繼續未完成的內容,聲明
本文僅用于學習研究,不提供解壓工具和實際代碼。
由于時間倉促,劍3資源格式分析(僅用于學習和技術研究)(一)
大部分只是貼出了分析的結果,并沒有詳細的分析過程,比如:如何知道那是一個pak文件處理對象,
如何根據虛表偏移獲取實際函數地址等等,這就需要讀者對c++對象在內存中的layout有一定基礎。
開始正文了~~,先整理下前面的分析結果:
1、劍3是通過package.ini 來管理pak文件的,最多可配置key從 0-32(0x20)的32個文件。
2、每個pak文件都用一個獨立對象來管理,所有的pak對象指針存儲在一個數組里(這個后面會用到)。
3、pak文件格式:[pak標記(Uint32)] + [文件數目(Uint32)]+[索引數據偏移(Uint32)]+未知內容。另外,每個文件的索引數據是16個字節。
一、路徑名哈希
劍3的pak的內部文件是通過hash值來查找的,這樣有利于加快查詢速度。這就需要有一個函數通過傳入 路徑名返回hash值。
這個函數居然是導出的。。。g_FileNameHash
這個函數代碼比較少,可以逆向出來用C重寫,也可以直接使用引擎函數(LoadLibrary,GetProceAddress來使用)。
熟悉劍俠系列的朋友會發現,這個函數從新劍俠情緣(可能歷史更久)開始就沒有變過(確實沒必要變),具體細節就不逐個分析了,我是寫了一個單獨的命令行工具
來測試的。
二、查詢過程
查詢函數在sub_10010E00
里,也就是(0x10010E00)的位置,我是通過簡單分析g_IsFileExist 得知這個函數功能的。下面
來分析這個函數過程:
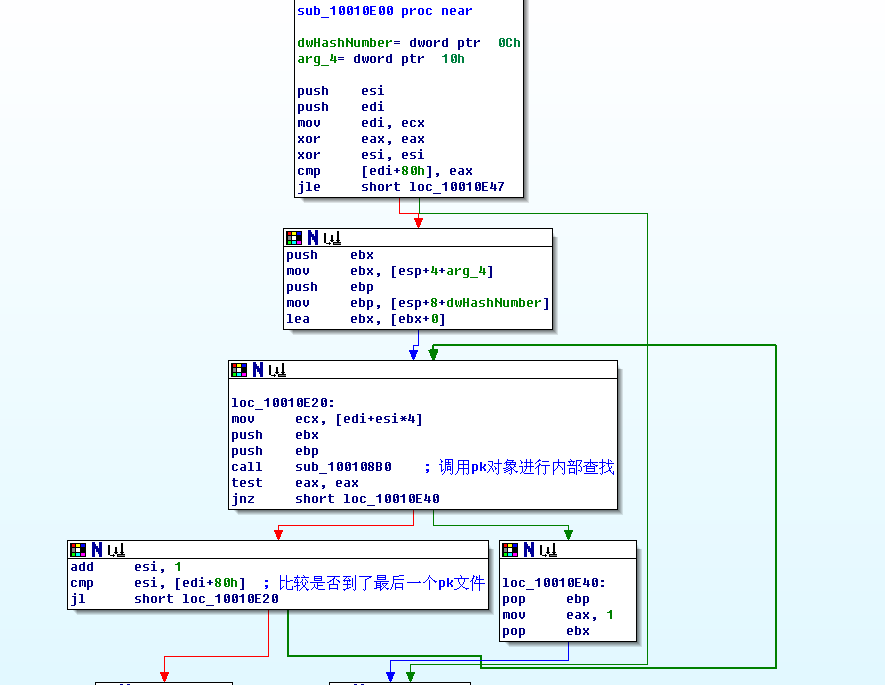
從前文可知,pak文件對象是存儲在一個數組的這個數組是類似 KPakFile* m_szPakFile[0x21];
前面0x20個存儲的都是KPakFile對象指針,最后一個存儲的是數組長度。
這個搜索結構比較簡單,就是遍歷所有的KPakFile對象,逐個查詢,找到了就返回。想知道具體怎么查詢的嗎,
接下來要看sub_100108B0了。
這個函數稍微有點長,分幾個部分來分析吧:
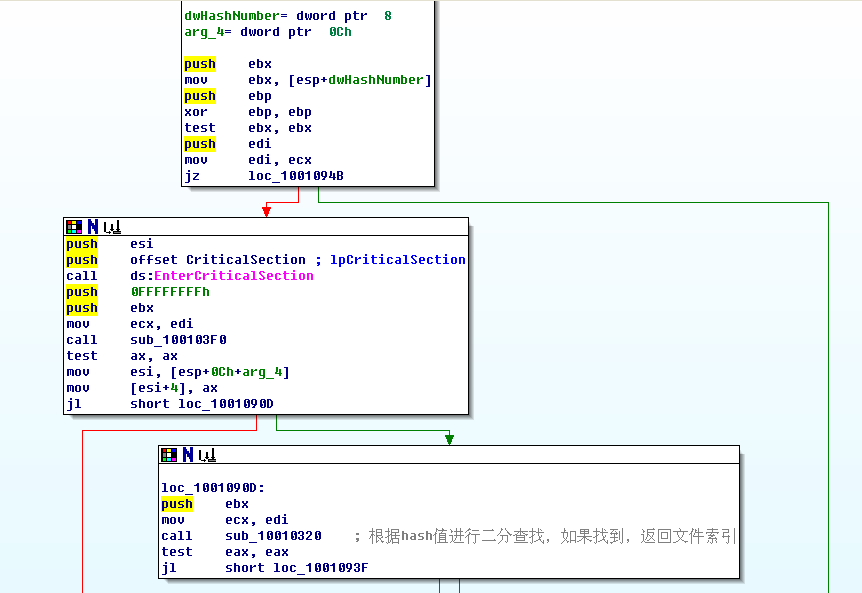
首先,驗證下Hash值是否是0,如果是0,肯定是錯了:)
然后接著開始根據這個hash值進行查找了,經過分析,我發現這個函數其實是一個二分查找,代碼貼出來如下 sub_10010320
:

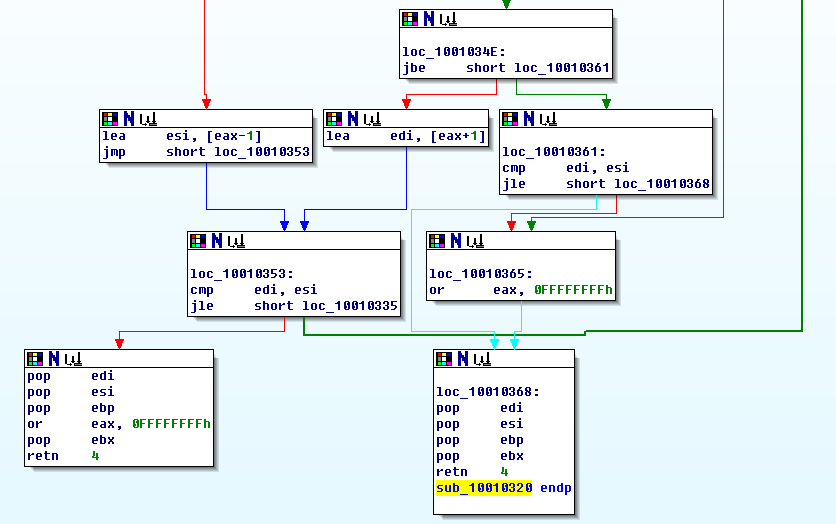
從上面的代碼還是比較容易可以知道,每個文件的16個索引數據中,前4個字節是hash值,這個函數返回的是這個文件是pak包的第幾個。
接著前面的sub_100108B0
來看吧
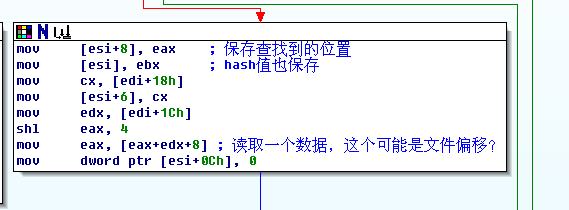
這一段是保存查詢到的數據到對象里。分析到這里,我只知道16個索引數據前4個字節是hash值,那么剩下的12個字節呢,
剩下的數據基本可以確定是:文件偏移、文件長度。我是個懶人,接下來的分析我是通過在fseek、fread下斷點來得到的,為什么不是在SetFilePointer和ReadFile呢,
這是根據前面的分析得到的,因為pak文件管理對象使用的是C標準庫函數。
根據fread和fseek的結果,可以得到如下結果:
索引數據構成是:
[哈希數值(Uint32)] + [文件偏移(Uint32)]+[未知數據(Uint32)] + 2(文件長度)+2(未知數據)。
剩下的,就是看看單獨內部文件的解壓方式了,
在fread的緩沖區上設置內存斷點,就可以找到解壓函數了:
