【新智元導讀】 萊斯大學兩位研究員使用一種基于 Hashing 的新技術,大幅減少了訓練和測試神經網絡所需的計算量。他們稱:“1000 個神經元的網絡我們能節能 95%,根據數學推導,10 億個神經元的網絡我們就能節能 99%”。phys.org報道稱,這對谷歌、微軟和Facebook等有著大量深度學習神經網絡訓練的大公司來說事關重大。

美國萊斯大學(Rice University )的計算機科學家通過使用被廣泛使用的快速數據查找技術,以大幅度減少深度學習所必需的計算量,進而大大地節約了能源和時間。
萊斯大學計算機科學家已經采用了廣泛使用的快速數據查找技術,以減少計算量,從而減少了深度學習所需的能量和時間,這是一種計算強大的機器學習形式。
“這能運用到任何一種深度學習架構中,并且,其技巧是亞線性擴展的,也就是說,運用的神經網絡越大,能節省的計算資源就會越多”,萊斯大學計算機科學系助理教授、該研究的第一作者 Anshumali Shrivastava 介紹說。
研究將會出現在2017年的 KDD 會議上,會議將于8月在Nova Scotia的Halifax 舉辦。這一研究解決了谷歌、Facebook 和 微軟等這些爭先恐后地希望搭建、訓練和部署大規模的深度神經網絡的科技巨頭最緊迫的需求之一。它們希望用深度學習來滿足越來越多的產品需求,如自動駕駛汽車,語言翻譯和智能回復電子郵件等。
Shrivastava和 Rice 大學的研究生 Ryan Spring 證明,“哈希”(Hashing)技術是一種真實的數據索引方法,可以大大減少深度學習的計算消耗。“哈希” 涉及使用智能散列函數將數據轉換為可管理的小數,稱為哈希。哈希被存儲在表格中,其運行方式就好像紙質書中的索引。
“我們的方法混合了兩種技術:一個局部敏感哈希 clever 變量,以及一個稀疏的反向傳播。這樣就能在不大量地降低準確率的情況下,減少必要的計算消耗。Spring 說,“比如,在小規模的測試中,我們發現在標準方法下,能在準確率損失控制在1%的情況下,將計算能耗減少95%。”
深度學習網絡的基礎建造模塊是一個人造神經元。雖然1950年代,生物神經元的首先被發現,但是,人造神經元只是一個數學函數和等式,建立在大量的數據之上,可以轉化為輸出。
在機器學習中,所有的神經元都從一張白紙的“空”狀態開始,在訓練過程中變得特異化(specialized)。在訓練期間,網絡被“給予”大量數據,每個神經元都成為識別數據中特定模式的專家。在最低層,神經元執行最簡單的任務。例如,在照片識別應用中,低級神經元可能識別來自暗處的光線或物體的邊緣。這些神經元的輸出被傳遞到網絡下一層的神經元中,這些神經元又會以其特有的方式搜索它們會識別的特征。
只有幾層的神經網絡就可以學習識別人臉、各種犬類、停車標志和校車。
Shrivastava 說:“向網絡的每層增加更多的神經元可以增強其表現力(expressive power),而且我們想要網絡有多大這一點沒有上限。”
據報道,谷歌正在嘗試訓練一個擁有 1370 億個神經元的網絡。相比之下,訓練和部署這樣的網絡需要的計算力是有限的。
Shrivastava 說,目前使用的大多數機器學習算法都是 30 到 50 年前開發的,在設計的時候沒有考慮到計算的復雜性。但是,有了大數據之后,對于計算周期、能源和內存等資源來說,就存在著基本的限制,而“我們的實驗室側重于解決這些限制。”
Spring 表示,在大規模深度網絡中,hashing 帶來的計算和節能將會更大。
Spring 說,由于他們利用大數據中固有的稀疏性,因此能量的節省會隨著網絡規模的增加而增加。“假設一個深度網絡有 10 億個神經元,對于任何一個給定輸入——例如一張狗的圖片——只有少部分神經元會被激活。
在數據科學的術語中,這就叫做稀疏性(sparsity),而正因為有了稀疏性,他們的方法節省的能量會隨著網絡規模的擴大而增加。
“所以,1000 個神經元的網絡我們能節能 95%,根據數學推導,10 億個神經元的網絡我們就能節能 99%。”
原文:https://phys.org/news/2017-06-scientists-slash-deep.html#jCp

