描述
攔截Linux動態庫API的常規方法,是基于動態符號鏈接覆蓋技術實現的,基本步驟是
1. 重命名要攔截的目標動態庫。
2. 創建新的同名動態庫,定義要攔截的同名API,在API內部調用原動態庫對應的API。這里的同名是指與重命名前動態庫前的名稱相同。
顯而易見,如果要攔截多個不同動態庫中的API,那么必須創建多個對應的同名動態庫,這樣一來不僅繁瑣低效,還必須被優先鏈接到客戶二進制程序中(根據動態庫鏈接原理,對重復ABI符號的處理是選擇優先鏈接的那個動態庫)。 另外在鉤子函數的實現中,若某調用鏈調用到了原API,則會引起死循環而崩潰。本方法通過直接修改ELF文件中的動態庫API入口表項,解決了常規方法的上述問題。
特點
1. 不依賴于動態庫鏈接順序。
2. 能攔截多個不同動態庫中的多個API。
3. 支持運行時動態鏈接的攔截。
4. 鉤子函數內的實現體,若調用到原API,則不會死循環。
實現
攔截映射表
為了支持特點2和3,建立了一個攔截映射表,這個映射表有2級。第1級為ELF文件到它的API鉤子映射表,鍵為ELF文件句柄,值為API鉤子映射表;第2級為API到它的鉤子函數映射表,鍵為API名稱,值為包含最老原函數地址和最新鉤子函數地址的結構體,如下圖
當最先打開ELF文件成功時,會在第1級映射表中插入記錄;反之當最后關閉同一ELF文件時,就會從中移除對應的記錄。當第一次掛鉤動態庫API時,就會在第2級映射表插入記錄;反之卸鉤同一API時,就會從中刪除對應的記錄。
計算ELF文件的映像基地址
計算映像基地址是為了得到ELF中動態符號表和重定位鏈接過程表的內容,因為這些表的位置都是相對于基地址的偏移量,該算法在打開ELF文件時執行,如下圖
EXE文件為可執行文件,DYN文件為動態庫。對于可執行文件,映射基地址為可執行裝載段的虛擬地址;對于動態庫,可通過任一API的地址減去它的偏移量得到,任一API的地址可通過調用libdl.so庫API dlsym得到,偏移量通過查詢動態鏈接符號表得到。
打開ELF文件
為了支持特點2即攔截不同動態庫的多個API,節省每次掛鉤API前要打開并讀文件的開銷,獨立提供了打開ELF文件的接口操作,流程如下圖
若輸入ELF文件名為空,則表示打開當前進程的可執行文件,此時要從偽文件系統/proc/self/exe讀取文件路徑名,以正確調用系統調用open。當同一ELF文件被多次打開時,只須遞增結構elf的引用計數。
掛鉤API
當打開ELF文件后,就可掛鉤API了,流程如下圖
當第一次掛鉤時,需要保存原函數以供后面卸鉤;第二次以后繼續掛鉤同一API時,更新鉤子函數,但原函數不變。
卸鉤API
當打開ELF文件后,就可卸鉤API了,流程如下圖
關閉ELF文件
因為提供了打開ELF文件的接口操作,所以得配有關閉ELF文件的接口操作。當不需要掛鉤API的時候,就可以關閉ELF文件了,流程如下圖
運行時動態攔截裝置
在初始化模塊中打開當前可執行文件,掛鉤libdl.so庫的API dlopen和dlsym;在轉換模塊中,按動態庫句柄和API名稱在攔截映射表中查找鉤子函數,若找到則返回鉤子函數,否則返回調用dlsym的結果;在銷毀模塊中,卸鉤dlopen和dlsym。
當動態庫被進程加載的時候,會調用初始化模塊;當被進程卸載或進程退出的時候,會調用銷毀模塊;當通過dlsym調用API時,則會在dlsym的鉤子函數中調用轉換模塊。通過環境變量LD_PRELOAD將動態庫libhookapi.so設為預加載庫,這樣就能攔截到所有進程對dlopen及dlsym的調用,進而攔截到已掛鉤動態庫API的調用。
posted @
2016-08-25 11:10 春秋十二月 閱讀(2296) |
評論 (0) |
編輯 收藏
本方法適用于linux 2.6.x內核。
1. 先獲取dentry所屬文件系統對應的掛載點,基本原理是遍歷文件系統vfsmount樹,找到與dentry有相同超級塊的vfsmount,實現如下
next_mnt函數實現了
先根遍歷法,遍歷以root為根的文件系統掛載點,p為遍歷過程中的當前結點,返回p的下一個掛載點;vfsmnt_lock可通過內核函數kallsyms_on_each_symbol或kallsyms_lookup_name查找獲得。