sub_10018020
這個函數不算太長,一開始我也想逆向成C語言,后來看到如此多的分支就放棄了,轉而用了一個偷懶的辦法解決了:
從匯編代碼可知這個函數的原型:
typedef int (*PUNPACK_FUN)(void* psrcData, int nSrcLen, void* pDstData, int* pDstLen);
直接加載劍3的dll,設置函數地址:
PUNPACK_FUN pEngineUnpack = (PUNPACK_FUN)((unsigned int)hEngineModule + 0x18020);
hEngineModule
是引擎dll的基址,大家看到了吧,dll的函數即使不導出,我們也是可以調用的:)
三、尾聲
到這里,已經可以寫出一個pak文件的解壓包了,但是,我們還是沒有還原真實的文件名,
下面是我解壓的script.pak的文件的部分內容:

終于看到大俠們的簽名了。當然,對著一堆hash值為名字的文件,閱讀起來確實很困難,
那么有辦法還原真實的文件名嗎,辦法還是有一些的,可以通過各種辦法改寫g_OpenFileInPak記錄參數名,來獲取游戲中用到的pak內部文件名,相信這難不倒各位了。
posted @
2010-07-16 20:47 feixuwu 閱讀(4835) |
評論 (11) |
編輯 收藏
這幾天在玩劍三,突然興趣來了,想要分析劍3的資源打包格式。在資源分析和逆向方面原來偶爾也干過,
不過總體來說還是處于菜鳥階段,這篇文章希望和其他有興趣的兄弟分享下這幾天的經歷,僅僅作為技術研究。
一、安全保護
一般來說,很少有游戲的資源格式可以直接通過分析資源文件本身得到答案,大部分難免要靜態逆向、動態調試。
無論是靜態逆向還是動態調試,首先需要知道當前exe和dll的保護情況,用peid查看,發現只有gameupdater.exe 用upx加殼了。不太明白金山為什么對客戶端沒有加殼。
其實我并不關心gameupdater.exe 是否加殼,畢竟要動態分析的目標是JX3Client.exe
,要動態調試JX3Client.exe,首先要解決啟動參數問題。
二、啟動參數
如果直接啟動JX3Client.exe,JX3Client.exe會直接退出,并啟動gameuodater.exe,然后通過gameupdater.exe啟動JX3Client.exe。
這種啟動方式會影響動態調試,所以首先我需要找出JX3Client.exe的啟動參數。打開IDA逆向,轉到啟動處,匯編代碼如下:


start proc near
call ___security_init_cookie
jmp ___tmainCRTStartup
start endp
這是一個典型的VC程序入口,在___tmainCRTStartup
里,crt會初始化全局變量、靜態變量,然后進入main,我們需要做的是直接找到main,
跟進去,會發現IDA已經幫我們找到WinMain了,直接跟進去,
關鍵代碼在WinMain的入口處:
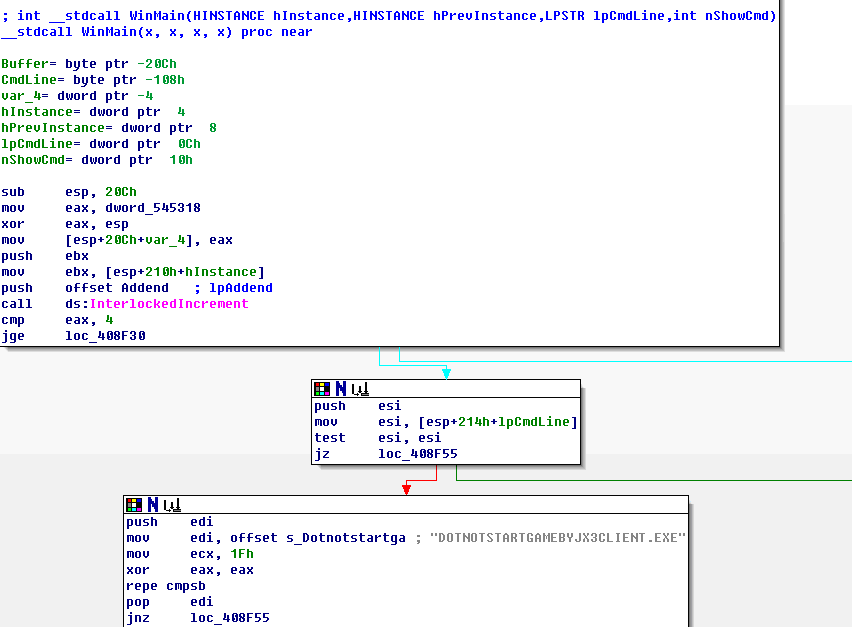
從這個代碼片段可以知道,WinMain開始就比較了命令行參數是否是"DOTNOTSTARTGAMEBYJX3CLIENT.EXE
",如果不是,
則轉到啟動更新程序了。這個好辦,我們寫一個run.bat,內容只有一行:
JX3Client.exe DOTNOTSTARTGAMEBYJX3CLIENT.EXE
運行,果然,直接看到加載界面了。
三、PAK文件管理
在劍3里,PAK目錄下有很多PAK文件,劍3是通過package.ini 來加載和管理pak內部文件的。
這個文件內容如下:
[SO3Client]
10=data_5.pak
1=ui.pak
0=update_1.pak
3=maps.pak
2=settings.pak
5=scripts.pak
4=represent.pak
7=data_2.pak
6=data_1.pak
9=data_4.pak
Path=.\pak
8=data_3.pak
基本上PAK目錄下所有的PAK文件都列出來了,其實劍3的資源文件打包方式基本上和新劍俠情緣類似(細節還是有比較大的差別)。
打開ollyDbg,帶參數啟動JX3Client.exe,在CreateFile設置斷點,可以發現,package.ini
的讀取和處理是在
Engine_Lua5.dll
的g_LoadPackageFiles
函數,熟悉新劍俠情緣資源管理方式的同學大概會猜到這個函數是做什么的,先看看函數內容吧,這個函數比較長
只能逐步的分析了,首先是打開ini文件

使用g_OpenIniFile打開前面提到的ini文件,如果打開失敗,自然直接返回了。
打開成功后,循環讀取ini配置的文件,讀取的section是SO3Client 讀取的key是0到0x20。
loc_1001119A: ; int
push 0Ah
lea ecx, [esp+1A0h+var_178]
push ecx ; char *
push ebx ; int
call ds:_itoa ; 這是根據數字生成key的代碼
mov edx, [ebp+0]
mov edx, [edx+24h]
add esp, 0Ch
push 40h
lea eax, [esp+1A0h+var_168]
push eax
mov eax, [esp+1A4h+var_184]
push offset unk_10035B8C
lea ecx, [esp+1A8h+var_178]
push ecx
push eax
mov ecx, ebp
call edx ; 讀取INI內容 readString(section, key)
test eax, eax
jz loc_1001127A
這段是通過readString("SO3Client", key)來獲取pak文件名, key就是"0"~"32"的字符串,也就是最多能配置32個Pak文件。
獲得了pak文件名后,下面就是打開和保存pak文件的索引數據了。

后面的注釋是我分析的時候加上的,IDA這個功能不錯!
首先new一個0x20字節的空間用來存儲pak對象(我自己命名的類),接著調用構造函數,創建pak對象。
創建對象后,要用這個Pak對象打開對應的pak文件了,這是我們下面的代碼:
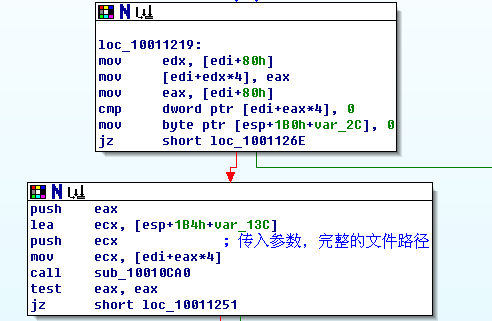
首先通過
mov [edi+edx*4], eax
將對象保存,然后,調用這個類的成員函數打開pak文件,具體代碼在sub_10010ca0。
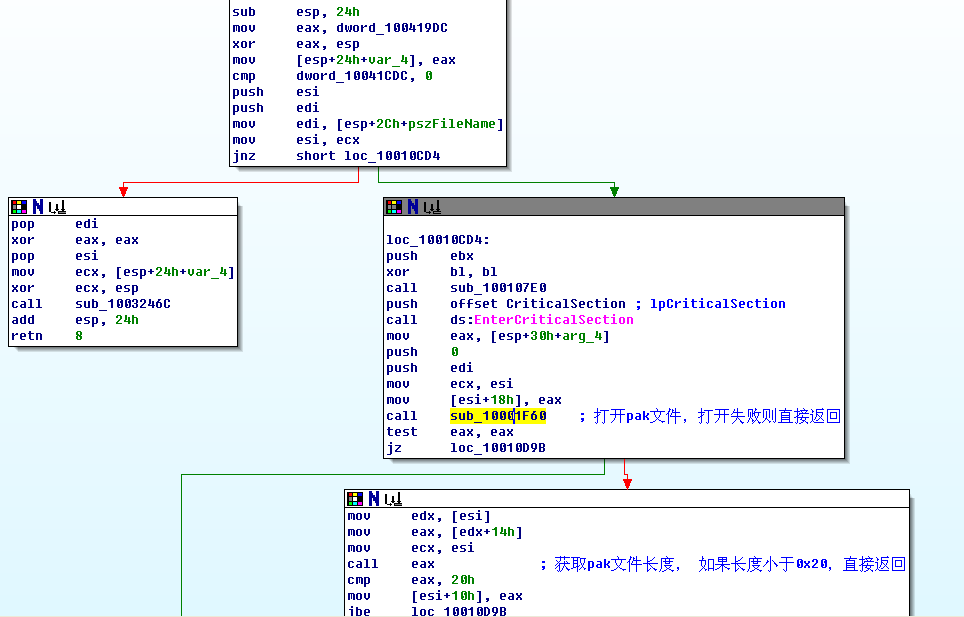
這段代碼的意思很明白了,打開文件,讀取0x20的文件頭,
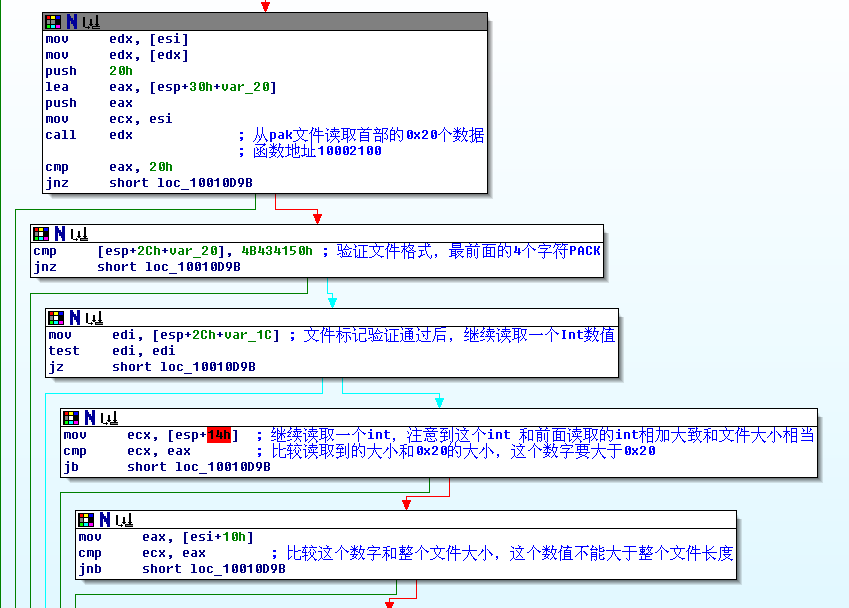
這里做的是驗證文件格式,和一些必要的驗證。

這段是讀取pak內部文件數目,讀取索引數據,以備后面查詢使用。
到此為止,所有pak文件的管理對象都已經加載和設置完畢了。
以上內容看起來很順理成章,但是實際上凝聚了無數的失敗和重試。
后面是pak內部文件的查找和讀取了。
剩下的內容明天貼了~~~
posted @
2010-07-15 21:07 feixuwu 閱讀(5286) |
評論 (10) |
編輯 收藏
