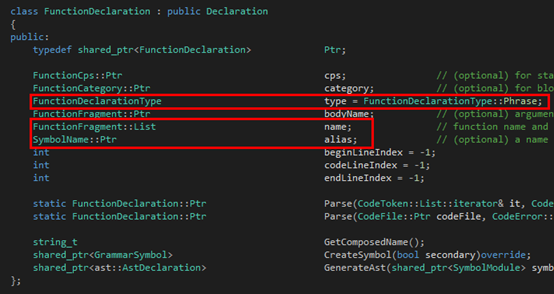
?
大家可以看到,在Argument那里,同時出去的三條邊就組成了三個子類,都繼承自FunctionFragment。圖中紅色的部分就是Tinymoe源代碼里在上述的文法里出現(xiàn)的那部分。至于為什么還有多出來的部分,其實是因為這里的文法是為了敘述方便簡化過的。至于Tinymoe關(guān)于函數(shù)聲明的所有語法可以分別看下面的四個github的wiki page:
https://github.com/vczh/tinymoe/wiki/Phrases,-Sentences-and-Blocks
https://github.com/vczh/tinymoe/wiki/Manipulating-Functions
https://github.com/vczh/tinymoe/wiki/Category
https://github.com/vczh/tinymoe/wiki/State-and-Continuation
?
在本章的末尾,我將向大家展示Tinymoe關(guān)于函數(shù)聲明的那一個Parse函數(shù)。文章已經(jīng)把所有關(guān)鍵的知識點(diǎn)都講了,具體怎么做大家可以上https://github.com/vczh/tinymoe 閱讀源代碼來學(xué)習(xí)。
?
首先是我們的函數(shù)頭:
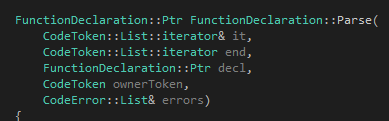
?
回想一下我們之前講到的關(guān)于語法分析函數(shù)的格式:
返回值一定是語法樹的一個節(jié)點(diǎn)。在這里我們以share_ptr<SymbolName>作為標(biāo)識符的節(jié)點(diǎn)。一個標(biāo)識符可以含有多個標(biāo)識符token,譬如說the Chinese people、the real Tinymoe programmer什么的。因此我們可以簡單地推測SymbolName里面有一個vector<CodeToken>。這個定義可以在TinymoeLexicalAnalyzer.h的最后一部分找到。
前兩個參數(shù)分別是iterator&和指向末尾的iterator。末尾通常指"從這里開始我們不希望這個parser函數(shù)來讀",當(dāng)然這通常就意味著行末。我們把"末尾"這個概念抽取出來,在某些情況下可以得到極大的好處。
最后一個token一定是vector<CodeError>&,用來存放過程中遇到的錯誤。
?
我們可以清楚地看到這個函數(shù)滿足上文提出來的三個要求。剩下來的參數(shù)有兩個,第一個是decl,如果不為空那代表調(diào)用函數(shù)的人已經(jīng)幫你吧語法樹給new出來了,你應(yīng)該直接使用它。領(lǐng)一個參數(shù)ownerToken則是為了產(chǎn)生語法錯誤使用的。然后我們看代碼:
?
第一步,我們判斷輸入是否為空,然后根據(jù)需要報錯:
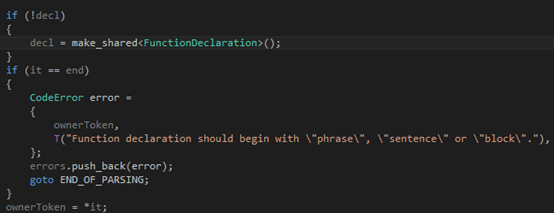
?
第二步,根據(jù)第一個token來確定函數(shù)的形式是phrase、sentence還是block,并記錄在成員變量type里:
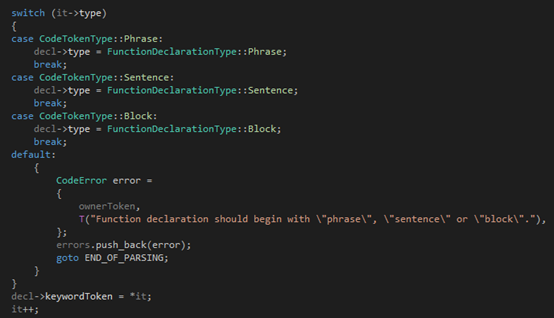
?
第三步是一個循環(huán),我們根據(jù)當(dāng)前的token(還記不記得之前說過,要先看一下token是什么,然后再決定走哪條邊?)來決定我們接下來要分析的,是ArgumentFragment的兩個子類(分別是VariableArgumentFragment和FunctionArgumentFragment),還是普通的函數(shù)名的一部分,還是說函數(shù)已經(jīng)結(jié)束了,遇到了一個冒號,因此開始分析別名:
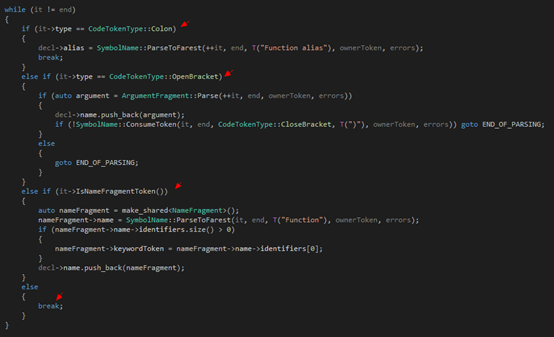
?
最后就不貼了,是檢查格式是否滿足語義的一些代碼,譬如說block的函數(shù)名必須由參數(shù)開始啦,或者phrase的參數(shù)不能是argument和assignable等。
?
這篇文章就到此結(jié)束了,希望大家在看了這片文章之后,配合wiki關(guān)于語法的全面描述,已經(jīng)知道如何對Tinymoe的聲明部分進(jìn)行語法分析。緊接著就是下一篇文章——Tinymoe與帶歧義語法分析了,會讓大家明白,想對諸如"print sum from 1 to 100"這樣的代碼做語法分析,也不需要多復(fù)雜的手段就可以做出來。
posted on 2014-03-23 00:51
陳梓瀚(vczh) 閱讀(8437)
評論(2) 編輯 收藏 引用 所屬分類:
跟vczh看實例學(xué)編譯原理