基于云計(jì)算的價(jià)格查詢實(shí)現(xiàn)
上篇博客提到價(jià)格查詢功能�����,當(dāng)時(shí)正在考慮做成云計(jì)算模式,所以當(dāng)時(shí)連多線程都沒考慮,就是準(zhǔn)備將功能都交給云計(jì)算系統(tǒng)的�����,由云計(jì)算內(nèi)部管理線程和調(diào)度問題���,所以當(dāng)時(shí)實(shí)現(xiàn)就根本不用考慮多線程�,現(xiàn)在功能基本實(shí)現(xiàn),下面大致講講我的做法�。
國內(nèi)很多人談到全文檢索就必提lucene�����,提到云計(jì)算就必提google的map/reduce、開源的hadoop�、amazon的ec2�����,似乎只有那些東西才叫云計(jì)算,咱是實(shí)戰(zhàn)派�,沒興趣口舌之爭�����,在俺看來分布式存儲+分布式計(jì)算就叫云計(jì)算,俺就看了看google的map/reduce論文,照其思想在win下做了個(gè)簡單的job/task調(diào)度系統(tǒng)�,使其能支撐俺的第一個(gè)實(shí)戰(zhàn)應(yīng)用價(jià)格查詢�,圖示如下:
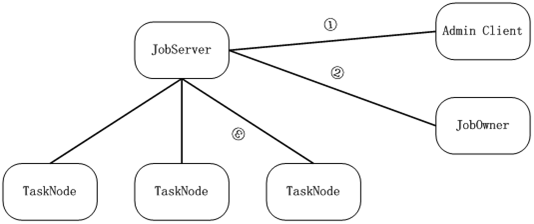
① ���、adminclient承擔(dān)管理功能���,可查看任務(wù)及執(zhí)行情況�����,可查看Tasknode機(jī)器情況,如果需要可管理Task,目前只支持簡單的幾條命令�����,adminclient主動連jobserver登錄成功后可發(fā)送管理命令�����。
② �����、JobOwner提交一個(gè)Job之后返回一個(gè)jobid,如果意外斷開可通過下次重連的時(shí)候提交jobid和一個(gè)sessionid可提取job結(jié)果數(shù)據(jù)�,job提交通過提交一個(gè)zip包即可�����,參數(shù)等文件都打在包里面,tasknode可直接解包執(zhí)行里面的dll�。Jobowner主動連jobserver���,登錄成功后可發(fā)job命令���。
③ TaskNode是執(zhí)行具體任務(wù)的客戶端���,job包用zip打包后發(fā)布給tasknode�����,tasknode參與計(jì)算并反饋結(jié)果���。TaskNode設(shè)計(jì)成多線程模式�,一個(gè)線程保持和jobserver的通信,其他線程參與運(yùn)算���,Tasknode可同時(shí)執(zhí)行多個(gè)不同的任務(wù),如a線程執(zhí)行價(jià)格查詢���,b線程執(zhí)行hash破解等�����。Tasknode主動連jobserver,登錄后可接受jobserver分派的任務(wù)�����,由于tasknode是主動連jobserver的����,所以即使是內(nèi)網(wǎng)機(jī)器或者任意有閑置資源的機(jī)器都可作為Tasknode,不管它是家里的�、公司的�、還是網(wǎng)吧的�,這也是該系統(tǒng)基于windows實(shí)現(xiàn)的一個(gè)重要前提,因?yàn)?/span>win的機(jī)器是如此的多�,在國內(nèi)win的機(jī)器無處不在�。