最近有朋友在面試的時候被問了select 和epoll效率差的原因,和一般人一樣,大部分都會回答select是輪詢、epoll是觸發式的,所以效率高。這個答案聽上去很完美,大致也說出了二者的主要區別。
今天閑來無事,翻看了下內核代碼,結合內核代碼和大家分享下我的觀點。
一、連接數
我本人也曾經在項目中用過select和epoll,對于select,感觸最深的是linux下select最大數目限制(windows 下似乎沒有限制),每個進程的select最多能處理FD_SETSIZE個FD(文件句柄),
如果要處理超過1024個句柄,只能采用多進程了。
常見的使用slect的多進程模型是這樣的: 一個進程專門accept,成功后將fd通過unix socket傳遞給子進程處理,父進程可以根據子進程負載分派。曾經用過1個父進程+4個子進程 承載了超過4000個的負載。
這種模型在我們當時的業務運行的非常好。epoll在連接數方面沒有限制,當然可能需要用戶調用API重現設置進程的資源限制。
二、IO差別
1、select的實現
這段可以結合linux內核代碼描述了,我使用的是2.6.28,其他2.6的代碼應該差不多吧。
先看看select:
select系統調用的代碼在fs/Select.c下,
asmlinkage long sys_select(int n, fd_set __user *inp, fd_set __user *outp,
fd_set __user *exp, struct timeval __user *tvp)
{
struct timespec end_time, *to = NULL;
struct timeval tv;
int ret;
if (tvp) {
if (copy_from_user(&tv, tvp, sizeof(tv)))
return -EFAULT;
to = &end_time;
if (poll_select_set_timeout(to,
tv.tv_sec + (tv.tv_usec / USEC_PER_SEC),
(tv.tv_usec % USEC_PER_SEC) * NSEC_PER_USEC))
return -EINVAL;
}
ret = core_sys_select(n, inp, outp, exp, to);
ret = poll_select_copy_remaining(&end_time, tvp, 1, ret);
return ret;
}
前面是從用戶控件拷貝各個fd_set到內核空間,接下來的具體工作在core_sys_select中,
core_sys_select->do_select,真正的核心內容在do_select里:
int do_select(int n, fd_set_bits *fds, struct timespec *end_time)
{
ktime_t expire, *to = NULL;
struct poll_wqueues table;
poll_table *wait;
int retval, i, timed_out = 0;
unsigned long slack = 0;
rcu_read_lock();
retval = max_select_fd(n, fds);
rcu_read_unlock();
if (retval < 0)
return retval;
n = retval;
poll_initwait(&table);
wait = &table.pt;
if (end_time && !end_time->tv_sec && !end_time->tv_nsec) {
