注:本文的代碼圖片資料選自NVIDIA CUDAProgramming Guide,原作者保留所有著作權。
NVIDIA近日終于發布了CUDA,有可能作為下一代SDK10的一部分奉送給樂于發掘GPU計算能力的專業人員。感興趣的朋友可以去這里一探究竟,下載嘗鮮,提供了大量的范例。
我們都知道,GPU的并行運算性能是極為強悍的,如此豐富的計算資源如果浪費著不用,就用來跑跑游戲是遠遠不行的。而傳統的圖形API又單單的只提供了圖形操作的功能,沒有提供類似于CPU那樣通用計算的接口,所以說以往的方法都是很麻煩而且需要相當的經驗的 —— 比如用HDR圖片作Cube Map的時候,如果使用的是Paul提供的那種類似于經緯圖的紋理,就需要大量的反三角函數的計算,而用Vertex Shader作反三角又太浪費時間,于是人們用1D紋理作線性插值查找表進行快速計算(訪問數據紋理)。這個例子也可以看作是最基本的GPU計算。
CUDA的誕生
使用傳統API進行計算是個不可挽回的錯誤,CUDA的出現將改變這一狀況。CUDA主要在驅動程序方面和函數庫方面進行了擴充。在CUDA庫中提供了標準的FFT與BLAS庫,一個為NVDIA GPU設計的C編譯器。CUDA的特色如下,引自NVIDIA的官方說明:
1、為并行計算設計的統一硬件軟件架構。有可能在G80系列上得到發揮。
2、在GPU內部實現數據緩存和多線程管理。這個強,思路有些類似于XB360 PS3上的CPU編程。
3、在GPU上可以使用標準C語言進行編寫。
4、標準離散FFT庫和BLAS基本線性代數計算庫。
5、一套CUDA計算驅動。
6、提供從CPU到GPU的加速數據上傳性能。瓶頸就在于此。
7、CUDA驅動可以和OpenGL DirectX驅動交互操作。這強,估計也可以直接操作渲染管線。
8、與SLI配合實現多硬件核心并行計算。
9、同時支持Linux和Windows。這個就是噱頭了。
看過了宣傳,您可以看一下CUDA提供的Programming Guide和其他的文檔。NVIDIA我覺得有些類似圖形界的Microsoft,提供精良的裝備諸如SDK和開發文檔等等,比ATi好多了。
CUDA本質
CUDA的本質是,NVIDIA為自家的GPU編寫了一套編譯器NVCC極其相關的庫文件。CUDA的應用程序擴展名可以選擇是.cu,而不是.cpp等。NVCC是一個預處理器和編譯器的混合體。當遇到CUDA代碼的時候,自動編譯為GPU執行的代碼,也就是生成調用CUDA Driver的代碼。如果碰到Host C++代碼,則調用平臺自己的C++編譯器進行編譯,比如Visual Studio C++自己的Microsoft C++ Compiler。然后調用Linker把編譯好的模塊組合在一起,和CUDA庫與標準C\C++庫鏈接成為最終的CUDA Application。由此可見,NVCC模仿了類似于GCC一樣的通用編譯器的工作原理(GCC編譯C\C++代碼本質上就是調用cc和g++)。NVCC有著復雜的選項,詳情參閱CUDA SDK中的NVCC相關文檔。
CUDA編程概念
Device
CUDA API提供接口枚舉出系統中可以作為計算設備使用的硬件為計算進行初始化等操作。類似于DX編程中的初始化COM接口。
Texture
線性內存中的數據和數組中的數據都可以作為紋理使用。不過數組在緩存層面上更適合優化。紋理的概念類似于傳統的圖像紋理,可以以8 16 32位的整數儲存,也可以用fp16格式進行儲存。而且當把數組轉換為紋理的時候,還有一些有點,比如整數與fp16數字可以選擇統一的轉換到32bit浮點數,還可以使用數組邊界這個特性,還可以進行過濾操作。
OpenGL/DirectX Interoperability
OpenGL的幀緩沖與DirectX9的頂點緩沖可以被映射到CUDA可操作的地址空間中,讓CUDA讀寫幀緩沖里面的數據。不過CUDA Context一次只能操作一個Direct3D設備。當前CUDA還不支持對DX10進行類似的操作,除了DX9頂點緩沖也不允許進行映射,而且一次只能映射一次。(這個地方NVIDIA沒有說清楚,我估計是指只有一個Mapping Slot)
Thread Block
A thread block is a batch of threads that can cooperate together by efficiently sharing data through some fast shared memory and synchronizing their execution to coordinate memory accesses.
