@import url(http://m.shnenglu.com/CuteSoft_Client/CuteEditor/Load.ashx?type=style&file=SyntaxHighlighter.css);@import url(/css/cuteeditor.css);
PNG2BMP.EXE 可以將png圖片轉換成bmp圖片。
下載地址
示例:PNG2BMP.EXE -X C:\\1.PNG -O 1.bmp -D c:\\
命令參數如下:
png2bmp, a PNG-to-BMP converter - version 1.62 (Sep 4, 2005)
Copyright (C) 1999-2005 MIYASAKA Masaru
Compiled with libpng 1.2.8 and zlib 1.2.3.
Usage: png2bmp.exe [-switches] inputfile(s)  or: | png2bmp.exe [-switches] |
List of input files may use wildcards (* and ?)
Output filename is same as input filename, but extension .bmp
Switches (case-insensitive) :
-A Preserve alpha channel (save in 32bit ARGB BMP format)
-B Preserve alpha channel (save in 32bit Bitfield BMP format)
-R Convert transparent color to alpha channel (use with -A or -B)
-O name Specify name for output file
-D dir Output files into dir
-E Delete input files after successful conversion
-T Set the timestamp of input file on output file
-Q Quiet mode
-L Log errors to .\P2BERROR.LOG file
-X Disable conversion through standard input/output
or: | png2bmp.exe [-switches] |
List of input files may use wildcards (* and ?)
Output filename is same as input filename, but extension .bmp
Switches (case-insensitive) :
-A Preserve alpha channel (save in 32bit ARGB BMP format)
-B Preserve alpha channel (save in 32bit Bitfield BMP format)
-R Convert transparent color to alpha channel (use with -A or -B)
-O name Specify name for output file
-D dir Output files into dir
-E Delete input files after successful conversion
-T Set the timestamp of input file on output file
-Q Quiet mode
-L Log errors to .\P2BERROR.LOG file
-X Disable conversion through standard input/output
posted @
2012-11-19 17:24 王海光 閱讀(1843) |
評論 (0) |
編輯 收藏
摘要: 以下實現適用于24位BMP圖片: Code highlighting produced by Actipro CodeHighlighter (freeware)http://www.CodeHighlighter.com/--> 1 //單擊一個Button,保存位圖 2 void CDlgDlg::OnButton1() ...
閱讀全文
posted @
2012-11-19 17:19 王海光 閱讀(7171) |
評論 (2) |
編輯 收藏1.介紹
gSOAP編譯工具提供了一個SOAP/XML 關于C/C++ 語言的實現,從而讓C/C++語言開發web服務或客戶端程序的工作變得輕松了很多。絕大多數的C++web服務工具包提供一組API函數類庫來處理特定的SOAP數據結構,這樣就使得用戶必須改變程序結構來適應相關的類庫。與之相反,gSOAP利用編譯器技術提供了一組透明化的SOAP API,并將與開發無關的SOAP實現細節相關的內容對用戶隱藏起來。gSOAP的編譯器能夠自動的將用戶定義的本地化的C或C++數據類型轉變為符合XML語法的數據結構,反之亦然。這樣,只用一組簡單的API就將用戶從SOAP細節實現工作中解脫了出來,可以專注與應用程序邏輯的實現工作了。gSOAP編譯器可以集成C/C++和Fortran代碼(通過一個Fortran到C的接口),嵌入式系統,其他SOAP程序提供的實時軟件的資源和信息;可以跨越多個操作系統,語言環境以及在防火墻后的不同組織。
gSOAP使編寫web服務的工作最小化了。gSOAP編譯器生成SOAP的代碼來序列化或反序列化C/C++的數據結構。gSOAP包含一個WSDL生成器,用它來為你的web服務生成web服務的解釋。gSOAP的解釋器及導入器可以使用戶不需要分析web服務的細節就可以實現一個客戶端或服務端程序。下面是gSOAP的一些特點:
l gSOAP編譯器可以根據用戶定義的C和C++數據結構自動生成符合SOAP的實例化代碼。
l gSOAP支持WSDL 1.1, SOAP 1.1, SOAP 1.2, SOAP RPC 編碼方式以及 literal/document 方式.
l gSOAP是少數完全支持SOAP1.1 RPC編碼功能的工具包,包括多維數組及動態類型。比如,一個包含一個基類參數的遠程方法可以接收客戶端傳來的子類實例。子類實例通過動態綁定技術來保持一致性。
l gSOAP 支持 MIME (SwA) 和 DIME 附件包。
l gSOAP是唯一支持DIME附件傳輸的工具包。它允許你在保證XML可用性的同時能夠以最快的方式(流方式)傳遞近乎無大小限制的二進制數據。
l gSOAP 支持 SOAP-over-UDP。
l gSOAP 支持 IPv4 and IPv6.