wait = NULL;
timed_out = 1;
}
if (end_time && !timed_out)
slack = estimate_accuracy(end_time);
retval = 0;
for (;;) {
unsigned long *rinp, *routp, *rexp, *inp, *outp, *exp;
set_current_state(TASK_INTERRUPTIBLE);
inp = fds->in; outp = fds->out; exp = fds->ex;
rinp = fds->res_in; routp = fds->res_out; rexp = fds->res_ex;
for (i = 0; i < n; ++rinp, ++routp, ++rexp) {
unsigned long in, out, ex, all_bits, bit = 1, mask, j;
unsigned long res_in = 0, res_out = 0, res_ex = 0;
const struct file_operations *f_op = NULL;
struct file *file = NULL;
in = *inp++; out = *outp++; ex = *exp++;
all_bits = in | out | ex;
if (all_bits == 0) {
i += __NFDBITS;
continue;
}
for (j = 0; j < __NFDBITS; ++j, ++i, bit <<= 1) {
int fput_needed;
if (i >= n)
break;
if (!(bit & all_bits))
continue;
file = fget_light(i, &fput_needed);
if (file) {
f_op = file->f_op;
mask = DEFAULT_POLLMASK;
if (f_op && f_op->poll)
mask = (*f_op->poll)(file, retval ? NULL : wait);
fput_light(file, fput_needed);
if ((mask & POLLIN_SET) && (in & bit)) {
res_in |= bit;
retval++;
}
if ((mask & POLLOUT_SET) && (out & bit)) {
res_out |= bit;
retval++;
}
if ((mask & POLLEX_SET) && (ex & bit)) {
res_ex |= bit;
retval++;
}
}
}
if (res_in)
*rinp = res_in;
if (res_out)
*routp = res_out;
if (res_ex)
*rexp = res_ex;
cond_resched();
}
wait = NULL;
if (retval || timed_out || signal_pending(current))
break;
if (table.error) {
retval = table.error;
break;
}
/*
* If this is the first loop and we have a timeout
* given, then we convert to ktime_t and set the to
* pointer to the expiry value.
*/
if (end_time && !to) {
