最新版本地址:/Files/saha/CCS0.5.rar
參考資料:http://www.sluijten.com/winglet/ http://www.frayn.net/beowulf/theory.html
Monday, April 16, 2012 總體框架設計
分離UI和AI算法,以利于以后不同平臺的移植。其中AI算法部分做到平臺無關性。
基本框架如下:

Thursday, April 19, 2012簡單的UI及棋子移動實現
設置棋盤為16*16的數組。冗余部分便于棋子出界判斷。
紅棋值從8-14,黑棋值從16-22.其余部分全部為0

基本UI實現,基本象棋類實現。
Tuesday, April 24, 2012實現棋子規則
1. 實現各個棋子的走法規則,將照面規則暫時未實現。
2. 實現了將軍判斷函數
3. 支持了翻轉功能
4. 實現一些細節。結束后不允許再走棋,重新初始化棋盤等。
Thursday, April 26, 2012
重新實現棋子走法規則判斷邏輯如下:

Friday, May 11, 2012
1.基本的人工智能算法 Alpha-Beta搜索.
其中
Alpha為搜索到的最好值,beta為對方的最壞值。一般起始時設置Alpha為負無窮,beta為正無窮。
之所以在遞歸內部要傳入-beta和-alpha是為了反應對方走棋,及簡化代碼。即表示我方的最好值與對方的最壞值的對應關系。
int AlphaBeta(int depth, int alpha, int beta)
{
if (depth == 0)
{
return Evaluate(); //如果是第一層返回局面估計
}
GenerateLegalMoves(); //產生當前的所有下一步走法
while (MovesLeft()) //排序并遍歷每一步走法
{
MakeNextMove(); //走一步
//遞歸搜索
val = -AlphaBeta(depth - 1, -beta, -alpha);
UnmakeMove(); //回退該步
//如果比最壞情況還壞,則返回最壞情況
if (val >= beta)
{
return beta;
}
//如果比最好情況差,則保持它為目前探索到的最好情況
if (val > alpha)
{
alpha = val;
}
}
return alpha; //返回目前找到的最好情況,其對應的走法即是搜索到的最好著法
}
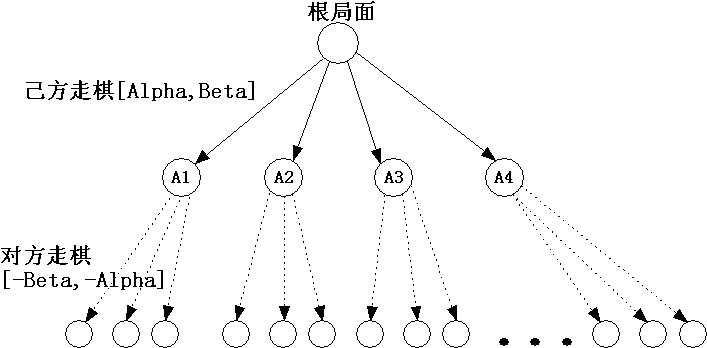
從根局面開始,默認的Alpha和Beta值分別為己方被殺和對方被殺的分值,遞歸搜索己方所有走法。
當一個走法返回的估計值A1>=Beta時,認為該節點是殺棋,則己方必選擇該走法,因此其余節點不用再搜索,只要保存該走法并返回,稱為beta截斷。
當一個走法A1<=Alpha時,認為該節點比己方所能接受的最差結果更差,因此不保留該走法(這里無法做截斷)。
當一個走法A1>Alpha && A1<Beta時,認為該節點是主變例節點(PV Principal Variation),需要保留該走法,并將Alpha設為A1,并繼續探索剩余節點。
對于對方走棋時,只要將上下限取反調用同一alpha-beta函數即可。
2.增加自動測試功能,能電腦vs電腦測試
3.增加不同的電腦級別,以搜索層數劃分
Wednesday, May 12, 2012
1.增加聲音開關功能
2.悔棋功能,最多支持悔512步
V0.2版本完成
Wednesday, May 30, 2012
1.空著向前裁剪
空著裁剪的含義就是如果當前的局勢優勢巨大,即使不走這一步棋讓對方走還是能產生beta截斷,相當于少搜索了一層,能大大縮短搜索的時間。