2. 再調用內核函數d_path,接口封裝如下
posted @
2016-08-24 19:22 春秋十二月 閱讀(5896) |
評論 (0) |
編輯 收藏
原始套接字具有廣泛的用途,特別是用于自定義協議(標準協議TCP、UDP和ICMP等外)的數據收發。在Linux下攔截套接字IO的一般方法是攔截對應的套接字系統調用,對于發送為sendmsg和sendto,對于接收為recvmsg和recvfrom。這種方法雖然也能攔截原始套接字IO,但要先判斷套接字的類型,如果為SOCK_RAW(原始套接字類型),那么進行攔截處理,這樣一來由于每次IO都要判斷套接字類型,性能就比較低了。因此為了直接針對原始套接字來攔截,提高性能,發明了本方法。
本方法可用于防火墻或主機防護系統中,丟棄接收和發送的攻擊或病毒數據包。
特點
運行在內核態,直接攔截所有進程的原始套接字IO,支持IPv4和IPv6。
實現
原理
在Linux內核網絡子系統中,struct proto_ops結構提供了協議無關的套接字層到協議相關的傳輸層的轉接,而IPv4協議族中內置的inet_sockraw_ops為它的一個實例,對應著原始套接字。因此先找到inet_sockraw_ops,再替換它的成員函數指針recvmsg和sendmsg,就可以實現攔截了。下面以IPv4為例(IPv6同理),說明幾個流程。
搜索inet_sockraw_ops
該流程在掛鉤IO前進行。由于inet_sockraw_ops為Linux內核未導出的內部符號,因此需要通過特別的方法找到它,該特別的方法基于這樣的一個事實:
◆ 所有原始套接字接口均存放在以SOCK_RAW為索引的雙向循環鏈表中,而inet_sockraw_ops就在該鏈表的末尾。
◆ 內核提供了注冊套接字接口的API inet_register_protosw,對于原始套接字類型,該API將輸入的套接字接口插入到鏈表頭后面。
算法如下
注冊p前或注銷p后,鏈表如下
注冊p后,鏈表如下
掛鉤IO
該流程在內核模塊啟動時進行。
卸鉤IO
該流程在內核模塊退出時進行。
運行部署
該方法實現在Linux內核模塊中,為了防止其它內核模塊可能也注冊了原始套接字接口,因此需要在操作系統啟動時優先加載。
posted @
2016-07-14 10:27 春秋十二月 閱讀(2666) |
評論 (3) |
編輯 收藏
TCP連接跟蹤是網絡流控和防火墻中的一項重要的基礎技術,當運用于主機時,連接必與進程相關聯,要么是主動發出的,要么是被動接受的,當后代進程被動態創建時,由于文件描述符的繼承,一個連接就會被這個進程樹中的所有進程共享;當一個進程發出或接受多個連接時,就擁有了多個連接。本方法可用于網絡安全產品中,監控TCP連接及所屬進程,能準確并動態地知道一個連接被哪些進程共享,一個進程擁有哪些連接。
特點
操作系統自帶的netstat工具只是關聯到了一個根進程,無法看到擁有該連接的所有進程,查看進程擁有的全部連接也不方便。該方法的特點是實時跟蹤、查看連接與進程相關信息方便、支持連接的管控。
實現
本方法通過內核安全的十字鏈表實現了連接與進程的相關性,連接信息結構體含有一個所屬進程鏈表頭,進程信息結構體含有一個擁有連接鏈表頭,通過十字鏈表結點鏈接,x方向鏈接到進程的連接鏈表,y方向鏈接到連接的進程鏈表,如下圖所示
進程1為根進程,進程2,...,進程n為進程1的后代進程;連接1,連接2,...,連接n為進程1產生的連接。node(x,y)為十字鏈表結點,用于關聯連接與進程,x對應進程編號,y對應連接編號,每個node包含了所屬的連接和進程指針,每行和每列都是一個雙向循環鏈表(循環未畫出),每個鏈表用一個自旋鎖同步操作。
動態跟蹤的過程包括4個方面:進程創建、進程退出、連接產生、連接銷毀。在Linux下,可通過攔截內核函數do_fork掛鉤進程創建,攔截do_exit掛鉤進程退出;可通過攔截inet_stream_ops的成員函數connect和accept掛鉤連接產生,攔截成員函數release掛鉤連接銷毀。下面為4個方面對應的流程圖,由于所有外層加鎖前已禁止本地中斷和內核搶占,因此內層加鎖前就不必再禁止本地中斷和內核搶占了。
進程創建