JobServer是job調(diào)度器�,管理包分發(fā)以及任務(wù)分割、調(diào)度�,典型的執(zhí)行流程是這樣��,jobowner提交一個(gè)命名的包給jobserver,jobserver將該包部署管理,之后jobowner 可給jobserver提交任務(wù),jobserver收到任務(wù)后根據(jù)任務(wù)指定的包配置執(zhí)行�,如部署包后裝載dll并執(zhí)行任務(wù)分割操作����,分割是將一個(gè)job分割為多個(gè)task�,之后再將每個(gè)task提交給一個(gè)tasknode執(zhí)行����,并管理tasknode的輸出以及可能的出錯,出錯現(xiàn)在的處理是交給另一個(gè)tasknode執(zhí)行��,當(dāng)剩下最后一個(gè)tasknode的時(shí)候會將該tsaknode同步叫給另一個(gè)不同的tasknode執(zhí)行��,不管誰最后成功執(zhí)行這個(gè)tasknode��,只要該task執(zhí)行成功立即結(jié)束整個(gè)job,并將結(jié)果反饋給jobowner����,jobowner也可在執(zhí)行中提交查詢命令�,jobserver會將被查詢job當(dāng)前的輸出返回�,這樣碰到需要長時(shí)間執(zhí)行的任務(wù)也能適用。
從以上介紹可以看到�,具體任務(wù)是由包執(zhí)行的����,這個(gè)包實(shí)際上可能是一個(gè)dll��,也可能是幾個(gè)dll加上一些配置文件組成����,之所以設(shè)計(jì)成這種模式�,主要是考慮整個(gè)系統(tǒng)在win上方便部署,主dll需要支持幾個(gè)固定的接口:
//任務(wù)dll初始化函數(shù)
typedef bool (*jobtask_init_)(jobtaskfunc *jtfunc, bool tasknode);
//map分割函數(shù)
typedef size_t (*jobtask_split_)(jobtaskfunc *jtfunc,
const char *input, size_t len,
std::vector<CAutoBuffer *> &vbuf);
//reduce打包函數(shù)
typedef size_t (*jobtask_reduce_)(jobtaskfunc *jtfunc,
std::vector<CAutoBuffer *> &vbuf,
CAutoBuffer &buf);
//Task執(zhí)行函數(shù)
typedef bool (*jobtask_map_)(jobtaskfunc *jtfunc, const char *cmdline, CAutoBuffer &outbuf);
//釋放函數(shù)
typedef bool (*jobtask_free_)(jobtaskfunc *jtfunc);
上面init函數(shù)主要執(zhí)行線程相關(guān)的初始化,該函數(shù)典型的可能是空�,或者是
CoInitialize(NULL); 等
Split函數(shù)是用來將job輸入分割為N個(gè)tasknode輸入的�,該函數(shù)由jobserver調(diào)用����,每個(gè)tasknode輸入就是map函數(shù)的輸入,tasknode的任務(wù)就是調(diào)用map函數(shù)����,并傳遞輸入,最后將輸出返回給jobserver,jobserver在需要的時(shí)候調(diào)用reduce將各個(gè)tasknode的輸出打包返回��,free函數(shù)是個(gè)輔助函數(shù)��,釋放資源的��。