存在的一個問題是在殘局階段,當存在無棋可走的情況下,使用空著恰恰避開了這種問題,從而導致估計不準確,因此在殘局時需要進行判斷來決定是否使用空著裁剪,一種流行的簡單做法是到了殘局就不進行空著裁剪。
2.靜態搜索
相對穩定的局面稱為“安靜”(Quiet)或“寂靜”(Quiescent)的局面,它們需要通過“靜態搜索”(Quiescence Search)來達到。
目前采用簡單的策略即只考慮所有的吃子走法來進行搜索。
3.局面檢驗Zobrist鍵值
Zobrist用一個整型數值來代表一個棋的局面,目前采用的做法是對于每一個棋盤位置的14種情況(7種紅棋,7種黑棋)產生14*256個隨機數,每一個棋局是所有存在棋子的棋盤位置的隨機數異或而得到的一個整型值(稱為Zobrist鍵值),據前人經驗這種表示方法出現沖突的概率非常小。這種表示方法的另一個好處是去除一個棋子和添加一個棋子都是異或操作(由于異或的異或得到原來的值),利用Zobrist鍵值可以做重復局面判斷,長將判斷。
V0.3版本完成
Thursday, June 14, 2012
1.修改Zobrist鍵值從原來的32位無符號變為int64(據前人經驗32位存在沖突有很多爭論,而64位雖然仍存在沖突的局面,但是實戰中這種情況非常罕見)。
2.修改重復局面檢查函數,從以前的把所有歷史局面全部檢查到現在的只檢查最近6步,以減少不必要的檢查。
3.增加主變例搜索優化。即對當前搜索存在PV走法時,對以后的每一個節點搜索的搜索上下限先設為[-Alpha-1, -Alpha],如果當前節點的值比pv值要大則重新對該節點進行正常搜索,否則丟棄該節點進行下一個節點的搜索。據統計可以提供10%的搜索效率,在程序中直接使用沒有明顯的變化。。。
4.增加置換表。
基本思想:每一個搜索過的局面都記錄他的平均值,以避免以后搜索到同一局面時的重復計算工作。
使用zobrist-hash值記錄每個搜索過的局面。一個置換表的元素包括以下結構:
CCSINT64 ulZobristKey; //hash-key
CCSUINT32 depth : 8; //搜索深度
CCSUINT32 flags : 2; //標志,分為PV,BETA,ALPHA3種
CCSUINT32 mvBest : 22; //該局面下的最佳走法
CCSINT32 nValue; //該局面下的估計值
其中flags3種標志代表不同含義。
pv表示主變例搜索的結果,即這時的nValue是個精確值,可以直接使用
BETA表示該局面的估計值至少為nValue。
ALPHA表示該局面的估計值最多為nValue。
在alpha-beta搜索中的使用如下:
if (HASH_PV == pItem->flags)
{
return nValue;
}
if (HASH_BETA == pItem->flags && nValue >= nBeta)
{
return nBeta;
}
else if (HASH_ALPHA == pItem->flags && nValue <= nAlpha)
{
return nAlpha;
}
return VALUEUNKNOWN;
是否正確還有待測試。
使用置換表時除了判斷zobrist-hash值是否相同外,還要判斷當前走棋方是否與記錄中的走棋方一致,不一致不能替換.
Friday, July 27, 2012
修改置換表的使用方式
去除輸棋后的不文明用語
在騰訊游戲中進行測試,使用中等水平在1000分以下玩家中勝率95%+
posted on 2012-04-16 17:44
saha 閱讀(826)
評論(0) 編輯 收藏 引用 所屬分類:
棋類AI