l gSOAP 支持 Zlib deflate and gzip compression (for HTTP, TCP/IP, and XML file storage)。
l gSOAP 支持 SSL (HTTPS)。
l gSOAP 支持 HTTP/1.0, HTTP/1.1 保持連接, 分塊傳輸及基本驗證。
l gSOAP 支持 SOAP 單向消息。
l gSOAP 包含一個 WSDL 生成器,便于web服務的發布。
l gSOAP 包含一個WSDL解析器 (將WSDL轉換為gSOAP頭文件),可以自動化用戶客戶端及服務端的開發。
l 生成可以單獨運行的web服務及客戶端程序。
l 因為只需要很少內存空間,所以可以運行在類似Palm OS, Symbian, Pocket PC的小型設備中。
l 適用于以C或C++開發的web服務中。
l 跨平臺:Windows, Unix, Linux, Mac OS X, Pocket PC, Palm OS, Symbian等。
l 支持序列化程序中的本地化C/C++數據結構。
l 可以使用輸入和輸出緩沖區來提高效率,但是不用完全消息緩沖來確定HTTP消息的長度。取而代之的是一個三相序列化方法。這樣,像64位編碼的圖像就可以在小內存設備(如PDA)中以DIME附件或其他方式傳輸。
l 支持C++單繼承,動態綁定,重載,指針結構(列表、樹、圖、循環圖,定長數組,動態數組,枚舉,64位2進制編碼及16進制編碼)。
l 不需要重寫現有的C/C++應用。但是,不能用unions,指針和空指針來作為遠程方法調用參數的數據結構中元素。
l 三相編組:1)分析指針,引用,循環數據結構;2)確定HTTP消息長度;3)將數據序列化位SOAP1.1編碼方式或用戶定義的數據編碼方式。
l 雙相編組:1)SOAP解釋及編碼;2)分解“forward”指針(例如:分解SOAP中的href屬性)。
l 完整可定制的SOAP錯誤處理機制。
l 可定制的SOAP消息頭處理機制,可以用來保持狀態信息
gsoap通常帶有兩個工具: wsdl2h 和 soapcpp2。 wsdl2h主要是用來生成頭文件的,而soapcpp2主要是利用wsdl2h生成的頭文件來生成C文件或C++文件。 以下是README.txt中示例:
Example translation of WSDL to code in two steps:
$ wsdl2h -s -o calc.h http://www.cs.fsu.edu/~engelen/calc.wsdl
posted @
2012-11-16 17:14 王海光 閱讀(3065) |
評論 (0) |
編輯 收藏微軟在XP下提供了一個軟件程序,SYSTEM32\msiexec.exe
在命令行下輸入:msiexec /? 顯示幫助信息,如下:
Windows (R) Installer. V 5.0.7600.16385
msiexec /Option <Required Parameter> [Optional Parameter]
安裝選項
</package | /i> <Product.msi>
安裝或配置產品
/a <Product.msi>
管理安裝 - 在網絡上安裝產品
/j<u|m> <Product.msi> [/t <Transform List>] [/g <Language ID>]
公布產品 - m 公布到所有用戶,u 公布到當前用戶
</uninstall | /x> <Product.msi | ProductCode>
卸載產品
顯示選項
/quiet
安靜模式,無用戶交互
/passive
無人參與模式 - 只顯示進度欄
/q[n|b|r|f]
設置用戶界面級別
n - 無用戶界面
b - 基本界面
r - 精簡界面
f - 完整界面(默認值)
/help
幫助信息
重新啟動選項
/norestart
安裝完成后不重新啟動
/promptrestart
必要時提示用戶重新啟動
/forcerestart
安裝后始終重新啟動計算機
日志選項
/l[i|w|e|a|r|u|c|m|o|p|v|x|+|!|*] <LogFile>
i - 狀態消息
w - 非致命警告
e - 所有錯誤消息
a - 操作的啟動
r - 操作特定記錄
u - 用戶請求
c - 初始用戶界面參數
m - 內存不足或致命退出信息
o - 磁盤空間不足消息
p - 終端屬性
v - 詳細輸出
x - 額外調試信息
+ - 擴展到現有日志文件
! - 每一行刷新到日志
* - 記錄所有信息,除了 v 和 x 選項
/log <LogFile>
與 /l* <LogFile> 相同
更新選項
/update <Update1.msp>[;Update2.msp]
應用更新
/uninstall <PatchCodeGuid>[;Update2.msp] /package <Product.msi | ProductCode>
刪除產品的更新
修復選項
/f[p|e|c|m|s|o|d|a|u|v] <Product.msi | ProductCode>
修復產品
p - 僅當文件丟失時
o - 如果文件丟失或安裝了更舊的版本(默認值)
e - 如果文件丟失或安裝了相同或更舊的版本
d - 如果文件丟失或安裝了不同版本
c - 如果文件丟失或較驗和與計算的值不匹配
a - 強制重新安裝所有文件
u - 所有必要的用戶特定注冊表項(默認值)
m - 所有必要的計算機特定注冊表項(默認值)
s - 所有現有的快捷鍵方式(默認值)
v - 從源運行并重新緩存本地安裝包
設置公共屬性
[PROPERTY=PropertyValue]
請查閱 Windows (R) Installer SDK 獲得有關命令行語法的其他文檔。
版權所有 (C) Microsoft Corporation. 保留所有權利。
此軟件的部分內容系基于 Independent JPEG Group 的工作。
運行CMD后,輸入msiexec /i Product.msi /q 即可安裝msi程序。
運行CMD后,輸入msiexec /x
ProductCode /q 即可卸載msi安裝過的程序。
ProductCode的值可在注冊表中查找,注冊表位置:HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows\CurrentVersion\Uninstall 根據DisplayName鍵值來確定安裝的msi程序,UninstallString的值中包含ProductCode 如:{BC12972C-BF15-4607-A745-948DA0DE63FF}
卸載命令可以寫成如下所示:msiexec /x "{BC12972C-BF15-4607-A745-948DA0DE63FF}" /q posted @
2012-11-15 11:21 王海光 閱讀(3047) |
評論 (0) |
編輯 收藏基數排序(Radix sort)是一種非比較型整數排序算法,其原理是將整數按位數切割成不同的數字,然后按每個位數分別比較。由于整數也可以表達字符串(比如名字或日期)和特定格式的浮點數,所以基數排序也不是只能使用于整數。基數排序的發明可以追溯到1887年赫爾曼·何樂禮在打孔卡片制表機(Tabulation Machine)上的貢獻。
