關于快速排序
我們都知道快速排序有很好的O(nlogn),那么更快的快速排序在哪里呢?下面是我的學習記錄。
--By JonsenElizee 2010/09/23
常規的快速排序
學習快速排序,最讓人熟悉的是兩個ptr左右來回指,一次排序后就把一個mid值放在了合適的位置上。這是我一個朋友的非遞歸的C++實現。我改寫一點點,就是加了C的rand()來設置數組值,然后編譯運行這個算法,你可能還不能隨隨便便的寫出這個算法,但效果真的很不樂觀,也不知道要運行多久才能排序完26*50的字符串。后面我們會看到一個很精悍的算法。。。
1 #include <stack>
2 #include <vector>
3 #include <iostream>
4 #include <stdlib.h>
5 #include <stdio.h>
6 #include <time.h>
7
8 using namespace std;
9
10 typedef struct _record
11 {
12 int begin;
13 int end;
14 }record;
15
16 void quick_sort(int a[],int len)
17 {
18 vector<record> do_job;
19 record temp;
20 temp.begin = 0;
21 temp.end = len-1;
22 do_job.push_back(temp);
23
24 while (do_job.size() != 0) {
25 record temp = do_job.back();
26 do_job.pop_back();
27
28 int low = temp.begin;
29 int high = temp.end;
30 int key = a[low];
31 while (low < high) {
32 while(low < high && a[high] >= key) high--;
33 a[low] = a[high];
34 while(low < high && a[low] <= key) low++;
35 a[high] = a[low];
36 }
37 a[low] = key;
38
39 record temp1;
40 temp1.begin = temp.begin;
41 temp1.end = low-1;
42 if (temp1.begin < temp1.end) { do_job.push_back(temp1); }
43
44 record temp2;
45 temp2.begin = low+1;
46 temp2.end = temp.end;
47 if (temp2.begin < temp2.end) { do_job.push_back(temp2); }
48 }
49 }
50 int main()
51 {
52 int a[26*50];
53 int i = 0;
54 while(i < 26*50) a[i] = rand() % 100;
55 int count =sizeof(a) / sizeof(int);
56 quick_sort(a,count);
57 for (int i = 0; i < count; i++) cout<<a[i]<<endl;
58 return 0;
59 }
60
更簡更快快速排序
這種快速排序不是最快的,特別是基本有序時會退化到O(n^2),理論上基于比較的排序不會小于O(nlogn),但還是有加速的可能。下面這個是《Programming Pearls 2nd》里面的方法,這個算法真的很精悍,運行完26*50的一個排序,只需要0.09秒,我的實現如下。
運行時是給的一個長度為26*50的一個字符數組,對它進行排序:

更簡更快快速排序++
研究上面算法的執行過程,遵循大師的思路,我改寫了算法,在我的X61+Redhat EL5上運行速度比上面的算法快了8倍,也就是運行完26*50長的排序,只需要0.01秒!最后我明白一個道理,要有思想,要有毅力,要有實踐。完稿時,我發現這個算法還有改進的余地。特和大家分享。多多指點。
運行輸入和quick.c中的一樣:

運行結果對比
常規的那個非遞歸的算法從我寫這個文件到現在,它還在運行著。。。
第二個和第三個時間對比如下圖:
(加不加優化-O3都是一樣的結果,在我的X61上,gcc version 4.1.2 20080704 (Red Hat 4.1.2-48))
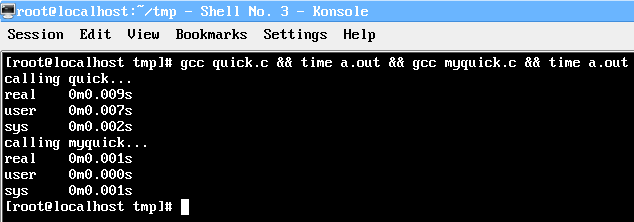
改進的myquick.c的運行時間是quick.c的1/9。
最后,我不得不用Ctrl+C把那個常規的給KILL掉。
Real, User and Sys process time statistics
One of these things is not like the other. Real refers to actual elapsed
time; User and Sys refer to CPU time used only by the process.
*Real is wall clock time - time from start to finish of the call.
This is all elapsed time including time slices used by other processes
and time the process spends blocked (for example if it is waiting for
I/O to complete).
*User is the amount of CPU time spent in user-mode code (outside the
kernel) within the process. This is only actual CPU time used in
executing the process. Other processes and time the process spends
blocked do not count towards this figure.
*Sys is the amount of CPU time spent in the kernel within the
process. This means executing CPU time spent in system calls within the
kernel, as opposed to library code, which is still running in
user-space. Like 'user', this is only CPU time used by the process.
User+Sys will tell you how much actual CPU time your process used.
源代碼
核心算法對比圖
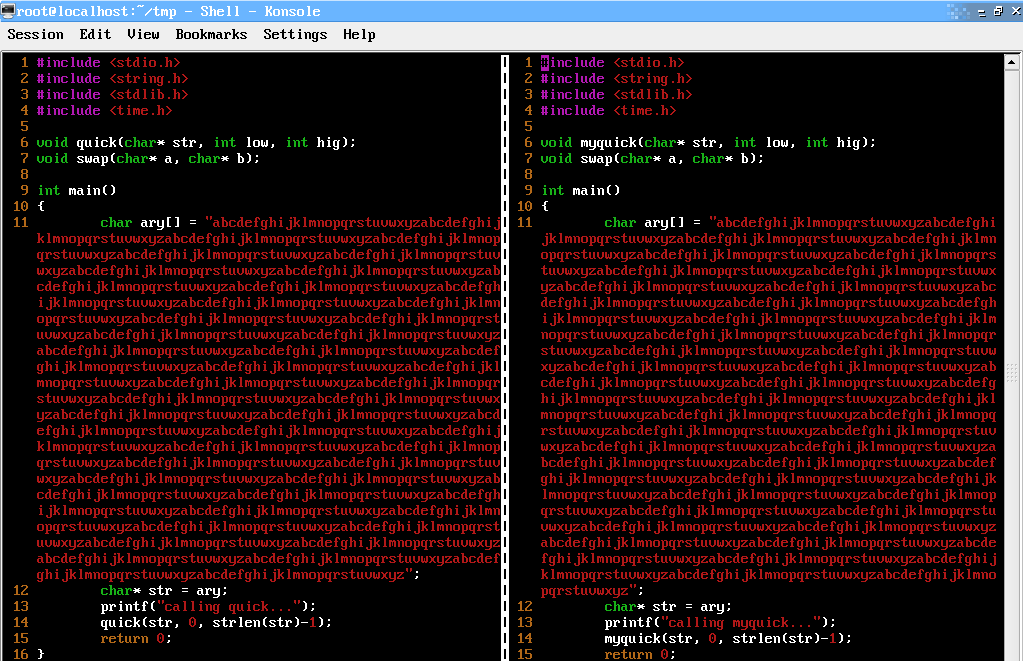
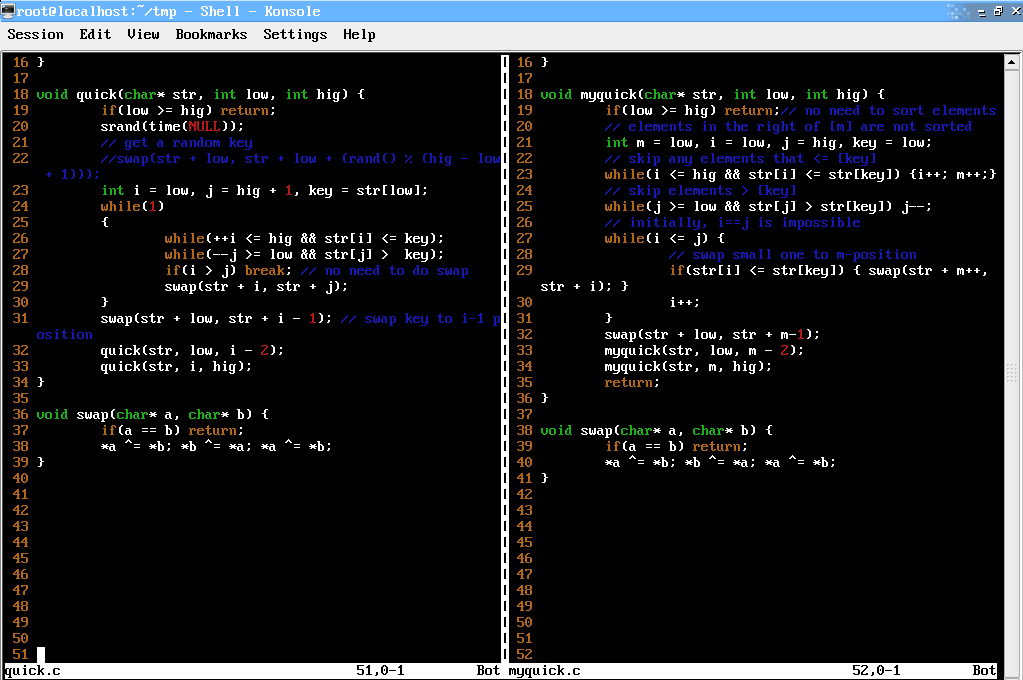
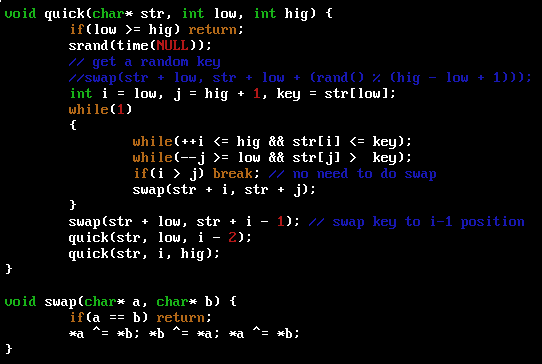
quick.c源代碼
1 #include <stdio.h>
2 #include <string.h>
3 #include <stdlib.h>
4 #include <time.h>
5
6 void quick(char* str, int low, int hig);
7 void swap(char* a, char* b);
8
9 int main()
10 {
11 char ary[] = //26*50長的字符串數組,內容參考上圖。
12 char* str = ary;
13 printf("calling quick ");
");
14 quick(str, 0, strlen(str)-1);
15 return 0;
16 }
17
18 void quick(char* str, int low, int hig) {
19 if(low >= hig) return;
20 srand(time(NULL));
21 // get a random key
22 //swap(str + low, str + low + (rand() % (hig - low + 1)));
23 int i = low, j = hig + 1, key = str[low];
24 while(1)
25 {
26 while(++i <= hig && str[i] <= key);
27 while(--j >= low && str[j] > key);
28 if(i > j) break; // no need to do swap
29 swap(str + i, str + j);
30 }
31 swap(str + low, str + i - 1); // swap key to i-1 position
32 quick(str, low, i - 2);
33 quick(str, i, hig);
34 }
35
36 void swap(char* a, char* b) {
37 if(a == b) return;
38 *a ^= *b; *b ^= *a; *a ^= *b;
39 }
40
myquick.c源代碼
1 #include <stdio.h>
2 #include <string.h>
3 #include <stdlib.h>
4 #include <time.h>
5
6 void myquick(char* str, int low, int hig);
7 void swap(char* a, char* b);
8
9 int main()
10 {
11 char ary[] = //26*50長的字符串,同quick.c的輸入。
12 char* str = ary;
13 printf("calling myquick");
14 myquick(str, 0, strlen(str)-1);
15 return 0;
16 }
17
18 void myquick(char* str, int low, int hig) {
19 if(low >= hig) return;// no need to sort elements
20 // elements in the right of [m] are not sorted
21 int m = low, i = low, j = hig, key = low;
22 // skip any elements that <= [key]
23 while(i <= hig && str[i] <= str[key]) {i++; m++;}
24 // skip elements > [key]
25 while(j >= low && str[j] > str[key]) j--;
26 // initially, i==j is impossible
27 while(i <= j) {
28 // swap small one to m-position
29 if(str[i] <= str[key]) { swap(str + m++, str + i); }
30 i++;
31 }
32 swap(str + low, str + m-1);
33 myquick(str, low, m - 2);
34 myquick(str, m, hig);
35 return;
36 }
37
38 void swap(char* a, char* b) {
39 if(a == b) return;
40 *a ^= *b; *b ^= *a; *a ^= *b;
41 }
42