作者:CppExplore
http://m.shnenglu.com/CppExplore/和
http://blog.csdn.net/cppexplore同步發(fā)布
一 linux內(nèi)存管理以及內(nèi)存碎片產(chǎn)生原因 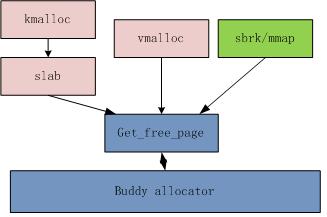
最底層使用伙伴算法管理內(nèi)存頁面。系統(tǒng)將所有空閑內(nèi)存頁面分10個組,每個組中的內(nèi)存塊大小依次是1,2,4......512個內(nèi)存頁面,每組中的內(nèi)存塊大小相同,并且以鏈表結(jié)構(gòu)保存。大小相同,并且內(nèi)存地址連續(xù)的兩個內(nèi)存塊稱為伙伴。伙伴算法的中心思想就是將成為伙伴的空閑內(nèi)存合并成一個更大的內(nèi)存塊。
os中使用get_free_page獲取空閑頁面,如果找不到合適大小的空閑頁面,則從更大的組中找到空閑內(nèi)存塊,分配出去,并將剩余內(nèi)存分割,插入到合適的組中。當歸還內(nèi)存時,啟動伙伴算法合并空閑內(nèi)存。如果不停的申請內(nèi)存,并且部分歸還,但歸還的內(nèi)存不能成為伙伴,長期運行后,所有內(nèi)存將被分割成不相鄰的小塊,當再次申請大塊內(nèi)存時,則可能由于找不到足夠大的連續(xù)內(nèi)存塊而失敗,這種零散的不相鄰的小塊內(nèi)存稱之為內(nèi)存碎片。當然這只是理論上的說明,伙伴算法本身就是為了解決內(nèi)存碎片問題。
二 malloc子系統(tǒng)內(nèi)存管理(dlmalloc) 應(yīng)用層面的開發(fā)并不是直接調(diào)用sbrk/mmap之類的函數(shù),而是調(diào)用malloc/free等malloc子系統(tǒng)提供的函數(shù),linux上安裝的大多為DougLea的dlmalloc或者其變形ptmalloc。下面以dlmalloc為例說明malloc工作的原理。
1 dlmalloc下名詞解釋: boundary tag: 邊界標記,每個空閑內(nèi)存塊均有頭部表識和尾部標識,尾部表識的作為是合并空閑內(nèi)存塊時更快。這部分空間屬于無法被應(yīng)用層面使用浪費的內(nèi)存空間。
smallbins: 小內(nèi)存箱。dlmalloc將8,16,24......512大小的內(nèi)存分箱,相臨箱子中的內(nèi)存相差8字節(jié)。每個箱子中的內(nèi)存大小均相同,并且以雙向鏈表連接。
treebins: 樹結(jié)構(gòu)箱。大于512字節(jié)的內(nèi)存不再是每8字節(jié)1箱,而是一個范圍段一箱。比如512~640, 640~896.....每個箱子的范圍段依次是128,256,512......。每箱中的結(jié)構(gòu)不再是雙向鏈表,而是樹形結(jié)構(gòu)。
dv chunk: 當申請內(nèi)存而在對應(yīng)大小的箱中找不到大小合適的內(nèi)存,則從更大的箱中找一塊內(nèi)存,劃分出需要的內(nèi)存,剩余的內(nèi)存稱之為dv chunk.
top chunk: 當dlmalloc中管理的內(nèi)存都找不到合適的內(nèi)存時,則調(diào)用sbrk從系統(tǒng)申請內(nèi)存,可以增長內(nèi)存方向的chunk稱為top chunk.
2 內(nèi)存分配算法 從合適的箱子中尋找內(nèi)存塊-->從相臨的箱子中尋找內(nèi)存塊-->從dv chunk分配內(nèi)存-->從其他可行的箱子中分配內(nèi)存-->從top chunk中分配內(nèi)存-->調(diào)用sbrk/mmap申請內(nèi)存
3 內(nèi)存釋放算法 臨近內(nèi)存合并-->如屬于top chunk,判斷top chunk>128k,是則歸還系統(tǒng)
-->不屬于chunk,則歸相應(yīng)的箱子
dlmalloc還有小內(nèi)存緩存等其他機制。可以看出經(jīng)過dlmalloc,頻繁調(diào)用malloc/free并不會產(chǎn)生內(nèi)存碎片,只要后續(xù)還有相同的內(nèi)存大小的內(nèi)存被申請,仍舊會使用以前的合適內(nèi)存,除非大量調(diào)用malloc之后少量釋放free,并且新的malloc又大于以前free的內(nèi)存大小,造成dlmalloc不停的從系統(tǒng)申請內(nèi)存,而free掉的小內(nèi)存因被使用的內(nèi)存割斷,而使top chunk<128k,不能歸還給系統(tǒng)。即便如此,占用的總內(nèi)存量也小于的確被使用的內(nèi)存量的2倍(使用的內(nèi)存和空閑的內(nèi)存交叉分割,并且空閑的內(nèi)存總是小于使用的內(nèi)存大小)。因此可以說,在沒有內(nèi)存泄露的情況,常規(guī)頻繁調(diào)用malloc/free并不會產(chǎn)生內(nèi)存碎片。
三 應(yīng)用層內(nèi)存池
即便沒有內(nèi)存碎片問題,應(yīng)用層仍然需要內(nèi)存池,原因如下:
1 使用的內(nèi)存固定可控 穩(wěn)定性角度
2 減少與內(nèi)核態(tài)交互的可能 性能角度
