皮爾遜公式
前言
在很多推薦算法的地方,涉及到了很多關于數學的公式,如果簡單的應用這些公式,那當然較為的簡單,當如果有真正的理解這些公式里面隱含著的道理那就要下一定的苦功夫。
我們這里不從皮爾遜的公式講起,我們從物物的推薦開始。
問題
這里以音樂的推薦為例子,對于音樂的推薦很多人都在做,比較好解釋清楚。給你一首歌曲讓你推薦10首相識的歌曲。推薦的數據來源是這樣子的。每個人都會通過搜索歌曲來聽他們自己喜歡的歌曲。這樣歌曲就能有一些相關的特性了,關于數據的問題我們等下再進一步的說明。
如果我們不按數學的方法來思考這個問題的話,平常的人我們會怎樣來解決這個問題呢?我們是這樣想的,某一首音樂,他會存在不同的用戶中,如果這些用戶也存在著某些歌曲,我們就可以計算這首歌曲中在不同的用戶中還存在了多少歌曲,這些歌曲的個數是多少,就可以有一個排序,這就是我們要的相識歌曲。
我們簡單的用數學來描述一下:
假設有兩個人甲,乙,三首歌曲A B C,如果甲有這首歌就標記為1,沒有的話就標記為零
A B C
甲 1 1 1
乙 0 1 0
按照我們的算法
在甲用戶中
Dict[A][B]=1,Dict[A][C]=1
乙用戶沒有A
這樣歌曲A和B、C都相識,而且相識度都一樣為1。眨眼看上去這種算法,很完美,非常的完美,因為平時我們聊起推薦系統的時候,時不時的一開口就讓你這樣做了。真的無懈可擊了當然不是這樣,讓我們再看一次數據,你會發現,其實A,C 的數據是一樣一樣的,理論上我們會覺得A,跟C的相識度是最高的,但是他的相識度卻和B一樣,這開起來是不合理的,但這是為什么呢。

改進
回想一下如果進一步的假設,用1來標記喜歡,用0來標記不喜歡的話,我們這一種算法其實是沒有考慮不喜歡這個因素的。很多人都認為不能這樣假設,我告訴你,其實這是數據的問題,如果我們把使用的數據能夠滿足這里的假設,完全是可以采用的。
這里我想說的是,我并不認為我們使用的第一個算法,有多大的問題,只是想說的是,這種算法還不完美,還可以有改進的空間,這不就是我們一直所擁有的理念,把事情改變的更好。
進一步的再說:如果我們的數據不僅是1和0呢,用戶對歌曲有打分了,怎么辦呢?
A B C
甲 3 4 3
乙 0 2 0
當然很多人會說,算法也可以哦,字典里的數據跟著變Dict[A][B]=3,Dict[A][C]=3,但是有個問題不知道有沒有注意到,每個人對打分的理解是不一樣的,有的人覺得3分就是很好聽的歌曲,而有的人要覺得4分才是很好聽的歌曲,也就是說,每個人打分的標準不一樣,導致了打出的分數和比人比較的時候是不一樣的,但自己的標準大部分的時間是不會變的。
皮爾遜公式
這里我們需要一種算法。能夠概括這些情況的。這就是皮爾遜公式。
假設有兩個變量X、Y,那么兩變量間的皮爾遜相關系數可通過以下公式計算:
公式一:
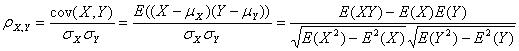
皮爾遜相關系數計算公式
公式二:

皮爾遜相關系數計算公式
公式三:
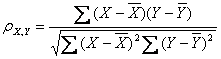
皮爾遜相關系數計算公式
公式四:

皮爾遜相關系數計算公式
以上列出的四個公式等價,其中E是數學期望,cov表示協方差,N表示變量取值的個數。
皮爾遜算法過于復雜,如果要有點理解的話,可以使用把維數降到二維,這樣就跟余弦定理有點相識了,相識度就是兩條直線的夾角,角度為0的時候,皮爾遜的值為1,就是最相識的,如果角度為180度,代表兩個牛馬不相干,皮爾遜的值為-1。
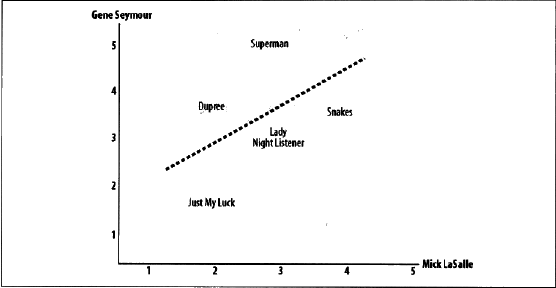
總結
很多時候,以前牛逼的數學家已經給了我們很多很好用的數學公式,只是如果沒有真正去用過的話,我們并不知道他所涉及的原理。好好的研究數學公式,他會給給我們的算法帶來一定的優化作用。關于公式的優化比較難了,以前的數學家給了我們很多的想法,而能夠優化的就是我們的數據,如何取數據,這里主要的是,那個數據離用戶的行為越近,離你使用的數學模型越近,那個數據就越好用。
參考:
http://lobert.iteye.com/blog/2024999
http://zh.wikipedia.org/wiki/%E7%9A%AE%E5%B0%94%E9%80%8A%E7%A7%AF%E7%9F%A9%E7%9B%B8%E5%85%B3%E7%B3%BB%E6%95%B0
posted on 2014-07-23 16:08
漂漂 閱讀(4254)
評論(1) 編輯 收藏 引用