轉載自:http://www.race604.com/flatbuffers-intro/
1. 背景
最近在項目中需要使用一種高效數據序列化的工具。碰巧在幾篇文章中都提到了FlatBuffers 這個庫。特別是 Android 性能優化典范第四季1中兩個對比圖,讓我對它產生濃厚的興趣。如下: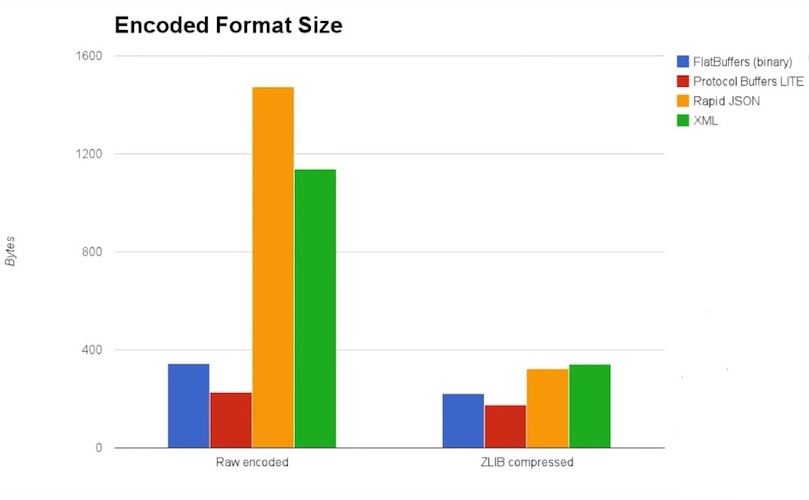
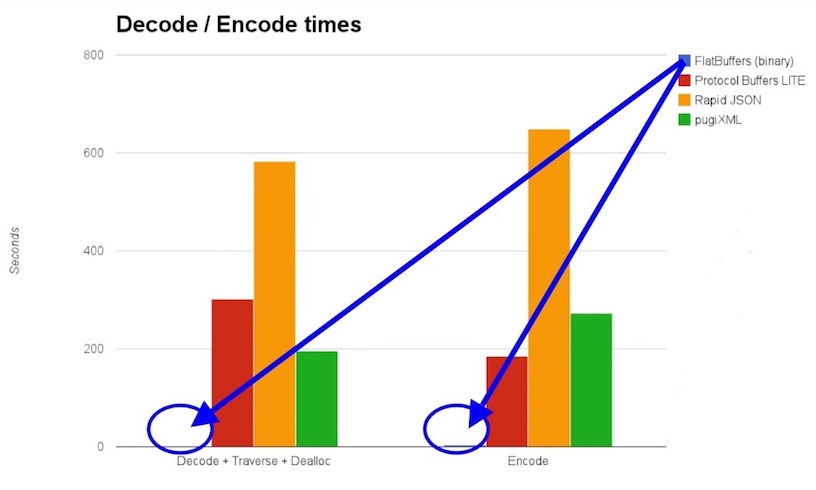 (注:圖片來自1)
(注:圖片來自1)
可見,FlatBuffers 幾乎從空間和時間復雜度上完勝其他技術,我決定詳細調研一下此技術。
FlatBuffers 是一個開源的跨平臺數據序列化庫,可以應用到幾乎任何語言(C++, C#, Go, Java, JavaScript, PHP, Python),最開始是 Google 為游戲或者其他對性能要求很高的應用開發的。項目地址在 GitHub 上。官方的文檔在 這里。
本文將介紹一下我使用 FlatBuffers 的一些感受,希望對想要了解或者使用 FlatBuffers 的同學有一點幫組。
2. FlatBuffer 的優點
FlatBuffer 相對于其他序列化技術,例如 XML,JSON,Protocol Buffers 等,有哪些優勢呢?官方文檔的說法如下:
- 直接讀取序列化數據,而不需要解析(Parsing)或者解包(Unpacking):FlatBuffer 把數據層級結構保存在一個扁平化的二進制緩存(一維數組)中,同時能夠保持直接獲取里面的結構化數據,而不需要解析,并且還能保證數據結構變化的前后向兼容。
- 高效的內存使用和速度:FlatBuffer 使用過程中,不需要額外的內存,幾乎接近原始數據在內存中的大小。
- 靈活:數據能夠前后向兼容,并且能夠靈活控制你的數據結構。
- 很少的代碼侵入性:使用少量的自動生成的代碼即可實現。
- 強數據類性,易于使用,跨平臺,幾乎語言無關。
官方提供了一個性能對比表如下:
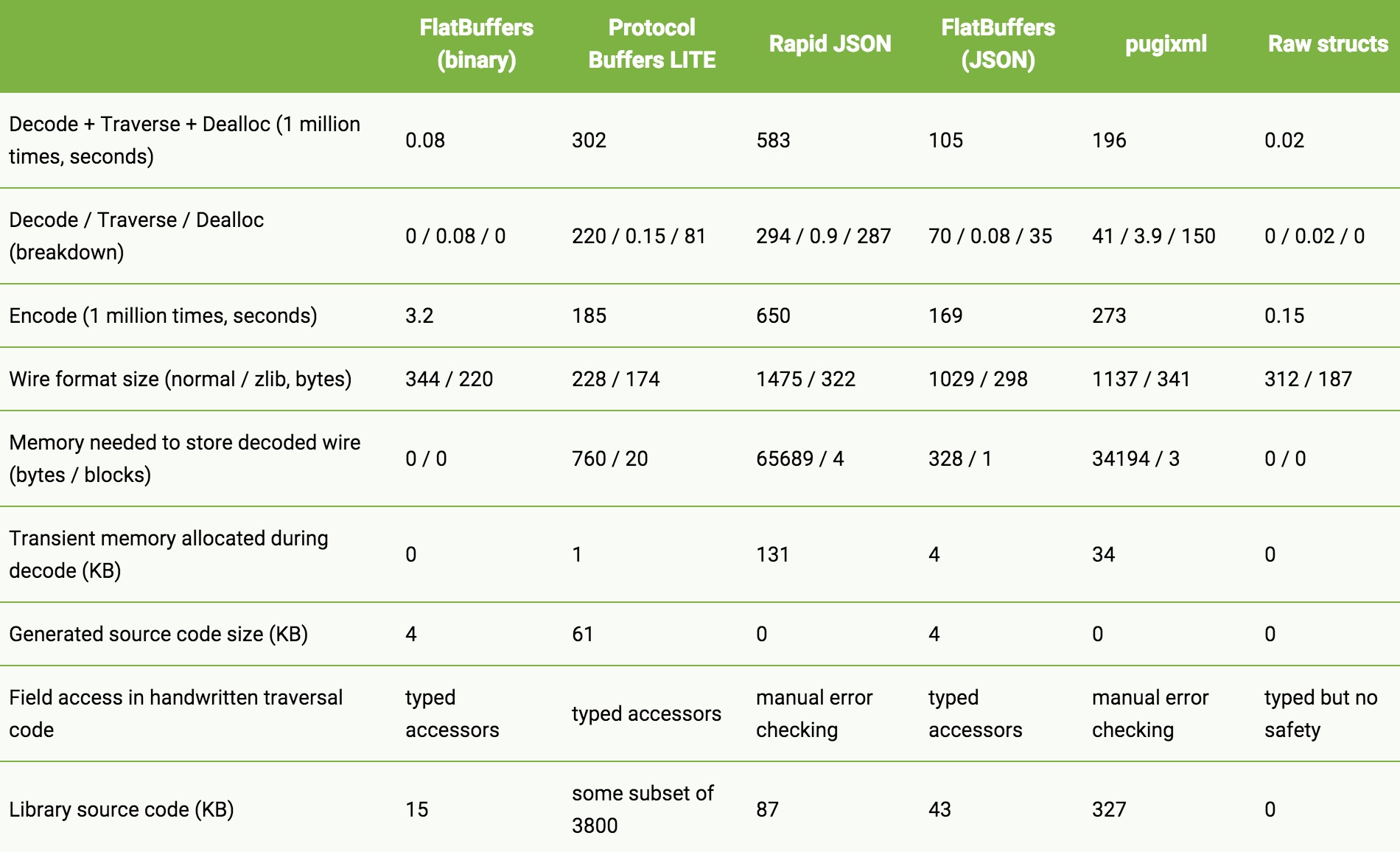 (注:來自 官方文檔)
(注:來自 官方文檔)
在做 Android 開發的時候,JSON 是最常用的數據序列化技術。我們知道,JSON 的可讀性很強,但是序列化和反序列化性能卻是最差的。解析的時候,JSON 解析器首先,需要在內存中初始化一個對應的數據結構,這個事件經常會消耗 100ms ~ 200ms2;解析過程中,要產生大量的臨時變量,造成 Java 虛擬機的 GC 和內存抖動,解析 20KB 的數據,大概會消耗 100KB 的臨時內存2。FlatBuffers 就解決了這些問題。
3. 使用方法
