µłæõ╗¼ķāĮń¤źķüōÕ┐½ķƤµÄÆÕ║ŵ£ēÕŠłÕźĮńÜ?/font>O(nlogn)ÕQīķéŻõ╣łµø┤Õ┐½ńÜäÕ┐½ķƤµÄÆÕ║ÅÕ£©Õō¬ķćīÕæó’╝¤õĖŗķØ󵜻µłæńÜäÕŁ”õ╣ĀĶ«░ÕĮĢŃĆ?/font>
ÕQŹ’╝ŹBy JonsenElizee 2010/09/23
ÕĖĖĶ¦äńÜäÕ┐½ķƤµÄÆÕ║?/font>
ÕŁ”õ╣ĀÕ┐½ķƤµÄÆÕ║Å’╝īµ£ĆĶ«®õØhń夵éēńÜ䵜»õĖżõĖ¬ptrÕĘ”ÕÅ│µØźÕø×µīć’╝īõĖĆŗŲĪµÄÆÕ║ÅÕÉÄ׫▒µŖŖõĖĆõĖ?/font>midÕĆ╝µöŠÕ£©õ║åÕÉłķĆéńÜäõĮŹńĮ«õĖŖŃĆéĶ┐Öµś»µłæõĖĆõĖ¬µ£ŗÕÅŗńÜäķØ×ķĆÆÕĮÆńÜ?/font>CÕQŗ’╝ŗÕ«×ńÄ░ŃĆ鵳æµö╣ÕåÖõĖĆńé╣ńé╣ÕQīÕ░▒µś»ÕŖĀõ║?/font>CńÜ?/font>rand()µØźĶ«ŠŠ|«µĢ░ŠläÕĆ¹|╝īńäČÕÉÄŠ~¢Ķ»æśqÉĶĪīśqÖõĖ¬ĮÄŚµ│ĢÕQīõĮĀÕÅ»ĶāĮśqśõĖŹĶāĮķÜÅķÜÅõŠ┐õŠ┐ńÜäÕåÖÕć║śqÖõĖ¬ĮÄŚµ│ĢÕQīõĮåµĢłµ×£ń£¤ńÜäÕŠłõĖŹõ╣ÉĶ¦éÕQīõ╣¤õĖŹń¤źķüōĶ”üśqÉĶĪīÕżÜõ╣ģµēŹĶāĮµÄÆÕ║ÅÕ«?6*50ńÜäÕŁŚĮW”õĖ▓ŃĆéÕÉÄķØóµłæõ╗¼õ╝Üń£ŗÕł░õĖĆõĖ¬ÕŠłŠ_ŠµéŹńÜäń«Śµ│ĢŃĆéŃĆéŃĆ?/font>
2 #include <vector>
3 #include <iostream>
4 #include <stdlib.h>
5 #include <stdio.h>
6 #include <time.h>
7
8 using namespace std;
9
10 typedef struct _record
11 {
12 int begin;
13 int end;
14 }record;
15
16 void quick_sort(int a[],int len)
17 {
18 vector<record> do_job;
19 record temp;
20 temp.begin = 0;
21 temp.end = len-1;
22 do_job.push_back(temp);
23
24 while (do_job.size() != 0) {
25 record temp = do_job.back();
26 do_job.pop_back();
27
28 int low = temp.begin;
29 int high = temp.end;
30 int key = a[low];
31 while (low < high) {
32 while(low < high && a[high] >= key) high--;
33 a[low] = a[high];
34 while(low < high && a[low] <= key) low++;
35 a[high] = a[low];
36 }
37 a[low] = key;
38
39 record temp1;
40 temp1.begin = temp.begin;