熟悉google的map/reduce的應(yīng)該知道,我的實(shí)現(xiàn)簡化了reduce,在我的實(shí)現(xiàn)里面并沒有獨(dú)立的reduce worker�,該任務(wù)由jobserver自己做了�,這一方面是簡化實(shí)現(xiàn)����,另方面也是適應(yīng)需求的結(jié)果,畢竟在我的需求里面輸入是很少的(一個(gè)典型任務(wù)100字節(jié)量級),tasknode的計(jì)算是很多的��,輸出也是不多的(1k量級)����,所以由jobserver打包整個(gè)輸出也很輕松����,用不著一組獨(dú)立的reduce來管理輸出����。另外可以看到上面接口用了我的自定義類CAutoBuffer,這個(gè)類主要管理不定長數(shù)據(jù)的,其實(shí)用vector<char>也可,但考慮方便,我的實(shí)現(xiàn)內(nèi)部都用了CAutoBuffer�。一個(gè)典型的分布式應(yīng)用只要做一個(gè)dll�,有上面幾個(gè)函數(shù)�,并輸出一個(gè)
struct jobtaskfunc
{
//初始化函數(shù)
jobtask_init_ init;
//釋放函數(shù)
jobtask_free_ free;
//以下被tasknode調(diào)用
jobtask_map_ map;
//以下被jobserver調(diào)用
jobtask_split_ split;
jobtask_reduce_ reduce;
};
typedef jobtaskfunc *(WINAPI *create_jobtask_)();
函數(shù)即可。
學(xué)習(xí)map/reduce重要的是學(xué)習(xí)其思想��,并不拘泥于實(shí)現(xiàn)形式����,我想這大概正是國內(nèi)環(huán)境欠缺的,國內(nèi)能說得頭頭是道的人太多�,能動手干出結(jié)果來的人很少����,真正坐下來做實(shí)事的不多�,只喜歡抄抄概念����,拿別人的東西過來架設(shè)一下,就是這樣的人也能混成大拿����。我從map/reduce思想出發(fā)����,學(xué)習(xí)其思想����,簡化其實(shí)現(xiàn),為實(shí)際應(yīng)用服務(wù)����,雖然這個(gè)東西很簡單����,甚至可以說有些簡陋����,但實(shí)際效果不錯,雖然現(xiàn)在只部署了兩個(gè)點(diǎn),但總體上還是令人滿意的��。
實(shí)現(xiàn)這個(gè)jobserver/tasknode系統(tǒng)并部署價(jià)格查詢花了不到兩周時(shí)間��,實(shí)際上花在jobserver����、tasknode上的時(shí)間大概只有一周多一點(diǎn)��,ppsget.dll(具體干活的dll)用正則表達(dá)式分析網(wǎng)頁并提取輸出,該dll被應(yīng)用到多線程環(huán)境后也出了一些問題��,用boost::reg的時(shí)候居然偶爾會出現(xiàn)異常����,原以為boost::reg這樣的應(yīng)用應(yīng)該是非常明確的,要么找到����,要么沒有找到����,除此不應(yīng)該有第三態(tài)��,沒想到boost::reg這個(gè)不爭氣的東西不但不是二態(tài)的����,還容易出現(xiàn)異常��,試用了一下tr1::regex也是類似的問題��,無奈只能在外面包了一層異常處理��,雖然不再被異常搞死,但一旦出現(xiàn)異常就是很慢的����,要10s左右才返回��,現(xiàn)在也沒有特別好的辦法,只在異常的時(shí)候?qū)㈨撁姹4?,事后分析并改寫正則表達(dá)式��,盡量將正則表達(dá)式做小,將非貪婪式查找用少一點(diǎn)�。
下面看看我們價(jià)格查詢網(wǎng)站 http://www.shprog.com/pps.aspx 的輸出:
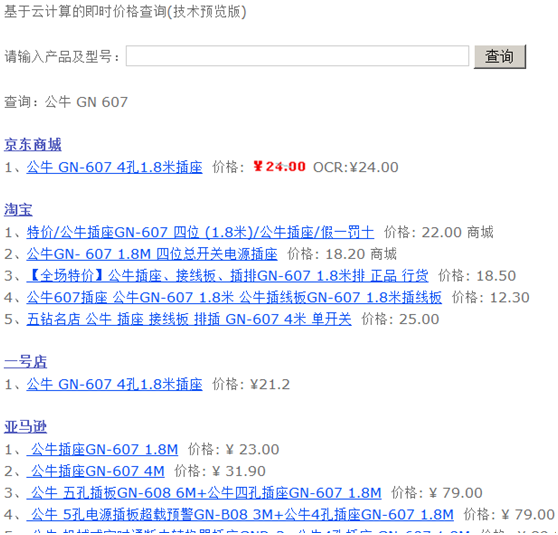
那個(gè)360的價(jià)格居然是圖片�,ocr模塊是俺同事搞的�,現(xiàn)在識別率能達(dá)到99%以上����,還是很不錯的。