它是這樣實現的:將所有待比較數值(正整數)統一為同樣的數位長度,數位較短的數前面補零。然后,從最低位開始,依次進行一次排序。這樣從最低位排序一直到最高位排序完成以后, 數列就變成一個有序序列。
基數排序時對每一維進行調用子排序算法時要求這個子排序算法必須是穩定的。
基數排序與直覺相反:它是按照從底位到高位的順序排序的。
偽代碼:
RADIX-SORT(A,d)
1 for i <-- 1 to d
2 do use a stable sort to sort array A on digit i
引理8.3: 給定n個d位數,每一個數位可以取k種可能的值,如果所用穩定排序需要Θ(n+k)時間,基數排序能以Θ(d(n+k))的時間完成。
證明:如果采用計數排序這種穩定排序,那么每一遍處理需要時間Θ(n+k),一共需處理d遍,于是基數排序的運行時間為Θ(d(n+k))。當d為常數,k=O(n)時,有線性運行時間。
注:將關鍵字分成若干位方面,可以有一定的靈活性。
引理8.4:給定n個b位數和任何正整數r<=b,如果采用的穩定排序需要Θ(d(n+k))時間,則RADIX-SORT能在Θ((b/r)(n+2r))時間內正確地對這些數進行排序。
證明:對于一個r<=b,將每個關鍵字看成由d=b/r位組成的數,每一個數字都是(0~ -1)之間的一個整數,這樣就可以采取計數排序。K= ,d=b/r,總的運行時間為Θ((b/r)(n+ ))。
對于給定的n值和b值,如何選擇r值使得最小化表達式(b/r)(n+2r)。如果b< lgn,對于任何r<=b的值,都有(n+2r)=Θ(n),于是選擇r=b,使計數排序的時間為Θ((b/b)(n+2b)) = Θ(n)。 如果b>lgn,則選擇r=lgn,可以給出在某一常數因子內的最佳時間:當r=lgn時,算法復雜度為Θ(bn/lgn),當r增大到lgn以上時,分子 增大比分母r快,于是運行時間復雜度為Ω(bn/lgn);反之當r減小到lgn以下的時候,b/r增大,而n+ 仍然是Θ(n)。
以下引自麻省理工學院算法導論——筆記:








以下代碼實例轉自:http://www.docin.com/p-449224125.html
1 以下是用C++實現的基數排序代碼:
2 #include <cstdio>
3 #include <cstdlib>
4 // 這個是基數排序用到的計數排序,是穩定的。
5 // pDigit是基數數組,nMax是基數的上限,pData是待排序的數組, nLen是待排序數組的元素個數
6 // 必須pDigit和pData的下標相對應的,即pDigit[1]對應pData[1]
7 int RadixCountingSort(int *pDigit, int nMax,int *pData,int nLen){
8 // 以下是計數排序
9 int *pCount = new int[nMax];
10 int *pSorted = new int[nLen];
11 int i,j;
12 for(i=0; i<nMax; ++i)
13 pCount[i] = 0;
14 for(i=0; i<nLen; ++i)
15 ++pCount[pDigit[i]];
16 for(i=1; i<nMax; ++i)
17 pCount[i] += pCount[i-1];
18 for(i=nLen-1; i>=0; --i){
19 --pCount[pDigit[i]];
20 pSorted[pCount[pDigit[i]]] = pData[i]; // z這里注意,是把待排序的數組賦值
21 }
22 for(i=0; i<nLen; ++i)
23 pData[i] = pSorted[i];
24 delete [] pCount;
25 delete [] pSorted;
26 return 1;
27 }
28 int RadixSort(int *pData, int nLen){
29 int *pDigit = new int[nLen]; // 申請存放基數(某個位數)的空間
30 int nRadixBase = 1;
31 bool flag = false;
32 while(!flag){
33 flag = true;
34 nRadixBase *= 10;
35 for(int i=0; i<nLen; ++i){
36 pDigit[i] = pData[i]%nRadixBase; // 求出某位上的數當做基數
37 pDigit[i] /= nRadixBase/10;
38 if(pDigit[i] > 0)
39 flag = false;
40 }
41 if(flag)
42 break;
43 RadixCountingSort(pDigit,10,pData,nLen);
44 }
45 delete[] pDigit;
46 return 1;
47 }
48 main()
49 {
50 int nData[10]={43,65,34,5,8,34,23,0,45,34};;
51 RadixSort(nData, 10);
52 printf("經排序后的數列是:\n");
53 for (int i = 0; i < 10; ++i)
54 printf("%d ", nData[i]);
55 printf("\n");
56 return 0;
57 }
posted @
2012-11-13 16:52 王海光 閱讀(731) |
評論 (0) |
編輯 收藏 當輸入的元素是 n 個 0 到 k 之間的整數時,它的運行時間是 Θ(n + k)。計數排序不是比較排序,排序的速度快于任何比較排序算法。
由于用來計數的數組C的長度取決于待排序數組中數據的范圍(等于待排序數組的最大值與最小值的差加上1),這使得計數排序對于數據范圍很大的數組,需要大量時間和內存。例如:計數排序是用來排序0到100之間的數字的最好的算法,但是它不適合按字母順序排序人名。但是,計數排序可以用在基數排序中的算法來排序數據范圍很大的數組。計數排序之所以能夠突破前面所述的Ω(nlgn)極限,是因為它不是基于元素比較的。計數排序適合所需排序的數組元素取值范圍不大的情況(范圍太大的話輔助空間很大)。
定理:任意一個比較排序算法在最壞情況下,都需要做Ω(nlgn)次比較。
算法的步驟如下:
- 找出待排序的數組中最大和最小的元素
- 統計數組中每個值為i的元素出現的次數,存入數組C的第i項
- 對所有的計數累加(從C中的第一個元素開始,每一項和前一項相加)
- 反向填充目標數組:將每個元素i放在新數組的第C(i)項,每放一個元素就將C(i)減去1
以下引自麻省理工學院算法導論——筆記:
Counting sort: No comparisons between elements.
• Input: A[1 . . n], where A[ j]??{1, 2, …, k} .
• Output: B[1 . . n], sorted.
• Auxiliary storage: C[1 . . k] .