41 temp1.end = low-1;
42 if (temp1.begin < temp1.end) { do_job.push_back(temp1); }
43
44 record temp2;
45 temp2.begin = low+1;
46 temp2.end = temp.end;
47 if (temp2.begin < temp2.end) { do_job.push_back(temp2); }
48 }
49 }
50 int main()
51 {
52 int a[26*50];
53 int i = 0;
54 while(i < 26*50) a[i] = rand() % 100;
55 int count =sizeof(a) / sizeof(int);
56 quick_sort(a,count);
57 for (int i = 0; i < count; i++) cout<<a[i]<<endl;
58 return 0;
59 }
60
µø┤ń«Ćµø┤Õ┐½Õ┐½ķƤµÄÆÕ║?/font>
śqÖń¦ŹÕ┐½ķƤµÄÆÕ║ÅõĖŹµś»µ£ĆÕ┐½ńÜäÕQīńē╣Õł½µś»Õ¤║µ£¼µ£ēÕ║ŵŚČõ╝ÜķĆĆÕī¢Õł░O(n^2)ÕQīńÉåĶ«▐ZĖŖÕ¤▐Z║ĵ»öĶŠāńÜäµÄÆÕ║ÅõĖŹõ╝ÜÕ░Åõ║?/font>O(nlogn)ÕQīõĮåśqśµś»µ£ēÕŖĀķƤńÜäÕÅ»ĶāĮŃĆéõĖŗķØóĶ┐ÖõĖ¬µś»ŃĆ?/font>Programming Pearls 2ndŃĆŗķćīķØóńÜäµ¢ęÄ│ĢÕQīĶ┐ÖõĖ¬ń«Śµ│Ģń£¤ńÜäÕŠłŠ_ŠµéŹÕQīĶ┐ÉĶĪīÕ«ī26*50ńÜäõĖĆõĖ¬µÄÆÕ║Å’╝īÕŬķ£ĆĶ”?.09┐UÆ’╝īµłæńÜäÕ«×ńÄ░Õ”éõĖŗŃĆ?/font>
śqÉĶĪīµŚČµś»ŠlÖńÜäõĖĆõĖ¬ķĢ┐Õ║”õžō26*50ńÜäõĖĆõĖ¬ÕŁŚĮW”µĢ░Šlä’╝īÕ»╣Õ«āśqøĶĪīµÄÆÕ║ÅÕQ?/font>

µø┤ń«Ćµø┤Õ┐½Õ┐½ķƤµÄÆÕ║Å’╝ŗÕQ?/font>
ńĀöń®ČõĖŖķØóĮÄŚµ│ĢńÜäµē¦ĶĪīĶ┐ćĮEŗ’╝īķüĄÕ¾@Õż¦ÕĖłńÜäµĆØĶĄ\ÕQīµłæµö╣ÕåÖõ║åń«Śµ│Ģ’╝īÕ£©µłæńÜ?/font>X61ÕQ?/font>Redhat EL5õĖŖĶ┐ÉĶĪīķƤÕ║”µ»öõĖŖķØóńÜäĮÄŚµ│ĢÕ┐½õ║å8ÕĆŹ’╝īõ╣¤Õ░▒µś»Ķ┐ÉĶĪīÕ«ī26*50ķĢ┐ńÜäµÄÆÕ║ÅÕQīÕŬķ£ĆĶ”?.01┐UÆ’╝üµ£ĆÕÉĵłæµśÄńÖĮõĖĆõĖ¬ķüōńÉå’╝īĶ”üµ£ēµĆصā│ÕQīĶ”üµ£ēµ»ģÕŖø’╝īĶ”üµ£ēÕ«×ĶĘĄŃĆéÕ«īĮE┐µŚČÕQīµłæÕÅæńÄ░śqÖõĖ¬ĮÄŚµ│Ģśqśµ£ēµö╣Ķ┐øńÜäõĮÖÕ£░ŃĆéńē╣ÕÆīÕż¦Õ«ČÕłåõ║½ŃĆéÕżÜÕżÜµīćńéÅVĆ?/font>
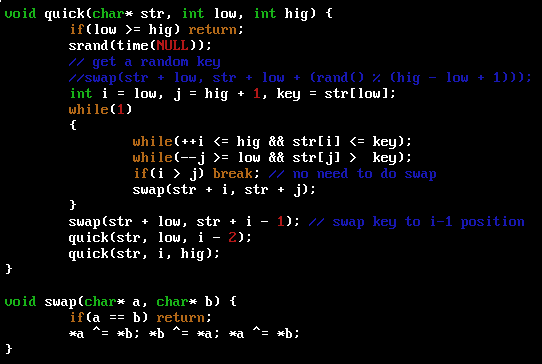
śqÉĶĪīĶŠōÕģźÕÆ?/font>quick.cõĖŁńÜäõĖƵĀ°P╝Ü