expire = timespec_to_ktime(*end_time);
to = &expire;
}
if (!schedule_hrtimeout_range(to, slack, HRTIMER_MODE_ABS))
timed_out = 1;
}
__set_current_state(TASK_RUNNING);
poll_freewait(&table);
return retval;
}
上面的代碼很多,其實真正關鍵的代碼是這一句:
mask = (*f_op->poll)(file, retval ? NULL : wait);
這個是調用文件系統的 poll函數,不同的文件系統poll函數自然不同,由于我們這里關注的是tcp連接,而socketfs的注冊在 net/Socket.c里。
register_filesystem(&sock_fs_type);
socket文件系統的函數也是在net/Socket.c里:
static const struct file_operations socket_file_ops = {
.owner = THIS_MODULE,
.llseek = no_llseek,
.aio_read = sock_aio_read,
.aio_write = sock_aio_write,
.poll = sock_poll,
.unlocked_ioctl = sock_ioctl,
#ifdef CONFIG_COMPAT
.compat_ioctl = compat_sock_ioctl,
#endif
.mmap = sock_mmap,
.open = sock_no_open, /* special open code to disallow open via /proc */
.release = sock_close,
.fasync = sock_fasync,
.sendpage = sock_sendpage,
.splice_write = generic_splice_sendpage,
.splice_read = sock_splice_read,
};
從sock_poll跟隨下去,
最后可以到 net/ipv4/tcp.c的
unsigned int tcp_poll(struct file *file, struct socket *sock, poll_table *wait)
這個是最終的查詢函數,
也就是說select 的核心功能是調用tcp文件系統的poll函數,不停的查詢,如果沒有想要的數據,主動執行一次調度(防止一直占用cpu),直到有一個連接有想要的消息為止。
從這里可以看出select的執行方式基本就是不同的調用poll,直到有需要的消息為止,如果select 處理的socket很多,這其實對整個機器的性能也是一個消耗。
2、epoll的實現
epoll的實現代碼在 fs/EventPoll.c下,
由于epoll涉及到幾個系統調用,這里不逐個分析了,僅僅分析幾個關鍵點,
第一個關鍵點在
static int ep_insert(struct eventpoll *ep, struct epoll_event *event,
struct file *tfile, int fd)
這是在我們調用sys_epoll_ctl 添加一個被管理socket的時候調用的函數,關鍵的幾行如下:
epq.epi = epi;
init_poll_funcptr(&epq.pt, ep_ptable_queue_proc);
/*
* Attach the item to the poll hooks and get current event bits.