Counting sort
for i ← 1 to k
do C[i] ← 0
for j ←1 to n
do C[A[ j]] ← C[A[ j]] + 1 —> C[i] = |{key = i}|
for i ← 2 to k
do C[i] ← C[i] + C[i–1] —>C[i] = |{key ← i}|
for j ← n downto 1
do B[C[A[ j]]] ← A[ j]
C[A[ j]] ← C[A[ j]] – 1
實例:
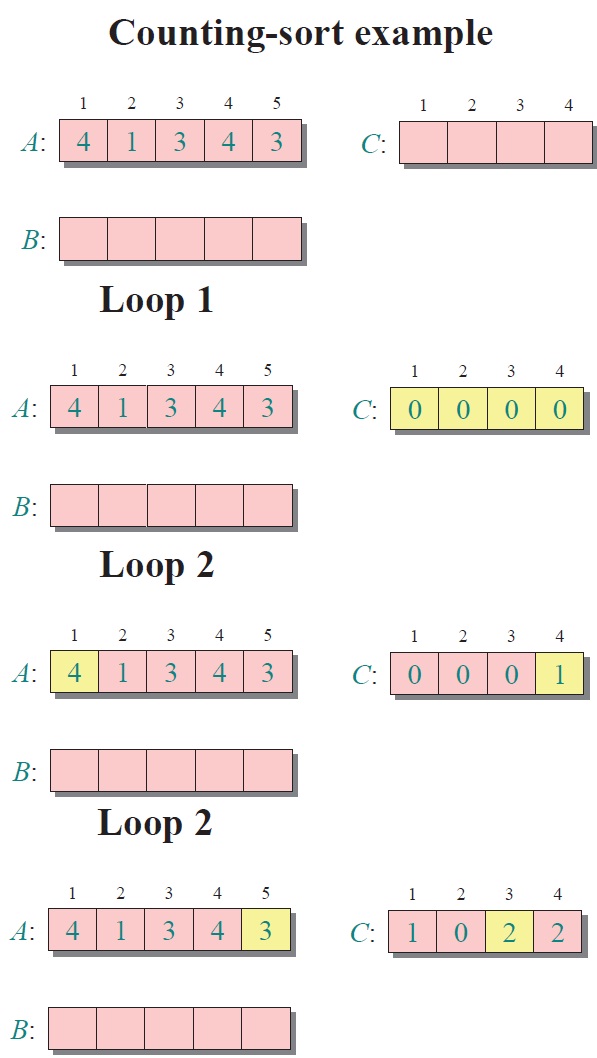
對所有的計數累加(從C中的第一個元素開始,每一項和前一項相加)
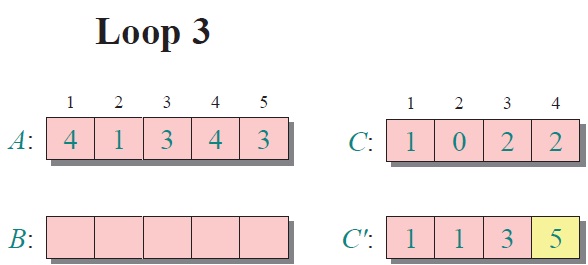
反向填充目標數組:將每個元素i放在新數組的第C(i)項,每放一個元素就將C(i)減去1
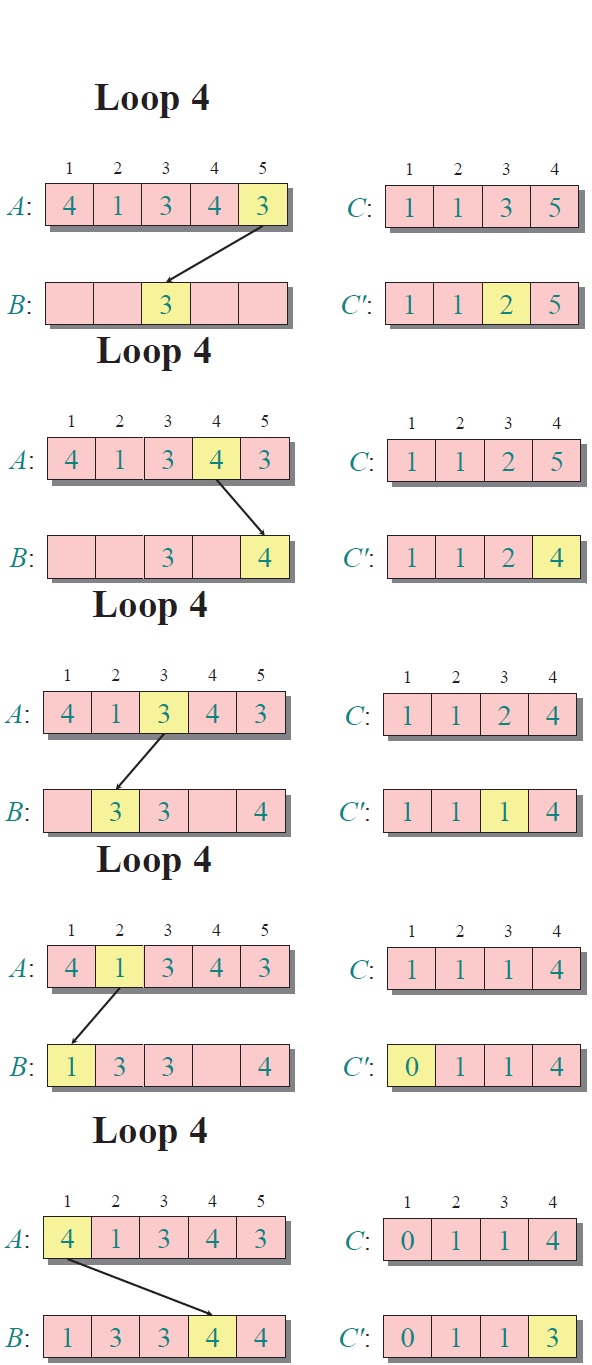


注:基于比較的排序算法的最佳平均時間復雜度為 O(nlogn)
穩定性:算法是穩定的。
如果k小于nlogn可以用計數排序,如果k大于nlogn可以用歸并排序。
代碼實例:
1 C++實現:
2 #include<cstdio>
3 #include<algorithm>
4 using namespace std;
5 //n為數組元素個數,k是最大的那個元素
6 void CountingSort(int *input, int size, int k){
7 int i;
8 int *result = new int[size]; //開辟一個保存結果的臨時數組
9 int *count = new int[k+1]; //開辟一個臨時數組
10 for(i=0; i<=k; ++i)
11 count[i]=0;
12 //使count[i]等于等于i的元素的個數
13 for(i=0; i<size; ++i)
14 ++count[input[i]]; //count數組中坐標為元素input[i]的增加1,即該元素出現的次數加1
15 for(i=1; i<=k; ++i)
16 count[i] += count[i-1];
17 for(i=size-1; i>=0; --i){ //正序來也行,但是到這來可以使排序是穩定的
18 --count[input[i]]; //因為數組下標從0開始,所以這個放在前面
19 result[count[input[i]]] = input[i]; //這個比較繞, count[input[i]-1] 就代表小于等于元素
}
20 copy(result,result+size,input); //調用copy函數把結果存回原數組
21 delete [] result; //記得釋放空間
22 delete [] count;
23 }
24 int main()
25 {
26 int input[11]={2,7,4,9,8,5,7,8,2,0,7};
27 CountingSort(input,11,9);
28 for(int i=0; i<11; ++i)
29 printf("%d ",input[i]);
30 putchar('\n');
31 return 0;
32 }
posted @
2012-11-13 11:07 王海光 閱讀(737) |
評論 (1) |
編輯 收藏
摘要: 1 #============================================================================= 2 本文轉自: http://blog.csdn.net/tge7618291
下載地址1:http:/...