śqÉĶĪīŠlōµ×£Õ»ęÄ»ö
ÕĖĖĶ¦äńÜäķéŻõĖ¬ķØ×ķĆÆÕĮÆńÜäń«Śµ│Ģõ╗ĵłæÕåÖśqÖõĖ¬µ¢ćõÜgÕł░ńÄ░Õ£©’╝īÕ«āĶ┐śÕ£©Ķ┐ÉĶĪīńØĆŃĆéŃĆéŃĆ?/font>
ĮW¼õ║īõĖ¬ÕÆīĮW¼õĖēõĖ¬µŚČķŚ┤Õ»╣µ»öÕ”éõĖŗÕøŠÕQ?/font>
(ÕŖĀõĖŹÕŖĀõ╝śÕī¢’╝ŹO3ķāĮµś»õĖƵĀ’LÜäŠlōµ×£ÕQīÕ£©µłæńÜäX61õĖŖ’╝īgcc version 4.1.2 20080704 (Red Hat 4.1.2-48))
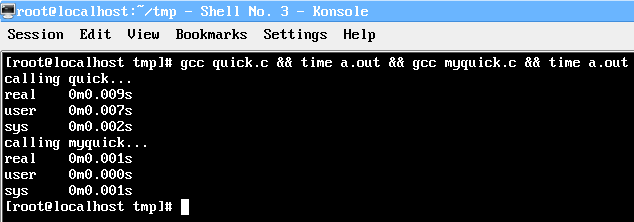
µö╣Ķ┐øńÜ?/font>myquick.cńÜäĶ┐ÉĶĪīµŚČķŚ┤µś»quick.cńÜ?/font>1/9ŃĆ?/font>
µ£ĆÕÉÄ’╝īµłæõĖŹÕŠŚõĖŹńö?/font>CtrlÕQ?/font>CµŖŖķéŻõĖ¬ÕĖĖĶ¦äńÜäŠl?/font>KILLµÄēŃĆ?/font>
One of these things is not like the other. Real refers to actual elapsed time; User and Sys refer to CPU time used only by the process.
*Real is wall clock time - time from start to finish of the call. This is all elapsed time including time slices used by other processes and time the process spends blocked (for example if it is waiting for I/O to complete).
*User is the amount of CPU time spent in user-mode code (outside the kernel) within the process. This is only actual CPU time used in executing the process. Other processes and time the process spends blocked do not count towards this figure.
*Sys is the amount of CPU time spent in the kernel within the process. This means executing CPU time spent in system calls within the kernel, as opposed to library code, which is still running in user-space. Like 'user', this is only CPU time used by the process.
User+Sys will tell you how much actual CPU time your process used.