ThreadBlock由一系列線程組成,這些線程可以快速共享內存,同步內存訪問。每個線程都有個ID,這個ID好像平面坐標一般。線程組成Grid。示意圖如下:
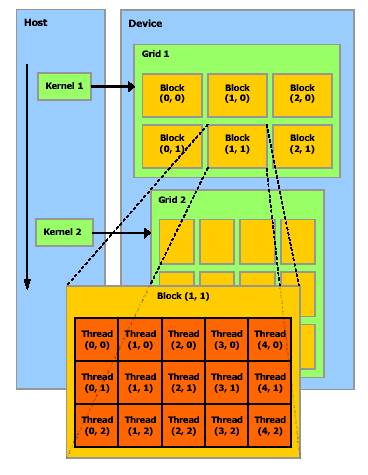
Memory Model
A thread that executes on the device has only access to the device’s DRAM and on-chip memory through the following memory spaces:
? Read-write per-thread registers,
? Read-write per-thread local memory,
? Read-write per-block shared memory,
? Read-write per-grid global memory,
? Read-only per-grid constant memory,
? Read-only per-grid texture memory.
The global, constant, and texture memory spaces can be read from or written to by the host and are persistent across kernel calls by the same application.
在CUDA中我們要接觸到的內存主要有:寄存器,Local內存,Shared內存,Global內存,Constant內存,Texture內存。 有些類似于C內存的分配類型了。而且內存可以分配為數組或者是普通線性內存,CUDA提供API可以正確的進行內存拷貝等操作。
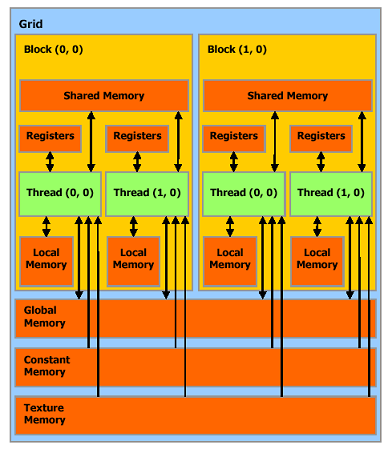
后面我們將談到如何優化GPU內存。從上面的資料我們可以看出,這里的Grid概念類似于Process,也就是為線程執行分配資源的單元,而只有線程是真正計算的部分。Local Memory類似線程的棧。Texture Memory類似于堆內存區。
具體操作 我以CUDA附帶的simpleCUBLAS作為例子。
 #include?<stdio.h>
#include?<stdio.h>
#include?<stdlib.h>
#include?<string.h>

 /**//*?Includes,?cuda?*/
/**//*?Includes,?cuda?*/
#include?"cublas.h"
/**//*?Matrix?size?*/
#define?N??(275)
/**//*?Host?implementation?of?a?simple?version?of?sgemm?*///使用CPU進行Matrix乘法計算的算式
static?void?simple_sgemm(int?n,?float?alpha,?const?float?*A,?const?float?*B,
?????????????????????????float?beta,?float?*C)
 {
{
 ????int?i;
????int?i;
????int?j;
????int?k;

 ????for?(i?=?0;?i?<?n;?++i)?{
????for?(i?=?0;?i?<?n;?++i)?{
????????for?(j?=?0;?j?<?n;?++j)?{
????????????float?prod?=?0;
????????????for?(k?=?0;?k?<?n;?++k)?{
????????????????prod?+=?A[k?*?n?+?i]?*?B[j?*?n?+?k];
 ????????????}
????????????}
????????????C[j?*?n?+?i]?=?alpha?*?prod?+?beta?*?C[j?*?n?+?i];
????????}
????}
 }
}
/**//*?Main?*/
int?main(int?argc,?char**?argv)
{????