閱讀全文
posted @
2012-11-09 13:59 王海光 閱讀(978) |
評論 (0) |
編輯 收藏
摘要: 為了編譯一個簡單的源文件main.c,需要自動生成一個makefile,以下是步驟:第一步:----------在/root/project/main目錄下創建一個文件main.c,其內容如下:------------------------------------------------#include <stdio.h> int main(int argc, char** argv...
閱讀全文
posted @
2012-11-08 15:37 王海光 閱讀(1511) |
評論 (0) |
編輯 收藏
目的:
基本掌握了 make 的用法,能在Linux系統上編程。
環境:
Linux系統,或者有一臺Linux服務器,通過終端連接。一句話:有Linux編譯環境。
準備:
準備三個文件:file1.c, file2.c, file2.h
file1.c:
#include <stdio.h>
#include "file2.h"
int main()
{
printf("print file1$$$$$$$$$$$$$$$$$$$$$$$$\n");
File2Print();
return 0;
}
file2.h:
#ifndef FILE2_H_
#define FILE2_H_
#ifdef __cplusplus
extern "C" {
#endif
void File2Print();
#ifdef __cplusplus
}
#endif
#endif
file2.c:
#include "file2.h"
void File2Print()
{
printf("Print file2**********************\n");
}
基礎:
先來個例子:
有這么個Makefile文件。(文件和Makefile在同一目錄)
=== makefile 開始 ===
helloworld:file1.o file2.o
gcc file1.o file2.o -o helloworld
file1.o:file1.c file2.h
gcc -c file1.c -o file1.o
file2.o:file2.c file2.h
gcc -c file2.c -o file2.o
clean:
rm -rf *.o helloworld
=== makefile 結束 ===
一個 makefile 主要含有一系列的規則,如下:
A: B
(tab)<command>
(tab)<command>
每個命令行前都必須有tab符號。
上面的makefile文件目的就是要編譯一個helloworld的可執行文件。讓我們一句一句來解釋:
helloworld : file1.o file2.o: helloworld依賴file1.o file2.o兩個目標文件。
gcc File1.o File2.o -o helloworld: 編譯出helloworld可執行文件。-o表示你指定 的目標文件名。
file1.o : file1.c: file1.o依賴file1.c文件。
gcc -c file1.c -o file1.o: 編譯出file1.o文件。-c表示gcc 只把給它的文件編譯成目標文件, 用源碼文件的文件名命名但把其后綴由“.c”或“.cc”變成“.o”。在這句中,可以省略-o file1.o,編譯器默認生成file1.o文件,這就是-c的作用。
file2.o : file2.c file2.h
gcc -c file2.c -o file2.o
這兩句和上兩句相同。
clean:
rm -rf *.o helloworld
當用戶鍵入make clean命令時,會刪除*.o 和helloworld文件。
如果要編譯cpp文件,只要把gcc改成g++就行了。
寫好Makefile文件,在命令行中直接鍵入make命令,就會執行Makefile中的內容了。
到這步我想你能編一個Helloworld程序了。
上一層樓:使用變量
上面提到一句,如果要編譯cpp文件,只要把gcc改成g++就行了。但如果Makefile中有很多gcc,那不就很麻煩了。
第二個例子:
=== makefile 開始 ===
OBJS = file1.o file2.o
CC = gcc
CFLAGS = -Wall -O -g
helloworld : $(OBJS)
$(CC) $(OBJS) -o helloworld
file1.o : file1.c file2.h
$(CC) $(CFLAGS) -c file1.c -o file1.o
file2.o : file2.c file2.h
$(CC) $(CFLAGS) -c file2.c -o file2.o
clean:
rm -rf *.o helloworld
=== makefile 結束 ===
這里我們應用到了變量。要設定一個變量,你只要在一行的開始寫下這個變量的名字,后 面跟一個 = 號,后面跟你要設定的這個變量的值。以后你要引用 這個變量,寫一個 $ 符號,后面是圍在括號里的變量名。
CFLAGS = -Wall -O –g,解釋一下。這是配置編譯器設置,并把它賦值給CFFLAGS變量。
-Wall: 輸出所有的警告信息。
-O: 在編譯時進行優化。
-g: 表示編譯debug版本。
這樣寫的Makefile文件比較簡單,但很容易就會發現缺點,那就是要列出所有的c文件。如果你添加一個c文件,那就需要修改Makefile文件,這在項目開發中還是比較麻煩的。
再上一層樓:使用函數
學到這里,你也許會說,這就好像編程序嗎?有變量,也有函數。其實這就是編程序,只不過用的語言不同而已。
第三個例子:
=== makefile 開始 ===
CC = gcc
XX = g++
CFLAGS = -Wall -O –g
TARGET = ./helloworld
%.o: %.c
$(CC) $(CFLAGS) -c $< -o $@
%.o:%.cpp
$(XX) $(CFLAGS) -c $< -o $@
SOURCES = $(wildcard *.c *.cpp)
OBJS = $(patsubst %.c,%.o,$(patsubst %.cpp,%.o,$(SOURCES)))
$(TARGET) : $(OBJS)
$(XX) $(OBJS) -o $(TARGET)
chmod a+x $(TARGET)
clean:
rm -rf *.o helloworld
=== makefile 結束 ===
函數1:wildcard
產生一個所有以 '.c' 結尾的文件的列表。
SOURCES = $(wildcard *.c *.cpp)表示產生一個所有以 .c,.cpp結尾的文件的列表,然后存入變量 SOURCES 里。
函數2:patsubst
匹配替換,有三個參數。第一個是一個需要匹配的式樣,第二個表示用什么來替換它,第三個是一個需要被處理的由空格分隔的列表。
OBJS = $(patsubst %.c,%.o,$(patsubst %.cc,%.o,$(SOURCES)))表示把文件列表中所有的.c,.cpp字符變成.o,形成一個新的文件列表,然后存入OBJS變量中。
%.o: %.c
$(CC) $(CFLAGS) -c $< -o $@
%.o:%.cpp
$(XX) $(CFLAGS) -c $< -o $@
這幾句命令表示把所有的.c,.cpp編譯成.o文件。
這里有三個比較有用的內部變量。$@ 擴展成當前規則的目的文件名, $< 擴展成依靠 列表中的第一個依靠文件,而 $^ 擴展成整個依靠的列表(除掉了里面所有重 復的文件名)。
chmod a+x $(TARGET)表示把helloworld強制變成可執行文件。
到這里,我想你已經能夠編寫一個比較簡單也比較通用的Makefile文件了,上面所有的例子都假定所有的文件都在同一個目錄下,不包括子目錄。
那么文件不在一個目錄可以嗎?
怎么編寫Makefile生成靜態庫?
你還想更上一層樓嗎?
請聽下回分解。
本文轉自:http://goodcandle.cnblogs.com/archive/2006/03/30/278702.html
posted @
2012-11-08 13:59 王海光 閱讀(475) |
評論 (0) |
編輯 收藏
鉤子(Hook),是Windows消息處理機制的一個平臺,應用程序可以在上面設置子程以監視指定窗口的某種消息,而且所監視的窗口可以是其他進程所創建的。當消息到達后,在目標窗口處理函數之前處理它。鉤子機制允許應用程序截獲處理window消息或特定事件。鉤子實際上是一個處理消息的程序段,通過系統調用,把它掛入系統。每當特定的消息發出,在沒有到達目的窗口前,鉤子程序就先捕獲該消息,亦即鉤子函數先得到控制權。這時鉤子函數即可以加工處理(改變)該消息,也可以不作處理而繼續傳遞該消息,還可以強制結束消息的傳遞。二、運行機制:
1、鉤子鏈表和鉤子子程:每一個Hook都有一個與之相關聯的指針列表,稱之為鉤子鏈表,由系統來維護。這個列表的指針指向指定的,應用程序定義的,被Hook子程調用的回調函數,也就是該鉤子的各個處理子程。當與指定的Hook類型關聯的消息發生時,系統就把這個消息傳遞到Hook子程。一些Hook子程可以只監視消息,或者修改消息,或者停止消息的前進,避免這些消息傳遞到下一個Hook子程或者目的窗口。最近安裝的鉤子放在鏈的開始,而最早安裝的鉤子放在最后,也就是后加入的先獲得控制權。Windows 并不要求鉤子子程的卸載順序一定得和安裝順序相反。每當有一個鉤子被卸載,Windows 便釋放其占用的內存,并更新整個Hook鏈表。如果程序安裝了鉤子,但是在尚未卸載鉤子之前就結束了,那么系統會自動為它做卸載鉤子的操作。鉤子子程是一個應用程序定義的回調函數(CALLBACK Function),不能定義成某個類的成員函數,只能定義為普通的C函數。用以監視系統或某一特定類型的事件,這些事件可以是與某一特定線程關聯的,也可以是系統中所有線程的事件。鉤子子程必須按照以下的語法:
1 LRESULT CALLBACK HookProc
2 (
3 int nCode,
4 WPARAM wParam,
5 LPARAM lParam
6 );
HookProc是應用程序定義的名字。nCode參數是Hook代碼,Hook子程使用這個參數來確定任務。這個參數的值依賴于Hook類型,每一種Hook都有自己的Hook代碼特征字符集。wParam和lParam參數的值依賴于Hook代碼,但是它們的典型值是包含了關于發送或者接收消息的信息。2、鉤子的安裝與釋放:使用API函數SetWindowsHookEx()把一個應用程序定義的鉤子子程安裝到鉤子鏈表中。SetWindowsHookEx函數總是在Hook鏈的開頭安裝Hook子程。當指定類型的Hook監視的事件發生時,系統就調用與這個Hook關聯的Hook鏈的開頭的Hook子程。每一個Hook鏈中的Hook子程都決定是否把這個事件傳遞到下一個Hook子程。Hook子程傳遞事件到下一個Hook子程需要調用CallNextHookEx函數。
1 HHOOK SetWindowsHookEx(
2 int idHook, // 鉤子的類型,即它處理的消息類型
3 HOOKPROC lpfn, // 鉤子子程的地址指針。如果dwThreadId參數為0
4 // 或是一個由別的進程創建的線程的標識,
5 // lpfn必須指向DLL中的鉤子子程。
6 // 除此以外,lpfn可以指向當前進程的一段鉤子子程代碼。
7 // 鉤子函數的入口地址,當鉤子鉤到任何消息后便調用這個函數。
8 HINSTANCE hMod, // 應用程序實例的句柄。標識包含lpfn所指的子程的DLL。
10 // 如果dwThreadId 標識當前進程創建的一個線程,
11 // 而且子程代碼位于當前進程,hMod必須為NULL。
12 // 可以很簡單的設定其為本應用程序的實例句柄。
13 DWORD dwThreadId // 與安裝的鉤子子程相關聯的線程的標識符。
14 // 如果為0,鉤子子程與所有的線程關聯,即為全局鉤子。
15 );
函數成功則返回鉤子子程的句柄,失敗返回NULL。以上所說的鉤子子程與線程相關聯是指在一鉤子鏈表中發給該線程的消息同時發送給鉤子子程,且被鉤子子程先處理。在鉤子子程中調用得到控制權的鉤子函數在完成對消息的處理后,如果想要該消息繼續傳遞,那么它必須調用另外一個SDK中的API函數CallNextHookEx來傳遞它,以執行鉤子鏈表所指的下一個鉤子子程。這個函數成功時返回鉤子鏈中下一個鉤子過程的返回值,返回值的類型依賴于鉤子的類型。這個函數的原型如下:
1 LRESULT CallNextHookEx
2 (
3 HHOOK hhk;
4 int nCode;
5 WPARAM wParam;
6 LPARAM lParam;
7 );
hhk為當前鉤子的句柄,由SetWindowsHookEx()函數返回。NCode為傳給鉤子過程的事件代碼。wParam和lParam 分別是傳給鉤子子程的wParam值,其具體含義與鉤子類型有關。 鉤子函數也可以通過直接返回TRUE來丟棄該消息,并阻止該消息的傳遞。否則的話,其他安裝了鉤子的應用程序將不會接收到鉤子的通知而且還有可能產生不正確的結果。鉤子在使用完之后需要用UnHookWindowsHookEx()卸載,否則會造成麻煩。釋放鉤子比較簡單,UnHookWindowsHookEx()只有一個參數。函數原型如下:
1 UnHookWindowsHookEx
2 (
3 HHOOK hhk;
4 );
函數成功返回TRUE,否則返回FALSE。3、一些運行機制:在Win16環境中,DLL的全局數據對每個載入它的進程來說都是相同的;而在Win32環境中,情況卻發生了變化,DLL函數中的代碼所創建的任何對象(包括變量)都歸調用它的線程或進程所有。當進程在載入DLL時,操作系統自動把DLL地址映射到該進程的私有空間,也就是進程的虛擬地址空間,而且也復制該DLL的全局數據的一份拷貝到該進程空間。也就是說每個進程所擁有的相同的DLL的全局數據,它們的名稱相同,但其值卻并不一定是相同的,而且是互不干涉的。因此,在Win32環境下要想在多個進程中共享數據,就必須進行必要的設置。在訪問同一個Dll的各進程之間共享存儲器是通過存儲器映射文件技術實現的。也可以把這些需要共享的數據分離出來,放置在一個獨立的數據段里,并把該段的屬性設置為共享。必須給這些變量賦初值,否則編譯器會把沒有賦初始值的變量放在一個叫未被初始化的數據段中。#pragma data_seg預處理指令用于設置共享數據段。例如:
1 #pragma data_seg("SharedDataName")
2 HHOOK hHook=NULL;
3 #pragma data_seg()
在#pragma data_seg("SharedDataName")和#pragma data_seg()之間的所有變量 將被訪問該Dll的所有進程看到和共享。當進程隱式或顯式調用一個動態庫里的函數時,系統都要把這個動態庫映射到這個進程的虛擬地址空間里(以下簡稱"地址空間")。這使得DLL成為進程的一部分,以這個進程的身份執行,使用這個進程的堆棧。4、系統鉤子與線程鉤子:SetWindowsHookEx()函數的最后一個參數決定了此鉤子是系統鉤子還是線程鉤子。 線程勾子用于監視指定線程的事件消息。線程勾子一般在當前線程或者當前線程派生的線程內。 系統勾子監視系統中的所有線程的事件消息。因為系統勾子會影響系統中所有的應用程序,所以勾子函數必須放在獨立的動態鏈接庫(DLL) 中。系統自動將包含"鉤子回調函數"的DLL映射到受鉤子函數影響的所有進程的地址空間中,即將這個DLL注入了那些進程。幾點說明:(1)如果對于同一事件(如鼠標消息)既安裝了線程勾子又安裝了系統勾子,那么系統會自動先調用線程勾子,然后調用系統勾子。 (2)對同一事件消息可安裝多個勾子處理過程,這些勾子處理過程形成了勾子鏈。當前勾子處理結束后應把勾子信息傳遞給下一個勾子函數。 (3)勾子特別是系統勾子會消耗消息處理時間,降低系統性能。只有在必要的時候才安裝勾子,在使用完畢后要及時卸載。三、鉤子類型
每一種類型的Hook可以使應用程序能夠監視不同類型的系統消息處理機制。下面描述所有可以利用的Hook類型。1、WH_CALLWNDPROC和WH_CALLWNDPROCRET HooksWH_CALLWNDPROC和WH_CALLWNDPROCRET Hooks使你可以監視發送到窗口過程的消息。系統在消息發送到接收窗口過程之前WH_CALLWNDPROCHook子程,并且在窗口過程處理完消息之后調用WH_CALLWNDPROCRET Hook子程。WH_CALLWNDPROCRET Hook傳遞指針到CWPRETSTRUCT結構,再傳遞到Hook子程。CWPRETSTRUCT結構包含了來自處理消息的窗口過程的返回值,同樣也包括了與這個消息關聯的消息參數。2、WH_CBT Hook在以下事件之前,系統都會調用WH_CBT Hook子程,這些事件包括:1. 激活,建立,銷毀,最小化,最大化,移動,改變尺寸等窗口事件;2. 完成系統指令;3. 來自系統消息隊列中的移動鼠標,鍵盤事件;4. 設置輸入焦點事件;5. 同步系統消息隊列事件。 Hook子程的返回值確定系統是否允許或者防止這些操作中的一個。3、WH_DEBUG Hook在系統調用系統中與其他Hook關聯的Hook子程之前,系統會調用WH_DEBUG Hook子程。你可以使用這個Hook來決定是否允許系統調用與其他Hook關聯的Hook子程。4、WH_FOREGROUNDIDLE Hook當應用程序的前臺線程處于空閑狀態時,可以使用WH_FOREGROUNDIDLE Hook執行低優先級的任務。當應用程序的前臺線程大概要變成空閑狀態時,系統就會調用WH_FOREGROUNDIDLE Hook子程。5、WH_GETMESSAGE Hook應用程序使用WH_GETMESSAGE Hook來監視從GetMessage or PeekMessage函數返回的消息。你可以使用WH_GETMESSAGE Hook去監視鼠標和鍵盤輸入,以及其他發送到消息隊列中的消息。6、WH_JOURNALPLAYBACK HookWH_JOURNALPLAYBACK Hook使應用程序可以插入消息到系統消息隊列。可以使用這個Hook回放通過使用WH_JOURNALRECORD Hook記錄下來的連續的鼠標和鍵盤事件。只要WH_JOURNALPLAYBACK Hook已經安裝,正常的鼠標和鍵盤事件就是無效的。WH_JOURNALPLAYBACK Hook是全局Hook,它不能象線程特定Hook一樣使用。WH_JOURNALPLAYBACK Hook返回超時值,這個值告訴系統在處理來自回放Hook當前消息之前需要等待多長時間(毫秒)。這就使Hook可以控制實時事件的回放。WH_JOURNALPLAYBACK是system-wide local hooks,它們不會被注射到任何行程位址空間。7、WH_JOURNALRECORD HookWH_JOURNALRECORD Hook用來監視和記錄輸入事件。典型的,可以使用這個Hook記錄連續的鼠標和鍵盤事件,然后通過使用WH_JOURNALPLAYBACK Hook來回放。WH_JOURNALRECORD Hook是全局Hook,它不能象線程特定Hook一樣使用。WH_JOURNALRECORD是system-wide local hooks,它們不會被注射到任何行程位址空間。8、WH_KEYBOARD Hook在應用程序中,WH_KEYBOARD Hook用來監視WM_KEYDOWN and WM_KEYUP消息,這些消息通過GetMessage or PeekMessage function返回。可以使用這個Hook來監視輸入到消息隊列中的鍵盤消息。9、WH_KEYBOARD_LL HookWH_KEYBOARD_LL Hook監視輸入到線程消息隊列中的鍵盤消息。10、WH_MOUSE HookWH_MOUSE Hook監視從GetMessage 或者 PeekMessage 函數返回的鼠標消息。使用這個Hook監視輸入到消息隊列中的鼠標消息。11、WH_MOUSE_LL HookWH_MOUSE_LL Hook監視輸入到線程消息隊列中的鼠標消息。12、WH_MSGFILTER 和 WH_SYSMSGFILTER HooksWH_MSGFILTER 和 WH_SYSMSGFILTER Hooks使我們可以監視菜單,滾動條,消息框,對話框消息并且發現用戶使用ALT+TAB or ALT+ESC 組合鍵切換窗口。