3 減少互斥操作 性能角度,各個線程直接調(diào)用malloc,極有可能有線程進入競態(tài)條件,陷入內(nèi)核態(tài)。
其中穩(wěn)定性只能是聊以自慰的說法,os本身都不可信,哪里還來得穩(wěn)定性的說法。最重要的出發(fā)點,是應(yīng)用層控制內(nèi)存,提高應(yīng)用層性能。那么如何創(chuàng)建使用內(nèi)存池,才能充分提高內(nèi)存使用的性能呢?我們先從著名的內(nèi)存池看起。
四 常見內(nèi)存池
變長內(nèi)存池:
1 apr pool : 針對業(yè)務(wù)處理,將整個業(yè)務(wù)場景分段,不同階段使用不同類型內(nèi)存池,內(nèi)存歸還池后并不能被再次使用,而是池本身可以被重復(fù)使用,特浪費內(nèi)存。
2 obstack: gcc自帶變長內(nèi)存池
定長內(nèi)存池:
1 SGI STL: 針對小內(nèi)存做池,字節(jié)長度為8,16......128共16個池,每個池中內(nèi)存大小相同,使用鏈表連接,小內(nèi)存采取永不歸還malloc子系統(tǒng)策略,大于128直接調(diào)用malloc。SGI STL為gcc攜帶的stl實現(xiàn)。vc以及bc攜帶的stl,雖然也有allocator對象,但并沒有真正的池,而是直接調(diào)用malloc。
2 boost/loki
兩種內(nèi)存池采用類似的底層算法,以loki為例子,首次申請一塊定長內(nèi)存,loki會一次性申請255個,之后再次申請從該池中直接獲取,從池中申請釋放內(nèi)存算法示例如下:

(1)首次申請內(nèi)存后,對空閑內(nèi)存編號,并且前一個內(nèi)存保存下一塊內(nèi)存的編號,一變量NextBlock保存下次可以申請出的內(nèi)存塊,首次NextBlock=0
(2)當申請出3塊內(nèi)存后,NextBlock=3
(3)當?shù)诙K內(nèi)存歸還時,根據(jù)內(nèi)存基址找到所屬的內(nèi)存chunk,對比chunk基址以及該持中內(nèi)存塊長度,找到該塊編號,尾部編號保存NextBlock,NextBlock=1
(4)再次歸還第三塊,第三塊尾部保存上次的NextBlock,NextBlock=2
(5)再次申請內(nèi)存,根據(jù)NextBlock指定分配出的內(nèi)存,NextBlock等于該塊內(nèi)存尾部指向的值1.
以上模擬stack的壓棧出棧行為.
loki和boost對內(nèi)存的處理上有稍許差別,包括內(nèi)存的組織層次上,這些差別我個人看都是loki相對于boost的缺點。
loki/boost代表了當前內(nèi)存池的最高水準,該池無任何冗余頭部(free的內(nèi)存才保存冗余信息),更節(jié)省內(nèi)存;另外分配釋放內(nèi)存快速,只有固定極少的常數(shù)步驟計算。
以上算法只是給內(nèi)存池的后續(xù)使用打下堅實基礎(chǔ),并沒有給出內(nèi)存池的使用方式。
五 內(nèi)存池使用方式分類
loki給出了內(nèi)存池使用的策略,分以下3種:
1 全局內(nèi)存池 所有相同長度的內(nèi)存申請,使用同一個內(nèi)存池,不同長度內(nèi)存申請使用不同內(nèi)存池。對池中的內(nèi)存進行申請釋放操作時,對池執(zhí)行加鎖操作。
2 對象內(nèi)存池 每個對象一個內(nèi)存池。內(nèi)存申請釋放執(zhí)行加鎖操作。
3 線程內(nèi)存池 相同長度的內(nèi)存并且在同一個內(nèi)存中的內(nèi)存申請釋放使用線程內(nèi)存池,內(nèi)存申請釋放不執(zhí)行加鎖操作。
對比第三部分,應(yīng)用層使用內(nèi)存池的原因。顯然全局內(nèi)存池并沒有解決性能問題,各線程并發(fā)申請內(nèi)存,仍然存在類似直接調(diào)用malloc的互斥問題。
而對象內(nèi)存池將這種互斥進一步降低,僅僅跨線程對同一對象申請釋放內(nèi)存才會遇到互斥問題。
而線程內(nèi)存池無疑是最高效的,沒有鎖開銷。
可見最佳的內(nèi)存池使用方式為,對存在跨線程操作的對象,使用對象內(nèi)存池,對于只在同一線程內(nèi)操作的對象使用線程內(nèi)存池。對象可以通過重載對象的operator new, operator delete等實現(xiàn)。
boost庫極其適合進一步封裝,供對象內(nèi)存池和線程內(nèi)存池(結(jié)合thread-specific storage)使用。
六 Linux下內(nèi)存池終結(jié)者 tcmalloc,可以通過cache等機制智能判斷應(yīng)該使用對象內(nèi)存池還是線程內(nèi)存池,編碼不需要任何額外策略,直接使用new/delete,只要最后連接上libtcmalloc之類的庫即可。可惜僅僅支持linux。
已有明確的測試數(shù)據(jù)支持,鏈接tcmalloc后,原cpu居高不下,突高的服務(wù)器程序,大大減少了直接調(diào)用malloc的互斥競態(tài)條件出現(xiàn),cpu趨于平穩(wěn)。典型的就是linux下鏈接tcmalloc后重編譯的mysql。