* We can safely use the file* here because its usage count has
* been increased by the caller of this function. Note that after
* this operation completes, the poll callback can start hitting
* the new item.
*/
revents = tfile->f_op->poll(tfile, &epq.pt);
這里也是調用文件系統的poll函數,不過這次初始化了一個結構,這個結構會帶有一個poll函數的callback函數:ep_ptable_queue_proc,
在調用poll函數的時候,會執行這個callback,這個callback的功能就是將當前進程添加到 socket的等待進程上。
static void ep_ptable_queue_proc(struct file *file, wait_queue_head_t *whead,
poll_table *pt)
{
struct epitem *epi = ep_item_from_epqueue(pt);
struct eppoll_entry *pwq;
if (epi->nwait >= 0 && (pwq = kmem_cache_alloc(pwq_cache, GFP_KERNEL))) {
init_waitqueue_func_entry(&pwq->wait, ep_poll_callback);
pwq->whead = whead;
pwq->base = epi;
add_wait_queue(whead, &pwq->wait);
list_add_tail(&pwq->llink, &epi->pwqlist);
epi->nwait++;
} else {
/* We have to signal that an error occurred */
epi->nwait = -1;
}
}
注意到參數 whead
實際上是 sk->sleep,其實就是將當前進程添加到sk的等待隊列里,當該socket收到數據或者其他事件觸發時,會調用
sock_def_readable
或者sock_def_write_space
通知函數來喚醒等待進程,這2個函數都是在socket創建的時候填充在sk結構里的。
從前面的分析來看,epoll確實是比select聰明的多、輕松的多,不用再苦哈哈的去輪詢了。
posted @
2010-07-10 18:40 feixuwu 閱讀(10291) |
評論 (3) |
編輯 收藏
昨天一個同事一大早在群里推薦了一個google project上的開源內存分配器(
http://code.google.com/p/google-perftools/),據說google的很多產品都用到了這個內存分配庫,而且經他測試,我們的游戲客戶端集成了這個最新內存分配器后,FPS足足提高了將近10幀左右,這可是個了不起的提升,要知道3D組的兄弟忙了幾周也沒見這么大的性能提升。
如果我們自己本身用的crt提供的內存分配器,這個提升也算不得什么。問題是我們內部系統是有一個小內存管理器的,一般來說小內存分配的算法都大同小異,現成的實現也很多,比如linux內核的slab、SGI STL的分配器、ogre自帶的內存分配器,我們自己的內存分配器也和前面列舉的實現差不多。讓我們來看看這個項目有什么特別的吧。
一、使用方法
打開主頁,由于公司網絡禁止SVN從外部更新,所以只能下載了打包的源代碼。解壓后,看到有個doc目錄,進去,打開使用文檔,發現使用方法極為簡單:
To use TCMalloc, just link TCMalloc into your application via the
"-ltcmalloc" linker flag.再看算法,也沒什么特別的,還是和slab以及SGI STL分配器類似的算法。
unix環境居然只要鏈接這個tcmalloc庫就可以了!,太方便了,不過我手頭沒有linux環境,文檔上也沒提到windows環境怎么使用,
打開源代碼包,有個vs2003解決方案,打開,隨便挑選一個測試項目,查看項目屬性,發現僅僅有2點不同:
1、鏈接器命令行里多了
"..\..\release\libtcmalloc_minimal.lib",就是鏈接的時候依賴了這個內存優化庫。
2、鏈接器->輸入->強制符號引用 多了 __tcmalloc。
這樣就可以正確的使用tcmalloc庫了,測試了下,測試項目運行OK!
二、如何替換CRT的malloc
從前面的描述可知,項目強制引用了__tcmalloc, 搜索了測試代碼,沒發現用到_tcmalloc相關的函數和變量,這個選項應該是為了防止dll被優化掉(因為代碼里沒有什么地方用到這個dll的符號)。
初看起來,鏈接這個庫后,不會影響任何現有代碼:我們沒有引用這個Lib庫的頭文件,也沒有使用過這個dll的導出函數。那么這個dll是怎么優化應用程序性能的呢?