µ║Éõ╗ŻńĀ?/font>
µĀĖÕ┐āĮÄŚµ│ĢÕ»ęÄ»öÕø?/font>
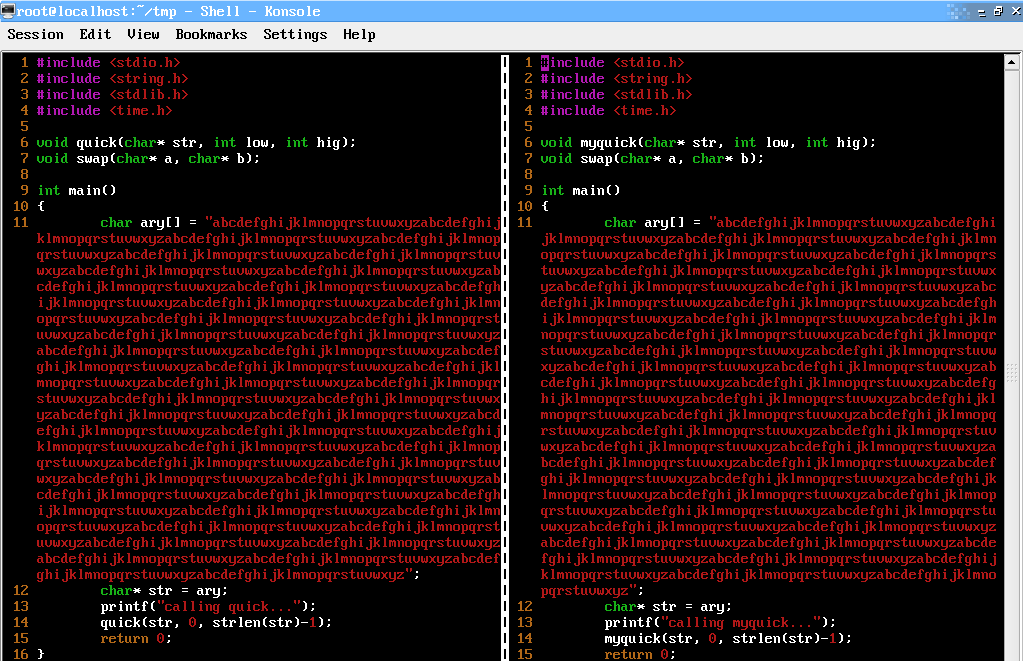
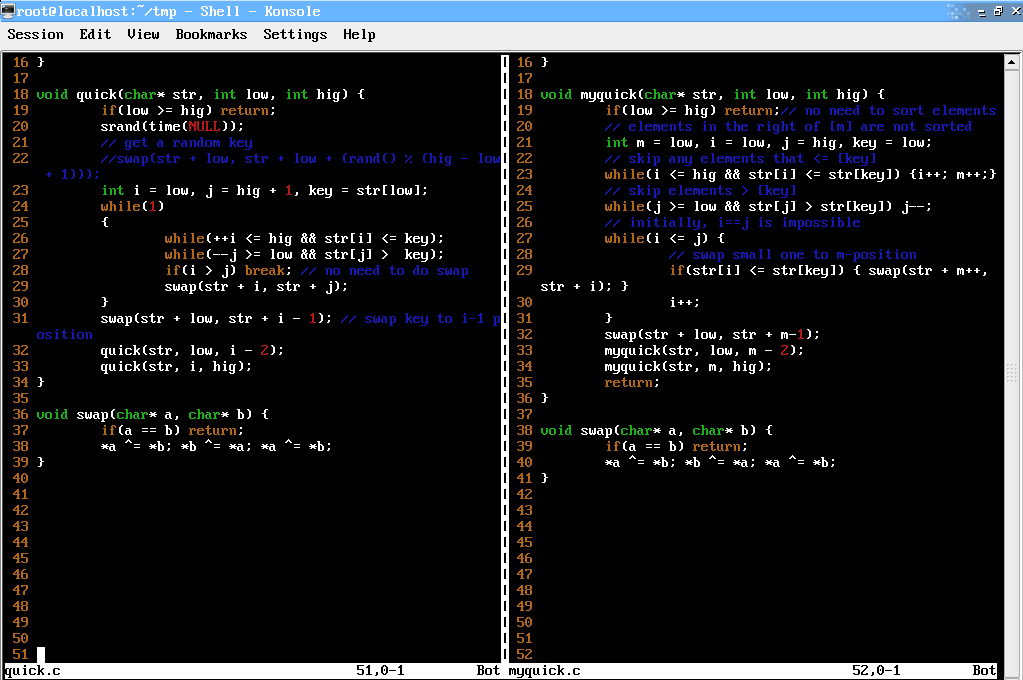
quick.cµ║Éõ╗ŻńĀ?/font>
2 #include <string.h>
3 #include <stdlib.h>
4 #include <time.h>
5
6 void quick(char* str, int low, int hig);
7 void swap(char* a, char* b);
8
9 int main()
10 {
11 char ary[] = ÕQÅ’╝Å26ÕQ?0ķĢ┐ńÜäÕŁŚń¼”õĖ▓µĢ░Šlä’╝īÕåģÕ«╣ÕÅéĶĆāõĖŖÕøŠŃĆ?/span>
12 char* str = ary;
13 printf("calling quick
 ");
");14 quick(str, 0, strlen(str)-1);
15 return 0;
16 }
17
18 void quick(char* str, int low, int hig) {
19 if(low >= hig) return;
20 srand(time(NULL));
21 // get a random key
22 //swap(str + low, str + low + (rand() % (hig - low + 1)));
23 int i = low, j = hig + 1, key = str[low];
24 while(1)
25 {
26 while(++i <= hig && str[i] <= key);
27 while(--j >= low && str[j] > key);
28 if(i > j) break; // no need to do swap
29 swap(str + i, str + j);
30 }
31 swap(str + low, str + i - 1); // swap key to i-1 position
32 quick(str, low, i - 2);
33 quick(str, i, hig);
34 }
35
36 void swap(char* a, char* b) {
37 if(a == b) return;
38 *a ^= *b; *b ^= *a; *a ^= *b;
39 }
40
myquick.cµ║Éõ╗ŻńĀ?/font>
2 #include <string.h>
3 #include <stdlib.h>
4 #include <time.h>
5
6 void myquick(char* str, int low, int hig);
7 void swap(char* a, char* b);
8
9 int main()
10 {
11 char ary[] = ÕQÅ’╝Å26ÕQ?0ķĢ┐ńÜäÕŁŚń¼”õĖįī╝īÕÉīquick.cńÜäĶŠōÕģźŃĆ?/span>
12 char* str = ary;
13 printf("calling myquick