????cublasStatus?status;
????float*?h_A;
????float*?h_B;
????float*?h_C;
????float*?h_C_ref;
????float*?d_A?=?0;
????float*?d_B?=?0;
????float*?d_C?=?0;
????float?alpha?=?1.0f;
????float?beta?=?0.0f;
????int?n2?=?N?*?N;
????int?i;
????float?error_norm;
????float?ref_norm;
????float?diff;
????/**//*?Initialize?CUBLAS?*///初始化CUBLAS庫
????status?=?cublasInit();
????if?(status?!=?CUBLAS_STATUS_SUCCESS)?{
????????fprintf?(stderr,?"!!!!?CUBLAS?initialization?error\n");
????????return?EXIT_FAILURE;
????}
????/**//*?Allocate?host?memory?for?the?matrices?*///分配內存,這3個是257*257的大矩陣
????h_A?=?(float*)malloc(n2?*?sizeof(h_A[0]));
????if?(h_A?==?0)?{
????????fprintf?(stderr,?"!!!!?host?memory?allocation?error?(A)\n");
????????return?EXIT_FAILURE;
????}
????h_B?=?(float*)malloc(n2?*?sizeof(h_B[0]));
????if?(h_B?==?0)?{
????????fprintf?(stderr,?"!!!!?host?memory?allocation?error?(B)\n");
????????return?EXIT_FAILURE;
????}
????h_C?=?(float*)malloc(n2?*?sizeof(h_C[0]));
????if?(h_C?==?0)?{
????????fprintf?(stderr,?"!!!!?host?memory?allocation?error?(C)\n");
????????return?EXIT_FAILURE;
????}
????/**//*?Fill?the?matrices?with?test?data?*/
????for?(i?=?0;?i?<?n2;?i++)?{
????????h_A[i]?=?rand()?/?(float)RAND_MAX;
????????h_B[i]?=?rand()?/?(float)RAND_MAX;
????????h_C[i]?=?rand()?/?(float)RAND_MAX;
????}
????/**//*?Allocate?device?memory?for?the?matrices?*/ //在GPU設備上分配內存
????status?=?cublasAlloc(n2,?sizeof(d_A[0]),?(void**)&d_A);
????if?(status?!=?CUBLAS_STATUS_SUCCESS)?{
????????fprintf?(stderr,?"!!!!?device?memory?allocation?error?(A)\n");
????????return?EXIT_FAILURE;
????}
????status?=?cublasAlloc(n2,?sizeof(d_B[0]),?(void**)&d_B);
????if?(status?!=?CUBLAS_STATUS_SUCCESS)?{
????????fprintf?(stderr,?"!!!!?device?memory?allocation?error?(B)\n");
????????return?EXIT_FAILURE;
????}
????status?=?cublasAlloc(n2,?sizeof(d_C[0]),?(void**)&d_C);
????if?(status?!=?CUBLAS_STATUS_SUCCESS)?{
????????fprintf?(stderr,?"!!!!?device?memory?allocation?error?(C)\n");
????????return?EXIT_FAILURE;
????}
????/**//*?Initialize?the?device?matrices?with?the?host?matrices?*/ //把HOST內的矩陣上傳到GPU去
????status?=?cublasSetVector(n2,?sizeof(h_A[0]),?h_A,?1,?d_A,?1);
????if?(status?!=?CUBLAS_STATUS_SUCCESS)?{
????????fprintf?(stderr,?"!!!!?device?access?error?(write?A)\n");
????????return?EXIT_FAILURE;
????}
????status?=?cublasSetVector(n2,?sizeof(h_B[0]),?h_B,?1,?d_B,?1);
????if?(status?!=?CUBLAS_STATUS_SUCCESS)?{
????????fprintf?(stderr,?"!!!!?device?access?error?(write?B)\n");
????????return?EXIT_FAILURE;
????}
????status?=?cublasSetVector(n2,?sizeof(h_C[0]),?h_C,?1,?d_C,?1);
????if?(status?!=?CUBLAS_STATUS_SUCCESS)?{
????????fprintf?(stderr,?"!!!!?device?access?error?(write?C)\n");
????????return?EXIT_FAILURE;
????}
????