Ryan Spring (左) 和 Anshumali Shrivastava.
這篇論文《通過隨機哈希實現可擴展、可持續的深度學習》(Scalable and Sustainable Deep Learning via Randomized Hashing),已經作為 Oral 被 KDD 2017 接收。
雖然論文的同行評議版本要到 KDD 召開時才能得知,通過網上的資料,我們可以看到去年底 Spring 在 arXiv 上傳的論文預印版(地址:https://arxiv.org/pdf/1602.08194.pdf)。
下面是論文的摘要。

為了從復雜的數據集中學習,當前深度學習框架越來越大。這些框架需要進行巨大的矩陣乘法運算來訓練數百萬個參數。與此相反,另一個呈增長的趨勢是將深度學習帶入低功耗、嵌入式設備。為了訓練和測試深度網絡而進行的相關矩陣運算,從計算和能量消耗的角度看是非常昂貴的。我們提出了一種基于 Hashing 的新技術,大幅減少了訓練和測試神經網絡所需的計算量。我們的方法結合了最近提出的兩大概念,即自適應 dropout 和最大內部搜索(MIPS)隨機 Hashing,有效選擇網絡中具有最高激活的節點。
這一新深度學習算法通過在(數量明顯更少的)稀疏節點上運行,減少前向和后向傳播步驟的總體計算成本。因此,我們的算法在保持原始模型平均精度 1% 的同時,僅使用總乘法的 5%。
論文提出的基于 Hashing 的反向傳播算法,一個獨特屬性是 update 總是稀疏的。而由于稀疏梯度 update,我們的算法非常適合異構和并行訓練。通過在幾個真實數據集上進行嚴格的實驗評估,我們證明了提出的算法具有可擴展性和可持續性(能量效率高)。
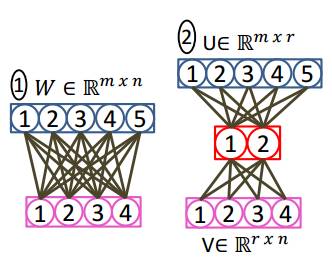
圖1:從圖中可見,神經網絡 Low-Rank 假設需要的參數數量自然會更少
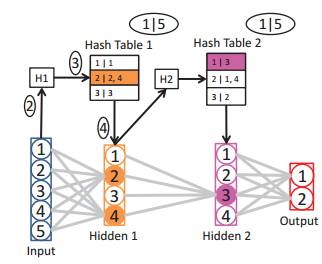
圖2:對神經網絡進行隨機哈希的視覺展示。① 建一個哈希表,方法是對每個隱藏層(一次迭代)的權重做哈希。② 使用該層的隨機哈希函數對該層的輸入做哈希。③ 查詢這一層的哈希表,獲取激活數據集 AS。④ 僅在激活神經元上做前向和后向傳播。⑤ 更新 AS 權重和哈希表。
56 核的英特爾 Xeon ES-2697 處理器上的性能比較
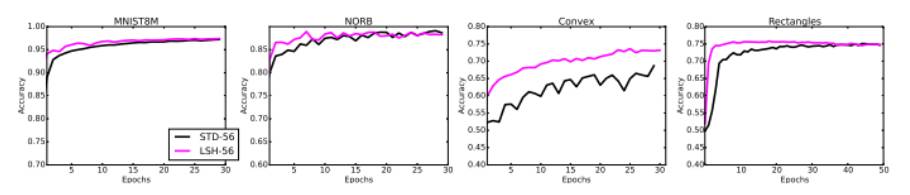
圖7:一個標準網絡使用我們的方法(隨機哈希)和使用異構隨機梯度下降,在 56 核的英特爾 Xeon ES-2697 處理器上的性能比較。我們依次在 MNIST、NORB、Convex 和 Rectangles 數據集上進行了測試。所有網絡的初始值都是一樣的。
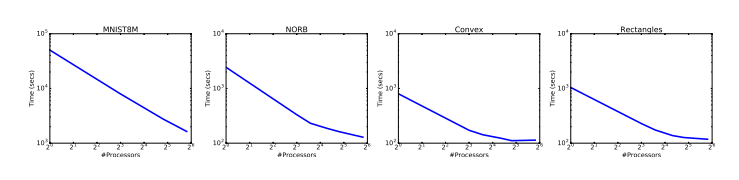
圖8:新方法(LSH-5%)使用異構隨機梯度下降每步(per epoch)獲得的掛鐘時間。我們用一個有 3 層隱藏層的網絡,依次在 MNIST、NORB、Convex 和 Rectangles 數據集上進行了測試。Convex 和 Rectangles 數據集上增量較少,是因為在整個過程中可用的訓練樣本不夠多。實驗中只使用了 5% 的標準網絡計算量。
更多內容,請見論文預印版(地址:https://arxiv.org/pdf/1602.08194.pdf)