將copy_node插入到c的進程鏈表末尾,即為y方向增加(下同);插入到p的連接鏈表末尾,為x方向增加(下同)。
進程退出
從c的進程鏈表中移除node,即為y方向移除(下同);再從p的連接鏈表中移除node,即為x方向移除(下同)。
連接產生
當進程發出連接或接受連接時,調用此流程。
連接銷毀
當某個進程銷毀連接時,調用此流程。
posted @
2016-07-13 11:24 春秋十二月 閱讀(1555) |
評論 (0) |
編輯 收藏
在P2P應用系統中,當需要與處于不同私網的對方可靠通信時,先嘗試TCP打洞穿透,若穿透失敗,再通過處于公網上的代理服務器(下文簡稱proxy)轉發與對方通信,如下圖所示
終端A先連接并發消息msg1到proxy(連接為c1);proxy再發消息msg2給P2P服務器,P2P服務器收到消息后通過已有的連接發消息msg3給終端B,B收到msg3后,連接并發消息msg4到proxy(連接為c2)。這4個消息格式由應用層協議決定,但必須遵守的規范如下:
◆ msg1至少包含B的設備ID。
◆ msg2至少包含B的設備ID和c1的連接ID。
◆ msg3至少包含c1的連接ID和連接代理指示。
◆ msg4至少包含B的設備ID和c1的連接ID。
proxy為多線程架構,當接受到若干連接時,如果數據相互轉發的兩個連接(比如上圖中的c1和c2)不在同一線程,由于一個連接寫數據到另一連接的發送隊列,而另一連接從發送隊列讀數據以發送,那么就要對另一連接的發送隊列(或緩沖區)加鎖,這樣一來由于頻繁的網絡IO而頻繁地加解鎖,降低了轉發效率,因此為了解決這一問題,就需要調度TCP連接到同一線程。
特點
本方法能將數據轉發的兩邊連接放在同一線程,從而避免了數據轉發時的加鎖,由于是一對一的連接匹配,因此也做到了每個線程中連接數的均衡。
實現
工作原理
proxy的主線程負責綁定知名端口并監聽連接,工作線程負責數據轉發。當接受到一個連接時,按輪轉法調度它到某個工作線程,在那個線程內接收分析應用層協議數據,以識別連接類型,即判斷連接是來自數據請求方還是數據響應方,為統一描述,這里把前者特稱為客戶連接,后者為服務連接,連接所在的線程為宿主線程。如果是客戶連接,那么先通知P2P服務器請求對應的客戶端來連接代理,并等待匹配;如果是服務連接,那么就去匹配客戶連接,在匹配過程中,如果服務連接和客戶連接不在同一線程內,那么就會調度到客戶連接的宿主線程,匹配成功后,就開始轉發數據。
為了加快查找,分2個hash表存放連接,客戶連接放在客戶連接hash表中,以連接ID為鍵值;服務連接放在服務連接hash表中,以設備ID為鍵值。
TCP連接調度
包括新連接的輪轉、識別連接類型、匹配客戶連接1、匹配客戶連接2和關閉連接共5個流程,如下一一所述。
新連接的輪轉
該流程工作在主線程,如下圖所示
索引i初始為0,對于新來的連接,由于還不明確連接類型,所以先放入客戶連接表中。
識別連接類型
該流程工作在工作線程,當接受到一個連接時開始執行,如下圖所示
當連接類型為服務連接時,從客戶連接表轉移到服務連接表。
匹配客戶連接1
該流程工作在工作線程,當接受到一個服務連接時開始執行,如下圖所示
匹配客戶連接2
該流程工作在工作線程,當服務連接移到客戶連接的宿主線程時開始執行,如下圖所示
這里的流程和匹配客戶連接流程1有些類似,看起來好像做了重復的判斷操作,但這是必要的,因為在服務連接轉移到另一線程這個瞬間內,客戶連接有可能斷開了,也有可能斷開后又來了一個相同連接ID的其它客戶連接,所以要重新去客戶連接表查找一次,然后進行4個分支判斷。
關閉連接
該流程工作在工作線程內,當連接斷開或空閑時執行。當一邊讀數據出錯時,不能馬上關閉另一邊連接,得在另一邊緩沖區數據發送完后才能關閉;當一邊連接寫數據出錯時,可以馬上關閉另一邊連接,如下圖所示
posted @
2016-07-12 16:59 春秋十二月 閱讀(1830) |
評論 (0) |
編輯 收藏
摘要: 為了使nginx支持windows服務,本文闡述以下主要的改進實現。ngx_main函數 為了在SCM服務中復用main函數的邏輯,將其重命名為ngx_main,并添加第3個參數is_scm以兼容控制臺運行方式,聲明在core/nginx.h中。
Code highligh...
閱讀全文
posted @
2016-07-12 15:31 春秋十二月 閱讀(4525) |
評論 (0) |
編輯 收藏
1 struct state_machine {
2 int state;
3  4
4 };
5 6 enum {
7 s1,
8 s2,
9 10 sn
11 };
假設s1為初始狀態,狀態變遷為s1->s2->...->sn。
常規實現 狀態機處理函數state_machine_handle通常在一個循環內或被事件驅動框架調用,輸入data會隨時序變化,從而引起狀態的變遷,偽代碼框架如下。
1 void handle_s1(struct state_machine *sm, void *data)
void handle_s1(struct state_machine *sm, void *data)
2
 {
{
3 //do something about state 1
//do something about state 1
4 if(is_satisfy_s2(data))
5 sm->state = s2;
6 }
}
7
8void handle_s2(struct state_machine *sm, void *data)
9{
10 //do something about state 2
11 if(is_satisfy_s3(data))
12 sm->state = s3;
13}
14
15void handle_sn_1(struct state_machine *sm, void *data)
16{
17 //do something about state n-1
18 if(is_satisfy_sn(data))
19 sm->state = sn;
20}
21
22void state_machine_handle(struct state_machine *sm, void *data)
23{
24
 switch(sm->state){
switch(sm->state){
25 case s1:
26 handle_s1(sm,data);
27 break;
28
29 case s2:
30 handle_s2(sm,data);
31 break;
32
33 case sn:
34 handle_sn(sm,data);
35 break;
36 }
}
37} sm->state初始化為s1。
改進實現
為了免去丑陋的switch case分支結構,在state_machine內用成員函數指針handler替代了state,改進后的框架如下。
1 struct state_machine;
struct state_machine;
2typedef void (*state_handler)(struct state_machine*,void*);
3
4
 struct state_machine {
struct state_machine {
5 state_handler handler;
state_handler handler;
6
7 };
};
8
9void handle_s1(struct state_machine *sm, void *data)
10{
11 //do something about state 1
12 if(is_satisfy_s2(data))
13 sm->handler = handle_s2;
14}
15
16void handle_s2(struct state_machine *sm, void *data)
17{
18 //do something about state 2
19 if(is_satisfy_s3(data))
20 sm->handler = handle_s3;
21}
22
23void handle_sn_1(struct state_machine *sm, void *data)
24{
25 //do something about state n-1
26 if(is_satisfy_sn(data))
27 sm->handler = handle_sn;
28}
29
30void state_machine_handle(struct state_machine *sm, void *data)
31{
32 sm->handler(sm, data);
33}
sm->handler初始化為handle_s1,該方法在性能上應略優于常規方法,而且邏輯更清晰自然,非常適合于網絡流的處理,在nginx中分析http和email協議時,得到了廣泛應用。
posted @
2016-05-05 09:46 春秋十二月 閱讀(4096) |
評論 (1) |
編輯 收藏 由于使用objdump反匯編linux內核的輸出太多(2.6.32-220.el6.x86_64統計結果為1457706行),而很多時候只是想查看特定部分的機器碼與匯編指令,例如函數的入口、堆棧、調用了哪個函數等,為了高效和通用,因此編寫了一個簡單的awk腳本,其命令行參數說明如下:
● SLINE表示匹配的起始行號(不小于1),SPAT表示匹配的起始行模式,這兩個只能有一個生效,當都有效時,以SLINE為準。
● NUM表示從起始行開始的連續輸出行數(不小于1,含起始行),EPAT表示匹配的結束行模式,這兩個只能有一個生效,當都有效時,以NUM為準。
腳本實現 檢查傳值 由于向腳本傳入的值在BEGIN塊內沒生效,在動作塊{}和END塊內有效,但若在{}內進行檢查則太低效,因為處理每條記錄都要判斷,所以為了避免在{}內進行多余的判斷,就在BEGIN塊內解析命令行參數來間接獲得傳值,當傳值無效時,給出提示并退出。
1for(k=1;k<ARGC;++k){
2 str=ARGV[k]
3 if(1==match(str,"SLINE=")){
4 SLINE = substr(str,7)
5 }else if(1==match(str,"SPAT=")){
6 SPAT = substr(str,6)
7 }else if(1==match(str,"NUM=")){
8 NUM = substr(str,5)
9 }else if(1==match(str,"EPAT=")){
10 EPAT = substr(str,6)
11 }
12 }
13
14 if(SLINE<=0 && SPAT==""){
15 print "Usage: rangeshow must specifies valid SLINE which must be greater than 0, or SPAT which can't be empty"
16 exit 1
17 }
18
19 if(NUM<=0 && EPAT==""){
20 print "Usage: rangeshow must specifies valid NUM which must be greater than 0, or EPAT which can't be empty"
21 exit 1
22} 結束處理 當處理了NUM條記錄或匹配了結束行模式時,應退出動作塊{}。
1if(0==start_nr){
2
3}else{
4 if(NUM>0) {
5 if(NR<start_nr+NUM) {
6 ++matched_nr
7 print $0
8 }else
9 exit 0
10
11 }else{
12 ++matched_nr
13 print $0
14 if(0!=match($0,EPAT))
15 exit 0
16 }
17} 完整腳本下載:
rangeshow。
腳本示例
查看linux內核第10000行開始的10條指令,如下圖
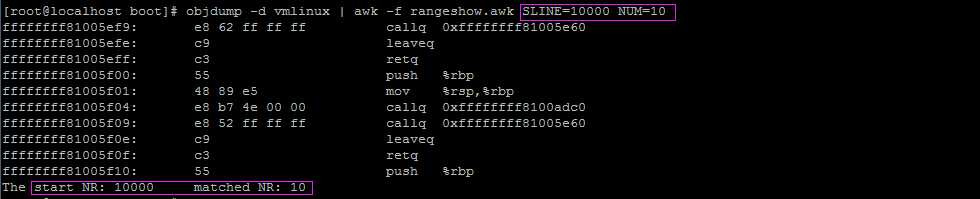
查看linux內核函數do_fork入口開始的10條指令,如下圖
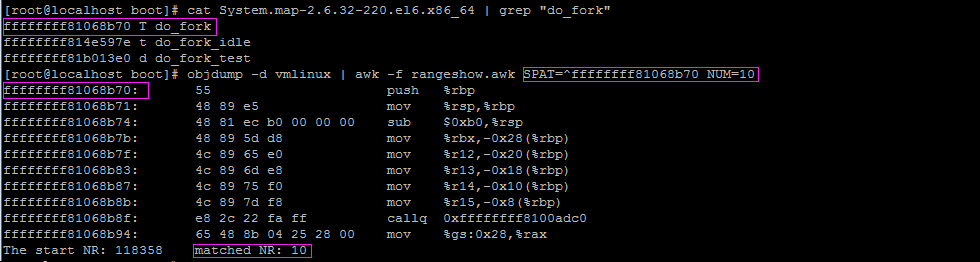
查看linux內核第10000行開始到callq的一段指令,如下圖

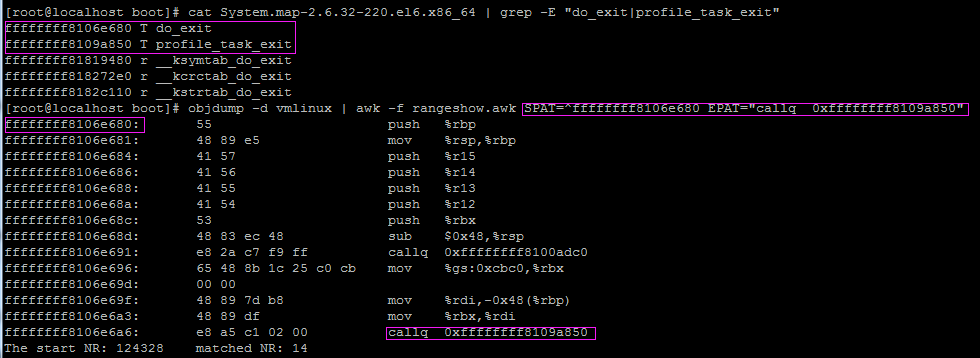
查看linux內核函數do_exit入口到調用profile_task_exit的一段指令,如下圖
posted @
2015-10-27 15:36 春秋十二月 閱讀(1821) |
評論 (1) |
編輯 收藏
本文根據RFC793協議規范和BSD 4.4的實現,總結了
TCP分組丟失時的狀態變遷,如下圖所示:實線箭頭表示客戶端的狀態變遷,線段虛線箭頭表示服務端的狀態變遷,圓點虛線箭頭表示客戶端或服務端的狀態變遷;黑色文字表示正常時的行為,紅色文字表示分組丟失時的行為。
這里假設重傳時分組依然會丟失,當在不同狀態(CLOSED除外)分組丟失后,最終會關閉套接字而回到CLOSED狀態。下面逐個分析各狀態時的情景。
SYN_SENT
連接階段第1次握手,客戶端發送的SYN分組丟失,因此超時收不到服務端的SYN+ACK而重傳SYN,嘗試幾次后放棄,關閉套接字。
SYN_RCVD
1)連接階段第2次握手,服務端響應的SYN+ACK分組丟失,因此超時收不到客戶端的ACK而重傳SYN+ACK,嘗試幾次后放棄,發送RST并關閉套接字。
2)連接階段第3次握手,客戶端發送的ACK分組丟失,因此服務端超時收不到ACK而重傳SYN+ACK,嘗試幾次后放棄,發送RST并關閉套接字。
3)同時打開第2次握手,本端響應的SYN+ACK分組丟失,因此對端超時收不到SYN+ACK而重傳SYN、嘗試幾次后放棄、發送RST并關閉套接字,而此時本端收到RST。
ESTABLISHED
1)連接階段第3次握手,客戶端發送ACK分組后,雖然丟失但會進入該狀態(因為ACK不需要確認),但此時服務端還處于SYN_RCVD狀態,因為超時收不到客戶端的ACK而重傳SYN+ACK、嘗試幾次后放棄、發送RST并關閉套接字,而此時客戶端收到RST。
2)數據傳輸階段,本端發送的Data分組丟失,因此超時收不到對數據的確認而重傳、嘗試幾次后放棄、發送RST并關閉套接字,而此時對端收到RST。
FIN_WAIT_1
1)關閉階段第1次握手,客戶端發送的FIN分組丟失,因此超時收不到服務端的ACK而重傳FIN,嘗試幾次后放棄,發送RST并關閉套接字。
2)關閉階段第2次握手,服務端響應的ACK分組丟失,因此客戶端超時收不到ACK而重傳FIN,嘗試幾次后放棄,發送RST并關閉套接字。
FIN_WAIT_2
關閉階段第3次握手,服務端發送的FIN分組丟失,因此超時收不到客戶端的ACK而重傳FIN、嘗試幾次后放棄、發送RST并關閉套接字,而此時客戶端收到RST。
CLOSING
同時關閉第2次握手,本端發送的ACK分組丟失,導致對端超時收不到ACK而重傳FIN、嘗試幾次后放棄、發送RST并關閉套接字,而此時本端收到RST。
TIME_WAIT
關閉階段第4次握手,客戶端響應的ACK分組丟失,導致服務端超時收不到ACK而重傳FIN、嘗試幾次后放棄、發送RST并關閉套接字,而此時客戶端收到RST。
CLOSE_WAIT
關閉階段第2次握手,服務端響應的ACK分組丟失,導致客戶端超時收不到ACK而重傳FIN、嘗試幾次后放棄、發送RST并關閉套接字,而此時服務端收到RST。
LAST_ACK
關閉階段第3次握手,服務端發送的FIN分組丟失,導致超時收不到客戶端的ACK而重傳FIN、嘗試幾次后放棄、發送RST并關閉套接字。
posted @
2015-10-05 00:44 春秋十二月 閱讀(3344) |
評論 (1) |
編輯 收藏
摘要: 由于linux內核中的struct list_head已經定義了指向前驅的prev指針和指向后繼的next指針,并且提供了相關的鏈表操作方法,因此為方便復用,本文在它的基礎上封裝實現了一種使用開鏈法解決沖突的通用內核Hash表glib_htable,提供了初始化、增加、查找、刪除、清空和銷毀6種操作,除初始化和銷毀外,其它操作都做了同步,適用于中斷和進程上下文。...
閱讀全文
posted @
2015-09-15 17:18 春秋十二月 閱讀(2231) |
評論 (0) |
編輯 收藏