簡單來說,FlatBuffers 的使用方法是,首先按照使用特定的 IDL 定義數據結構 schema,然后使用編譯工具 flatc 編譯 schema 生成對應的代碼,把生成的代碼應用到工程中即可。下面詳細介紹每一步。
首先,我們需要得到 flatc,這個需要從源碼編輯得到。從 GitHub 上 Clone 代碼,
$ git clone https://github.com/google/flatbuffers
在 Mac 上,使用 Xcode 直接打開 build/Xcode/ 里面項目文件,編譯運行,即可在項目根目錄生成我們需要的 flatc 工具。也可以使用 cmake 編輯,例如在 Linux 上,運行如下命令即可:
$ cmake -G "Unix Makefiles"
$ make
首先要使用 FlatBuffers 的 IDL 定義好數據結構 Schema,編寫 Schema 的詳細文檔在 這里。其語法和 C 語言類似,比較容易上手。我們這里引用一個簡單的例子2,假設數據結構如下:
class Person {
String name;
int friendshipStatus;
Person spouse;
List<Person>friends;
}
編寫成 Schema 如下,文件名為 Person.fbs:
// Person schema
namespace com.race604.fbs;
enum FriendshipStatus: int {Friend = 1, NotFriend}
table Person {
name: string;
friendshipStatus: FriendshipStatus = Friend;
spouse: Person;
friends: [Person];
}
root_type Person;
然后,使用 flatc 可以把 Schema 編譯成多種編程語言,我們僅僅討論 Android 平臺,所以把 Schema 編譯成 Java,命令如下:
$ ./flatc --java Person.fbs
在當前目錄生成如下文件:
.
└── com
└── race604
└── fbs
├── FriendshipStatus.java
└── Person.java
Person 類有響應的函數直接獲取其內部的屬性值,使用非常簡單:
Person person =

;
// 獲取普通成員
String name = person.name();
int friendshipStatus = person.friendshipStatus();
// 獲取數組
int length = person.friendsLength()
for (