實際調試,果然發現問題了,看看如下代碼
void* pData = malloc(100);
00401085 6A 64 push 64h
00401087 FF 15 A4 20 40 00 call dword ptr [__imp__malloc (4020A4h)]
跟蹤 call malloc這句,step進去,發現是
78134D09 E9 D2 37 ED 97 jmp `anonymous namespace'::LibcInfoWithPatchFunctions<8>::Perftools_malloc (100084E0h)
果然,從這里開始,就跳轉到libtcmalloc提供的Perftools_malloc了。
原來是通過API掛鉤來實現無縫替換系統自帶的malloc等crt函數的,而且還是通過大家公認的不推薦的改寫函數入口指令來實現的,一般只有在游戲外掛和金山詞霸之類的軟件才會用到這樣的掛鉤技術,
而且金山詞霸經常需要更新補丁解決不同系統兼容問題。
三、性能差別原因
如前面所述,tcmalloc確實用了很hacker的辦法來實現無縫的替換系統自帶的內存分配函數(本人在使用這類技術通常是用來干壞事的。。。),但是這也不足以解釋為什么它的效率比我們自己的好那么多。
回到tcmalloc 的手冊,tcmalloc除了使用常規的小內存管理外,對多線程環境做了特殊處理,這和我原來見到的內存分配器大有不同,一般的內存分配器作者都會偷懶,把多線程問題扔給使用者,大多是加
個bool型的模板參數來表示是否是多線程環境,還美其名曰:可定制,末了還得吹噓下模板的優越性。
tcmalloc是怎么做的呢? 答案是每線程一個ThreadCache,大部分操作系統都會支持thread local storage 就是傳說中的TLS,這樣就可以實現每線程一個分配器了,
這樣,不同線程分配都是在各自的threadCache里分配的。我們的項目的分配器由于是多線程環境的,所以不管三七二十一,全都加鎖了,性能自然就低了。
僅僅是如此,還是不足以將tcmalloc和ptmalloc2分個高下,后者也是每個線程都有threadCache的。
關于這個問題,doc里有一段說明,原文貼出來:
ptmalloc2 also reduces lock contention by using per-thread arenas but
there is a big problem with ptmalloc2's use of per-thread arenas. In
ptmalloc2 memory can never move from one arena to another. This can
lead to huge amounts of wasted space.
大意是這樣的:ptmalloc2 也是通過tls來降低線程鎖,但是ptmalloc2各個線程的內存是獨立的,也就是說,第一個線程申請的內存,釋放的時候還是必須放到第一個線程池中(不可移動),這樣可能導致大量內存浪費。
四、代碼細節
1、無縫替換malloc等crt和系統分配函數。
前面提到tcmalloc會無縫的替換掉原有dll中的malloc,這就意味著使用tcmalloc的項目必須是 MD(多線程dll)或者MDd(多線程dll調試)。tcmalloc的dll定義了一個
static TCMallocGuard module_enter_exit_hook;
的靜態變量,這個變量會在dll加載的時候先于DllMain運行,在這個類的構造函數,會運行PatchWindowsFunctions來掛鉤所有dll的 malloc、free、new等分配函數,這樣就達到了替換功能,除此之外,
為了保證系統兼容性,掛鉤API的時候還實現了智能分析指令,否則寫入第一條Jmp指令的時候可能會破環后續指令的完整性。
2、LibcInfoWithPatchFunctions 和ThreadCache。
LibcInfoWithPatchFunctions模板類包含tcmalloc實現的優化后的malloc等一系列函數。LibcInfoWithPatchFunctions的模板參數在我看來沒什么用處,tcmalloc默認可以掛鉤
最多10個帶有malloc導出函數的庫(我想肯定是夠用了)。ThreadCache在每個線程都會有一個TLS對象:
__thread ThreadCache* ThreadCache::threadlocal_heap_。
3、可能的問題
設想下這樣一個情景:假如有一個dll 在tcmalloc之前加載,并且在分配了內存(使用crt提供的malloc),那么在加載tcmalloc后,tcmalloc會替換所有的free函數,然后,在某個時刻,
在前面的那個dll代碼中釋放該內存,這豈不是很危險。實際測試發現沒有任何問題,關鍵在這里:
span = Static::pageheap()->GetDescriptor(p);
if (!span) {
// span can be NULL because the pointer passed in is invalid
// (not something returned by malloc or friends), or because the
// pointer was allocated with some other allocator besides
// tcmalloc. The latter can happen if tcmalloc is linked in via
// a dynamic library, but is not listed last on the link line.
// In that case, libraries after it on the link line will
// allocate with libc malloc, but free with tcmalloc's free.
(*invalid_free_fn)(ptr); // Decide how to handle the bad free request
return;
}
tcmalloc會通過span識別這個內存是否自己分配的,如果不是,tcmalloc會調用該dll原始對應函數(這個很重要)釋放。這樣就解決了這個棘手的問題。
五、其他
其實tcmalloc使用的每個技術點我從前都用過,但是我從來沒想過用API掛鉤來實現這樣一個有趣的內存優化庫(即使想過,也是一閃而過就否定了)。
從tcmalloc得到靈感,結合常用的外掛技術,可以很輕松的開發一個獨立工具:這個工具可以掛載到指定進程進行內存優化,在我看來,這可能可以作為一個外掛輔助工具來優化那些
內存優化做的很差導致幀速很低的國產游戲。
posted @
2010-07-10 17:32 feixuwu 閱讀(10128) |
評論 (14) |
編輯 收藏