????/**//*?Performs?operation?using?plain?C?code?*/ //使用CPU進行矩陣乘法計算
????simple_sgemm(N,?alpha,?h_A,?h_B,?beta,?h_C);
????h_C_ref?=?h_C;
????/**//*?Clear?last?error?*/
????cublasGetError();
????/**//*?Performs?operation?using?cublas?*/ //Wow !使用GPU計算
????cublasSgemm('n',?'n',?N,?N,?N,?alpha,?d_A,?N,?d_B,?N,?beta,?d_C,?N);
????status?=?cublasGetError();
????if?(status?!=?CUBLAS_STATUS_SUCCESS)?{
????????fprintf?(stderr,?"!!!!?kernel?execution?error.\n");
????????return?EXIT_FAILURE;
????}
????
????/**//*?Allocate?host?memory?for?reading?back?the?result?from?device?memory?*/ //分配HOST內存準備存放結果
????h_C?=?(float*)malloc(n2?*?sizeof(h_C[0]));
????if?(h_C?==?0)?{
????????fprintf?(stderr,?"!!!!?host?memory?allocation?error?(C)\n");
????????return?EXIT_FAILURE;
????}
????/**//*?Read?the?result?back?*/ //回讀
????status?=?cublasGetVector(n2,?sizeof(h_C[0]),?d_C,?1,?h_C,?1);
????if?(status?!=?CUBLAS_STATUS_SUCCESS)?{
????????fprintf?(stderr,?"!!!!?device?access?error?(read?C)\n");
????????return?EXIT_FAILURE;
????}
????/**//*?Check?result?against?reference?*/
????error_norm?=?0;
????ref_norm?=?0;
????for?(i?=?0;?i?<?n2;?++i)?{
????????diff?=?h_C_ref[i]?-?h_C[i];
????????error_norm?+=?diff?*?diff;
????????ref_norm?+=?h_C_ref[i]?*?h_C_ref[i];
????}
????error_norm?=?(float)sqrt((double)error_norm);
????ref_norm?=?(float)sqrt((double)ref_norm);
????if?(fabs(ref_norm)?<?1e-7)?{
????????fprintf?(stderr,?"!!!!?reference?norm?is?0\n");
????????return?EXIT_FAILURE;
????}
????printf(?"Test?%s\n",?(error_norm?/?ref_norm?<?1e-6f)???"PASSED"?:?"FAILED");
????/**//*?Memory?clean?up?*/
????free(h_A);
????free(h_B);
????free(h_C);
????free(h_C_ref);
????status?=?cublasFree(d_A);
????if?(status?!=?CUBLAS_STATUS_SUCCESS)?{
????????fprintf?(stderr,?"!!!!?memory?free?error?(A)\n");
????????return?EXIT_FAILURE;
????}
????status?=?cublasFree(d_B);
????if?(status?!=?CUBLAS_STATUS_SUCCESS)?{
????????fprintf?(stderr,?"!!!!?memory?free?error?(B)\n");
????????return?EXIT_FAILURE;
????}
????status?=?cublasFree(d_C);
????if?(status?!=?CUBLAS_STATUS_SUCCESS)?{
????????fprintf?(stderr,?"!!!!?memory?free?error?(C)\n");
????????return?EXIT_FAILURE;
????}
????/**//*?Shutdown?*///關閉CUBLAS卸載資源
????status?=?cublasShutdown();
????if?(status?!=?CUBLAS_STATUS_SUCCESS)?{
????????fprintf?(stderr,?"!!!!?shutdown?error?(A)\n");
????????return?EXIT_FAILURE;
????}
????if?(argc?<=?1?||?strcmp(argv[1],?"-noprompt"))?{
????????printf("\nPress?ENTER?to?exit\n");
????????getchar();
????}
????return?EXIT_SUCCESS;
}
除了那些個容錯的代碼,我們可以看出使用CUBLAS庫進行計算還是非常簡潔直觀的。詳細的資料請看CUDA SDK自帶的范例。
我的展望
ATi(AMD)坐不住的,應該會積極開發CPU與GPU融合的相關組建。
瓶頸在CPU - GPU帶寬上,NV很有可能推出優化過的nForce芯片組提供高帶寬。
用ICE配上CUDA組成分布式的GPU計算平臺怎么樣?!大伙不妨暢想暢想。
下一代BOINC計算平臺內的項目能夠提供基于GPU的計算客戶端。
posted on 2007-02-24 14:42
周波 閱讀(4566)
評論(6) 編輯 收藏 引用 所屬分類:
Cg藝術 、
無庸技術 、
奇思妙想