int i = 0; i < length; i++) {
Person friends = person.friends(i);
}
下面我們來構建一個 Person 對象,名字是 "John",其配偶(spouse)是 "Mary",還有兩個朋友,分別是 "Dave" 和 "Tom",實現如下:
private ByteBuffer createPerson() {
FlatBufferBuilder builder = new FlatBufferBuilder(0);
int spouseName = builder.createString("Mary");
int spouse = Person.createPerson(builder, spouseName, FriendshipStatus.Friend, 0, 0);
int friendDave = Person.createPerson(builder, builder.createString("Dave"),
FriendshipStatus.Friend, 0, 0);
int friendTom = Person.createPerson(builder, builder.createString("Tom"),
FriendshipStatus.Friend, 0, 0);
int name = builder.createString("John");
int[] friendsArr = new int[]{ friendDave, friendTom };
int friends = Person.createFriendsVector(builder, friendsArr);
Person.startPerson(builder);
Person.addName(builder, name);
Person.addSpouse(builder, spouse);
Person.addFriends(builder, friends);
Person.addFriendshipStatus(builder, FriendshipStatus.NotFriend);
int john = Person.endPerson(builder);
builder.finish(john);
return builder.dataBuffer();
}
基本方法就是通過 FlatBufferBuilder 工具,往里面填寫數據,詳細的寫法可以參考官方文檔3。可見,其實寫法略顯繁瑣,不太直觀。
4. 基本原理
如官方文檔的介紹,FlatBuffers 就像它的名字所表示的一樣,就是把結構化的對象,用一個扁平化(Flat)的緩沖區保存,簡單的來說就是把內存對象數據,保存在一個一維的數組中。借用 Facebook 文章2的一張圖如下:
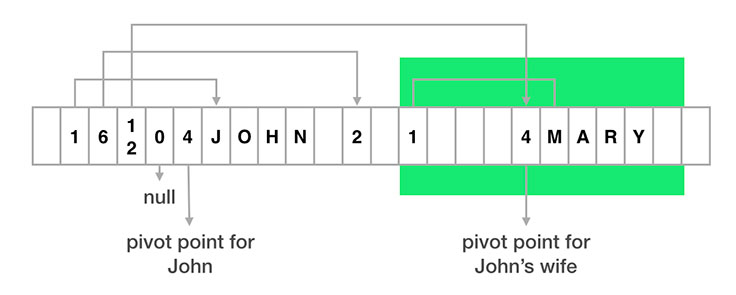 可見,FlatBuffers 保存在一個 byte 數組中,有一個“支點”指針(pivot point)以此為界,存儲的內容分為兩個部分:元數據和數據內容。其中元數據部分就是數據在前面,其長度等于對象中的字段數量,每個 byte 保存對應字段內容在數組中的索引(從支點位置開始計算)。
可見,FlatBuffers 保存在一個 byte 數組中,有一個“支點”指針(pivot point)以此為界,存儲的內容分為兩個部分:元數據和數據內容。其中元數據部分就是數據在前面,其長度等于對象中的字段數量,每個 byte 保存對應字段內容在數組中的索引(從支點位置開始計算)。
如圖,上面的 Person 對象第一個字段是 name,其值的索引位置是 1,所以從索引位置 1 開始的字符串,就是 name 字段的值 "John"。第二個字段是 friendshipStatus,其索引值是 6,找到值為 2, 表示 NotFriend。第三個字段是 spouse,也一個 Person 對象,索引值是 12,指向的是此對象的支點位置。第四個字段是一個數組,圖中表示的數組為空,所以索引值是 0。
通過上面的解析,可以看出,FlatBuffers 通過自己分配和管理對象的存儲,使對象在內存中就是線性結構化的,直接可以把內存內容保存或者發送出去,加載“解析”數據只需要把 byte 數組加載到內存中即可,不需要任何解析,也不產生任何中間變量。
它與具體的機器或者運行環境無關,例如在 Java 中,對象內的內存不依賴 Java 虛擬機的堆內存分配策略實現,所以也是跨平臺的。
5. 使用建議
通過前面的體驗,FlatBuffers 幾乎秒殺了 JSON,我也嘗試使用到現在的項目中,但是最后還是放棄了,下面說說 FlatBuffers 的幾點缺點:
- FlatBuffers 需要生成代碼,對代碼有侵入性;
- 數據序列化沒有可讀性,不方便 Debug;
- 構建 FlatBuffers 對象比較麻煩,不直觀,特別是如果對象比較復雜情況下需要寫大段的代碼;
- 數據的所有內容需要使用 Schema 嚴格定義,靈活性不如 JSON。
我最后在項目中放棄是因為上面的第 4 點,因為在我的項目中,數據結構變化很大,不方便使用 Schema 完全定義。話又說回來,FlatBuffers 這么多好處,還是很吸引我的,可能會在其他的項目中嘗試。
所以,在什么情況下選擇使用 FlatBuffers 呢?個人感覺需要滿足以下幾點:
- 項目中有大量數據傳輸和解析,使用 JSON 成為了性能瓶頸;
- 穩定的數據結構定義。
參考資料: