轉自:http://blog.csdn.net/fuyangchang/article/details/5637464
wiki地址http://en.wikipedia.org/wiki/Hamming_distance
在信息領域,兩個長度相等的字符串的海明距離是在相同位置上不同的字符的個數,也就是將一個字符串替換成另一個字符串需要的替換的次數。
例如:
- "toned" and "roses" is 3.
- 1011101 and 1001001 is 2.
- 2173896 and 2233796 is 3.
對于二進制來說,海明距離的結果相當于 a XOR b 結果中1的個數。
python代碼如下
def hamming_distance(s1, s2):
assert len(s1) == len(s2)
return sum(ch1 != ch2 for ch1, ch2 in zip(s1, s2))
print (hamming_distance("gdad","glas"))
結果是2
C語言代碼如下
unsigned hamdist(unsigned x, unsigned y)
{
unsigned dist = 0, val = x ^ y;
// Count the number of set bits
while(val)
{
++dist;
val &= val - 1;
}
return dist;
}
int main()
{
unsigned x="abcdcc";
unsigned y="abccdd";
unsigned z=hamdist(x,y);
printf("%d",z);
}
本文轉自:http://m.shnenglu.com/humanchao/archive/2012/12/26/196680.html
posted @
2013-01-07 16:37 王海光 閱讀(662) |
評論 (0) |
編輯 收藏
By unanao
<sunjianjiao@gmail.com>
一、什么是大小端問題
(From《Computer Systems,A Programer's Perspective》)在幾乎所有的機器上,多字節對象被存儲為連續的字節序列,對象的地址為所使用字節序列中最低字節地址。
小端:某些機器選擇在存儲器中按照從最低有效字節到最高有效字節的順序存儲對象,這種最低有效字節在最前面的表示方式被稱為小端法(little endian) 。這樣的存儲模式有點兒類似于把數據當作字符串順序處理:地址由小向大增加,而數據從高位往低位放;
大端:某些機器則按照從最高有效字節到最低有效字節的順序儲存,這種最高有效字節在最前面的方式被稱為大端法(big endian) 。這種存儲模式將地址的高低和數據位權有效地結合起來,高地址部分權值高,低地址部分權值低,和我們的邏輯方法一致。
舉個例子來說名大小端: 比如一個int x, 地址為0x100, 它的值為0x1234567. 則它所占據的0x100, 0x101, 0x102, 0x103地址組織如下圖:
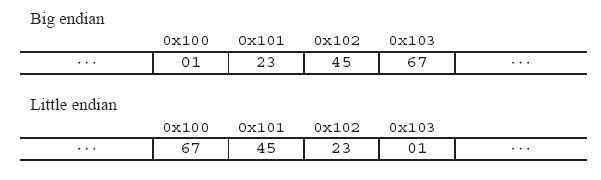
二、為什么會有大小端模式之分呢?
這是因為在計算機系統中,我們是以字節為單位的,每個地址單元都對應著一個字節,一個字節為 8bit。但是在C語言中除了8bit的char之外,還有16bit的short型,32bit的long型(要看具體的編譯器),另外,對于位數大于 8位的處理器,例如16位或者32位的處理器,由于寄存器寬度大于一個字節,那么必然存在著一個如果將多個字節安排的問題。因此就導致了大端存儲模式和小端存儲模式。例如一個16bit的short型x,在內存中的地址為0x0010,x的值為0x1122,那么0x11為高字節,0x22為低字節。對于 大端模式,就將0x11放在低地址中,即0x0010中,0x22放在高地址中,即0x0011中。小端模式,剛好相反。我們常用的X86結構是小端模式,而KEIL C51則為大端模式。很多的ARM,DSP都為小端模式。有些ARM處理器還可以由硬件來選擇是大端模式還是小端模式。
三、如何區分大小端問題:
方法1:
1 #include <stdio.h>
2
3 int main(void)
4 {
5 int i = 1;
6 unsigned char *pointer;
7
8 pointer = (unsigned char *)&i;
9 if(*pointer)
10 {
11 printf("litttle_endian");
12 }
13 else
14 {
15 printf("big endian\n");
16 }
17
18 return 0;
19 }
C中的數據類型都是從內存的低地址向高地址擴展,取址運算"&"都是取低地址。小端方式中(i占至少兩個字節的長度)則i所分配的內存最小地址那個字節中就存著1,其他字節是0。大端的話則1在i的最高地址字節處存放,char是一個字節,所以強制將char型量p指向i,則p指向的一定是i的最低地址,那么就可以判斷p中的值是不是1來確定是不是小端。
方法2:
1 #include <stdio.h>
2
3 int main(void)
4 {
5 union {
6 short a;
7 char ch;
8 } u;
9 u.a = 1;
10
11 if (u.ch == 1)
12 {
13 printf("Littel endian\n");
14 }
15 else
16 {
17 printf("Big endian\n");
18 }
19 }
利用聯合體的特點,數據成員共享內存空間,union中元素的起始地址都是相同的——位于聯合的開始。 用char來截取感興趣的字節。
四、需要考慮大小端(字節順序)的情況
1、所寫的程序需要向不同的硬件平臺遷移,說不定哪一個平臺是大端還是小端,為了保證可移植性,一定提前考慮好。
2. 在不同類型的機器之間通過網絡傳送二進制數據時。 一個常見的問題是當小端法機器產生的數據被發送到大端法機器或者反之時,接受程序會發現,字(word)里的字節(byte)成了反序的。為了避免這類問 題,網絡應用程序的代碼編寫必須遵守已建立的關于字節順序的規則,以確保發送方機器將它的內部表示轉換成網絡標準,而接受方機器則將網絡標準轉換為它的內部標準。
3. 當閱讀表示整數的字節序列時。這通常發生在檢查機器級程序時,e.g.:反匯編得到的一條指令:
80483bd: 01 05 64 94 04 08 add %eax, 0x8049464
3. 當編寫強轉的類型系統的程序時。如寫入的數據為u32型,但是讀取的時候卻是char型的。如:0x1234, 大端讀取為12時,小端獨到的是34。
六、提高程序的可移植性
使用宏編譯
#ifdef LITTLE_ENDIAN
//小端的代碼
#else
//大端的代碼
#endif
七、大、小端之間的轉換
1、小端轉換為大端
1 #include <stdio.h>
2
3 void show_byte(char *addr, int len)
4 {
5 int i;
6
7 for (i = 0; i < len; i++)
8 {
9 printf("%.2x \t", addr[i]);
10 }
11 printf("\n");
12 }
13
14 int endian_convert(int t)
15 {
16 int result;
17 int i;
18
19 result = 0;
20 for (i = 0; i < sizeof(t); i++)
21 {
22 result <<= 8;
23 result |= (t & 0xFF);
24 t >>= 8;
25 }
26
27 return result;
28 }
29
30 int main(void)
31 {
32 int i;
33 int ret;
34
35 i = 0x1234567;
36
37 show_byte((char *)&i, sizeof(int));
38 ret = endian_convert(i);
39 show_byte((char *)&ret, sizeof(int));
40
41 return 0;
42 }
本文轉自:http://m.shnenglu.com/humanchao/archive/2012/12/26/196684.html
posted @
2013-01-07 16:33 王海光 閱讀(820) |
評論 (0) |
編輯 收藏題目描述:
一個循環有序數組(如:3,4,5,6,7,8,9,0,1,2),不知道其最小值的位置,要查找任一數值的位置。要求算法時間復雜度為log2(n)。
問題分析:
我們可以把循環有序數組分為左右兩部分(以mid = (low+high)/ 2為界),由循環有序數組的特點知,左右兩部分必有一部分是有序的,我們可以找出有序的這部分,然后看所查找元素是否在有序部分,若在,則直接對有序部分二分查找,若不在,對無序部分遞歸調用查找函數。
代碼如下:
#include <iostream>
using namespace std;
int binarySearch(int a[],int low,int high,int value) //二分查找
{
if(low>high)
return -1;
int mid=(low+high)/2;
if(value==a[mid])
return mid;
else if(value>a[mid])
return binarySearch(a,mid+1,high,value);
else
return binarySearch(a,low,mid-1,value);
}
int Search(int a[],int low,int high,int value) //循環有序查找函數
{
int mid=(low+high)/2;
if(a[mid]>a[low]) //左有序
{
if(a[low]<=value && value<=a[mid] ) //說明value在左邊,直接二分查找
{
return binarySearch(a,low,mid,value);
}
else //value在右邊
{
return Search(a,mid+1,high,value);
}
}
else //右有序
{
if(a[mid]<=value && value<=a[high])
{
return binarySearch(a,mid,high,value);
}
else
{
return Search(a,low,mid-1,value);
}
}
}
int main()
{
int a[]={3,4,5,6,7,8,9,0,1,2};
cout<<Search(a,0,9,0)<<endl;
return 0;
}
本文轉自:http://m.shnenglu.com/humanchao/archive/2012/12/26/196686.html
posted @
2013-01-07 16:31 王海光 閱讀(493) |
評論 (0) |
編輯 收藏
本文轉自:http://m.shnenglu.com/humanchao/archive/2012/12/26/196690.html
posted @
2013-01-07 16:29 王海光 閱讀(1794) |
評論 (0) |
編輯 收藏C++
1、《高性能 Windows Socket 服務端與客戶端組件(源代碼及測試用例下載)》
《基于 IOCP 的通用異步 Windows Socket TCP 高性能服務端組件的設計與實現》
《通用異步 Windows Socket TCP 客戶端組件的設計與實現》
摘要:編寫 Windows Socket TCP 客戶端其實并不困難,Windows 提供了6種 I/O 通信模型供大家選擇。但本座看過很多客戶端程序都把 Socket 通信和業務邏輯混在一起,剪不斷理還亂。每個程序都 Copy / Parse 類似的代碼再進行修改,實在有點情何以堪。因此本座利用一些閑暇時光寫了一個基于 IOCP 的通用異步 Windows Socket TCP 高性能服務端組件和一個通用異步 Windows Socket TCP 客戶端組件供各位看官參詳參詳,希望能激發下大家的靈感。
資源下載地址:http://ldcsaa.googlecode.com/files/socket_server_and_client.zip
2、《Windows C++ 應用程序通用日志組件(組件及測試程序下載)》
摘要:編寫一個通用的日志組件應該著重考慮三個方面:功能、可用性和性能。下面,本座詳細說明在設計日志組件時對這些方面問題的考慮:
- 功能:本日志組件的目的是滿足大多數應用程序記錄日志的需求 —— 把日志輸出到文件或發送到應用程序中,并不提供一些復雜但不常用的功能
- 可用性:本日志組件著重考慮了可用性,盡量讓使用者用起來覺得簡便、舒心
- 性能:性能是組件是否值得使用的硬指標,本組件從設計到編碼的過程都盡量考慮到性能優化
資源下載地址:http://ldcsaa.googlecode.com/files/VC_Logger.zip
3、《如何養成良好的 C++ 編程習慣(一)—— 內存管理》
摘要:說起 C/C++ 的內存管理似乎令人望而生畏,滿屏的 new / delete / malloc / free,OutPut 窗口無盡的 Memory Leak 警告,程序詭異的 0X00000004 指針異常,仿佛回到那一年我們一起哭過的日子,你 Hold 得住嗎?其實,現實并沒有你想的那么糟糕。只要你付出一點點,花一點點心思,沒錯!就一點點而已 —— 用 C++ 類封裝內存訪問,就會解決你大部分的煩惱,讓你受益終身。以 Windows 程序為例,主要有以下幾種內存管理方式:
- 虛擬內存(Virtual Memory)
- 默認堆和私有堆(Process Heap & Private Heap)
- 內存映射文件(File Mapping)
- 進程堆棧(Heap,其實就是用 malloc() 或 默認的 new 操作符在 Process Heap 里一小塊一小塊地割肉 ^_^)
- 棧(Stack,內存由調用者或被調用者自動管理)
資源下載地址:http://ldcsaa.googlecode.com/files/socket_server_and_client.zip (源代碼在 Common/Src 目錄中)
4、《實現 Win32 程序的消息映射宏(類似 MFC )》
摘要:對于消息映射宏,不用多說了,用過 MFC 的人都很清楚。但目前有不少程序由于各種原因并沒有使用 MFC,所以本帖討論一下如何在 Win32 程序中實現類似MFC的消息映射宏。其實 Windows 的頭文件 “WindowsX.h”(注意:不是“Windows.h”) 中提供了一些有用的宏來幫助我們實現消息映射。本座是也基于這個頭文件實現消息映射。
資源下載地址:http://ldcsaa.googlecode.com/files/socket_server_and_client.zip (源代碼在 Common/Src/Win32Helper.h 文件中)
5、《用宏實現 C++ Singleton 模式》
摘要:Singleton 設計模式應用非常廣泛,實現起來也很簡單,無非是私有化若干個構造函數,“operator =” 操作符,以及提供一個靜態的創建和銷毀方法。但是對每個類都寫這些雷同的代碼是本座不能容忍的,因此,本座使用宏把整個 Singleton 模式封裝起來,無論是類的定義還是類的使用的極其簡單。
資源下載地址:http://ldcsaa.googlecode.com/files/socket_server_and_client.zip (源代碼在 Common/Src/Singleton.h 文件中)
6、《C++ 封裝私有堆(Private Heap)》
摘要:Private Heap 是 Windows 提供的一種內存內存機制,對于那些需要頻繁分配和釋放動態內存的應用程序來說,Private Heap 是提高應用程序性能的一大法寶,使用它能降低 new / malloc 的調用排隊競爭以及內存空洞。
資源下載地址:http://ldcsaa.googlecode.com/files/socket_server_and_client.zip (源代碼在 Common/Src/PrivateHeap.h 文件中)
7、《基于 crt debug 實現的 Windows 程序內存泄漏檢測工具》
摘要:Windows 程序內存泄漏檢測是一項十分重要的工作,基于 GUI 的應用程序通常在調試結束時也有內存泄漏報告,但這個報告的信息不全面,不能定位到產生泄漏的具體行號。其實自己實現一個內存泄漏檢測工具是一件非常簡單的事情,但看過網上寫的很多例子,普遍存在兩種問題:
- 要么考慮不周全,一種環境下能用,而在另外一種環境下卻不能很好工作,或者漏洞報告的輸出方式不合理。
- 要么過于保守,例如:完全沒有必要在 _malloc_dbg() 和 _free_dbg() 的調用前后用 CriticalSection 進行保護(跟蹤一下多線程環境下 new 和 malloc 的代碼就會明白)。
資源下載地址:http://ldcsaa.googlecode.com/files/socket_server_and_client.zip (源代碼在 Common/Src/debug/win32_crtdbg.h 文件中)
Java
1、《Portal-Basic Java Web 應用開發框架 v3.0.1 正式發布(源碼、示例及文檔)》
摘要:Portal-Basic Java Web應用開發框架(簡稱 Portal-Basic)是一套功能完備的高性能Full-Stack Web應用開發框架,內置穩定高效的MVC基礎架構和DAO框架(已內置Hibernate、MyBatis和JDBC支持),集成 Action攔截、Form Bean / Dao Bean / Spring Bean裝配、國際化、文件上傳下載和緩存等基礎Web應用組件,提供高度靈活的純 Jsp/Servlet API 編程模型,完美整合 Spring,支持Action Convention“零配置”,能快速開發傳統風格和RESTful風格的Web應用程序,文檔和代碼清晰完善,非常容易學習。
資源下載地址:http://code.google.com/p/portal-basic/downloads/list
2、《用 Java 實現的日志切割清理工具(源代碼下載)》
摘要:對于服務器的日常維護來說,日志清理是非常重要的事情,如果殘留日志過多則嚴重浪費磁盤空間同時影響服務的性能。如果用手工方式進行清理,會花費太多時間,并且很多時候難以滿足實際要求。例如:如何在每個星期六凌晨3點把超過2G大的日志文件進行切割,保留最新的100M日志記錄?網上沒有發現能滿足本座要求的日志切割工具,因此花了一些閑暇時間自己寫了一個。由于要在多個平臺上使用,為了方便采用 Java 實現。本工具命名為 LogCutter,主要有以下特點:
- 支持 Linux、Mac 和 Windows 等所有常見操作系統平臺
- 支持命令行交互式運行
- 支持后臺非交互式運行(Linux/MAC 下使用 daemon 進程實現,Windows 用系統 Service 實現)
- 支持兩種日志清理方式(刪除日志文件或切割日志文件)
- 支持對 GB18030、UTF-8、UTF-16LE、UTF-16BE 等常用日志文件類型進行切割(不會發生切掉半個字符的情況)
- 高度可配置(程序執行周期、要刪除的日志文件過期時間、要切割的日志文件閥值和保留大小等均可配置
資源下載地址:http://ldcsaa.googlecode.com/files/LogCutter.zip
3、《通用 Java 文件上傳和下載組件的設計與實現》
摘要:文件上傳和下載是 Web 應用中的一個常見功能,相信各位或多或少都曾寫過這方面相關的代碼。但本座看過不少人在實現上傳或下載功能時總是不知不覺間與程序的業務邏輯糾纏在一起,因此,當其他地方要用到這些功能時則無可避免地 Copy / Pase,然后再進行修改。這樣丑陋不堪的做法導致非常容易出錯不說,更大的問題是嚴重浪費時間不斷做重復類似的工作,這是本座絕不能容忍的。哎,人生苦短啊,浪費時間在這些重復工作身上實在是不值得,何不把這些時間省出來打幾盤羅馬或者踢一場球?為此,本座利用一些閑暇之時光編寫了一個通用的文件上傳和文件下載組件,實現方法純粹是基于 JSP,沒有太高的技術難度,總之老少咸宜 ^_^。現把設計的思路和實現的方法向各位娓娓道來,希望能起到拋磚引玉的效果,激發大家的創造性思維。
資源下載地址:http://code.google.com/p/portal-basic/downloads/list (作為 Portal-Basic 第一部分,代碼在 com.bruce.util.http 包中)
4、《深度剖析:Java POJO Bean 對象與 Web Form 表單的自動裝配》
摘要:時下很多 Web 框架 都實現了 Form 表單域與 Java 對象屬性的自動裝配功能,該功能確實非常有用,試想如果沒這功能則勢必到處沖積著 request.getParameter() 系列方法與類型轉換方法的調用。重復代碼量大,容易出錯,同時又不美觀,影響市容。現在的問題是,這些框架通過什么方法實現自動裝配的?如果不用這些框架我們自己如何去實現呢?尤其對于那些純 JSP/Servlet 應用,要是擁有自動裝配功能該多好啊!本座深知各位之期盼,決定把自動裝配的原理和實現方法娓娓道來。
資源下載地址:http://code.google.com/p/portal-basic/downloads/list (作為 Portal-Basic 第一部分,代碼在 com.bruce.util 包中)
5、《Linux 安裝 MySQL / MySQL 主從備份》
資源下載地址:http://ldcsaa.googlecode.com/files/services.zip
本文轉自:http://m.shnenglu.com/ldcsaa/archive/2013/01/07/197048.html
posted @
2013-01-07 10:39 王海光 閱讀(390) |
評論 (0) |
編輯 收藏
NSIS插件下載
posted @
2013-01-06 14:33 王海光 閱讀(715) |
評論 (0) |
編輯 收藏淘寶地址:http://item.taobao.com/item.htm?id=15567575512
posted @
2013-01-06 10:22 王海光 閱讀(372) |
評論 (0) |
編輯 收藏posted @
2013-01-05 15:06 王海光 閱讀(364) |
評論 (0) |
編輯 收藏posted @
2012-12-27 15:23 王海光 閱讀(3270) |
評論 (1) |
編輯 收藏
編譯步驟如下:
打開終端,輸入以下命令進行預處理。 qmake -project qmake TestGUI.pro make 然后終端會跳出一大串信息,編譯成功 接著運行./TestGUI
posted @
2012-12-05 17:26 王海光 閱讀(620) |
評論 (0) |
編輯 收藏