");14 myquick(str, 0, strlen(str)-1);
15 return 0;
16 }
17
18 void myquick(char* str, int low, int hig) {
19 if(low >= hig) return;// no need to sort elements
20 // elements in the right of [m] are not sorted
21 int m = low, i = low, j = hig, key = low;
22 // skip any elements that <= [key]
23 while(i <= hig && str[i] <= str[key]) {i++; m++;}
24 // skip elements > [key]
25 while(j >= low && str[j] > str[key]) j--;
26 // initially, i==j is impossible
27 while(i <= j) {
28 // swap small one to m-position
29 if(str[i] <= str[key]) { swap(str + m++, str + i); }
30 i++;
31 }
32 swap(str + low, str + m-1);
33 myquick(str, low, m - 2);
34 myquick(str, m, hig);
35 return;
36 }
37
38 void swap(char* a, char* b) {
39 if(a == b) return;
40 *a ^= *b; *b ^= *a; *a ^= *b;
41 }
42
gdb and gdb/mi are essentially the same, except that gdb/mi lets you select the MI protocol version and command set to use (MI - or Machine Interface - is how Eclipse communicates with gdb, rather than using the normal gdb command-line interface). This is useful if you want to do something not supported by the defaults, or have a non-standard gdb, such as used on Mac OS X. gdbserver is a very lightweight debug server used for debugging embedded systems. The normal gdb/mi commands are used, but gdb must be told to connect to a gdbserver running on a remote system. There's an extra tab for specifying this information.