WH_MSGFILTER Hook只能監視傳遞到菜單,滾動條,消息框的消息,以及傳遞到通過安裝了Hook子程的應用程序建立的對話框的消息。WH_SYSMSGFILTER Hook監視所有應用程序消息。 WH_MSGFILTER 和 WH_SYSMSGFILTER Hooks使我們可以在模式循環期間過濾消息,這等價于在主消息循環中過濾消息。 通過調用CallMsgFilter function可以直接的調用WH_MSGFILTER Hook。通過使用這個函數,應用程序能夠在模式循環期間使用相同的代碼去過濾消息,如同在主消息循環里一樣。13、WH_SHELL Hook外殼應用程序可以使用WH_SHELL Hook去接收重要的通知。當外殼應用程序是激活的并且當頂層窗口建立或者銷毀時,系統調用WH_SHELL Hook子程。WH_SHELL 共有5鐘情況:1. 只要有個top-level、unowned 窗口被產生、起作用、或是被摧毀;2. 當Taskbar需要重畫某個按鈕;3. 當系統需要顯示關于Taskbar的一個程序的最小化形式;4. 當目前的鍵盤布局狀態改變;5. 當使用者按Ctrl+Esc去執行Task Manager(或相同級別的程序)。 按照慣例,外殼應用程序都不接收WH_SHELL消息。所以,在應用程序能夠接收WH_SHELL消息之前,應用程序必須調用SystemParametersInfo function注冊它自己。以上轉自:http://www.microsoft.com/china/community/program/originalarticles/techdoc/hook.mspx以下轉自:http://topic.csdn.net/t/20030513/03/1774836.htmlCallNextHookEx 作用Hook 串鏈(Hook Chains) 當許多程式都安裝了某種型態的hook 時,就會形成一個filter-function chain。一旦特定 的event 發生,Windows 會呼叫該型態中最新掛上的hook filter function。舉個例,如果 程式A 掛上了一個system-wide WH_KEYBOARD hook,每當有任何執行緒取得鍵盤訊 息,Windows 就會呼叫這個filter function。如果程式B 也掛上了一個system-wide WH_KEYBOARD hook,那麼當event 發生,Windows 不再呼叫程式A 的filter function, 改呼叫程式B的filter function。這也意味每一個filter function 有責任確保先前掛上的filter Windows 95 程式設計指南(Windows 95 : A Developer’s Guide) 394 function 被呼叫(也就是維護串鏈的完整性)。 SetWindowsHookEx 函式會將新掛上的hook filter function 的代碼傳回。任何程式只要掛 上一個新的filter function 就必須儲存這個代碼(通常存放在全域變數中): static HHOOK g_hhook = NULL; . . . g_hhook = SetWindowsHookEx(WH_KEYBOARD, Example_kybdHook, hinst, NULL); . . . 如果有錯誤發生,SetWindowsHookEx 函式會傳回NULL。 如果你希望hook chain 中的其它filter functions 也能夠執行,你可以在你的filter function 中呼叫CallNextHookEx 函式(或許你已經在先前的Example_KybdHook 函式片段中注意 到了) LRESULT CallNextHookEx(HHOOK hhook, int nCode, WPARAM wParam, LPARAM lParam); 這個函式會呼叫filter-function chain 的下一個filter function,並傳入相同的nCode、 wParam 和lParam。下一個filter function 結束之前,應該也遵循這個規則去呼叫 CallNextHookEx 函式,並再次將hook 代碼(通常那是被放在全域變數中)傳入。 CallNextHookEx 函式利用這個hook 代碼,走訪整個串鏈,決定哪一個filter function 是 下一個呼叫目標。如果CallNextHookEx 函式發現已經沒有下一個filter function 可以呼叫 (走到串鏈盡頭了),它會傳回0;否則它就傳回「下一個filter function 執行後的傳回值」。 你可能會在許多文件(包括SDK 文件)中發現一個有關CallNextHookEx 函式的過氣警告:「如 果nCode 小於0,則hook 函式應該不做任何處理,直接將它交給CallNextHookEx 函式,並傳回 CallNextHookEx 函式的回返值」。這並不是真的,而且自Windows 3.0 以來(那時還在使用舊版的 SetWindowsHook 函式)就已經不是真的了!撰寫程式時,你可以完全不理會這項警告。 第6章訊息攔截(Hooks) 395 有些時候你可能不希望呼叫其他的filter functions,這種情況下你只要不在你的filter function 中呼叫CallNextHookEx 函式即可。只要不將CallNextHookEx 函式放到你的filter function 中,你就不會呼叫其他的filter functions,而你也因此可以指定你自己的傳回值。 不幸的是,這裡埋伏著一個陷阱:另一個執行緒可能也為你安裝了一個hook,新的filter function 於是比你的filter function 更早被喚起,而它可能不呼叫你的filter function,完蛋 了!這個問題沒有一般性的解決方案,如果你先將自己的hook 卸除,然後再重新掛上, 那麼你的filter function 就成為最新的一個,會最先被呼叫。沒錯,但你不能夠保證其他 人不會依樣畫葫蘆。簡言之,hooks 是一個合作機制,沒有任何保障。
posted @
2012-11-05 11:27 王海光 閱讀(595) |
評論 (0) |
編輯 收藏