堆和棧的區(qū)別
一、預(yù)備知識(shí)—程序的內(nèi)存分配
一個(gè)由c/C++編譯的程序占用的內(nèi)存分為以下幾個(gè)部分
1、棧區(qū)(stack)— 由編譯器自動(dòng)分配釋放 ,存放函數(shù)的參數(shù)值,局部變量的值等。其操作方式類(lèi)似于數(shù)據(jù)結(jié)構(gòu)中的棧。
2、堆區(qū)(heap) — 一般由程序員分配釋放, 若程序員不釋放,程序結(jié)束時(shí)可能由OS回收 。注意它與數(shù)據(jù)結(jié)構(gòu)中的堆是兩回事,分配方式倒是類(lèi)似于鏈表,呵呵。
3、全局區(qū)(靜態(tài)區(qū))(static)—,全局變量和靜態(tài)變量的存儲(chǔ)是放在一塊的,初始化的全局變量和靜態(tài)變量在一塊區(qū)域, 未初始化的全局變量和未初始化的靜態(tài)變量在相鄰的另一塊區(qū)域。 - 程序結(jié)束后有系統(tǒng)釋放
4、文字常量區(qū)—常量字符串就是放在這里的。 程序結(jié)束后由系統(tǒng)釋放
5、程序代碼區(qū)—存放函數(shù)體的二進(jìn)制代碼。
二、例子程序
這是一個(gè)前輩寫(xiě)的,非常詳細(xì)
//main.cpp
int a = 0; 全局初始化區(qū)
char *p1; 全局未初始化區(qū)
main()
{
int b; 棧
char s[] = "abc"; 棧
char *p2; 棧
char *p3 = "123456"; 123456\0在常量區(qū),p3在棧上。
static int c =0; 全局(靜態(tài))初始化區(qū)
p1 = (char *)malloc(10);
p2 = (char *)malloc(20);
分配得來(lái)得10和20字節(jié)的區(qū)域就在堆區(qū)。
strcpy(p1, "123456"); 123456\0放在常量區(qū),編譯器可能會(huì)將它與p3所指向的"123456"優(yōu)化成一個(gè)地方。
}
二、堆和棧的理論知識(shí)
2.1申請(qǐng)方式
stack:
由系統(tǒng)自動(dòng)分配。 例如,聲明在函數(shù)中一個(gè)局部變量 int b; 系統(tǒng)自動(dòng)在棧中為b開(kāi)辟空間
heap:
需要程序員自己申請(qǐng),并指明大小,在c中malloc函數(shù)
如p1 = (char *)malloc(10);
在C++中用new運(yùn)算符
如p2 = (char *)malloc(10);
但是注意p1、p2本身是在棧中的。
2.2
申請(qǐng)后系統(tǒng)的響應(yīng)
棧:只要棧的剩余空間大于所申請(qǐng)空間,系統(tǒng)將為程序提供內(nèi)存,否則將報(bào)異常提示棧溢出。
堆:首先應(yīng)該知道操作系統(tǒng)有一個(gè)記錄空閑內(nèi)存地址的鏈表,當(dāng)系統(tǒng)收到程序的申請(qǐng)時(shí),
會(huì)遍歷該鏈表,尋找第一個(gè)空間大于所申請(qǐng)空間的堆結(jié)點(diǎn),然后將該結(jié)點(diǎn)從空閑結(jié)點(diǎn)鏈表中刪除,并將該結(jié)點(diǎn)的空間分配給程序,另外,對(duì)于大多數(shù)系統(tǒng),會(huì)在這塊內(nèi)存空間中的首地址處記錄本次分配的大小,這樣,代碼中的delete語(yǔ)句才能正確的釋放本內(nèi)存空間。另外,由于找到的堆結(jié)點(diǎn)的大小不一定正好等于申請(qǐng)的大小,系統(tǒng)會(huì)自動(dòng)的將多余的那部分重新放入空閑鏈表中。
2.3申請(qǐng)大小的限制
棧:在Windows下,棧是向低地址擴(kuò)展的數(shù)據(jù)結(jié)構(gòu),是一塊連續(xù)的內(nèi)存的區(qū)域。這句話的意思是棧頂?shù)牡刂泛蜅5淖畲笕萘渴窍到y(tǒng)預(yù)先規(guī)定好的,在WINDOWS下,棧的大小是2M(也有的說(shuō)是1M,總之是一個(gè)編譯時(shí)就確定的常數(shù)),如果申請(qǐng)的空間超過(guò)棧的剩余空間時(shí),將提示overflow。因此,能從棧獲得的空間較小。
堆:堆是向高地址擴(kuò)展的數(shù)據(jù)結(jié)構(gòu),是不連續(xù)的內(nèi)存區(qū)域。這是由于系統(tǒng)是用鏈表來(lái)存儲(chǔ)的空閑內(nèi)存地址的,自然是不連續(xù)的,而鏈表的遍歷方向是由低地址向高地址。堆的大小受限于計(jì)算機(jī)系統(tǒng)中有效的虛擬內(nèi)存。由此可見(jiàn),堆獲得的空間比較靈活,也比較大。
2.4申請(qǐng)效率的比較:
棧由系統(tǒng)自動(dòng)分配,速度較快。但程序員是無(wú)法控制的。
堆是由new分配的內(nèi)存,一般速度比較慢,而且容易產(chǎn)生內(nèi)存碎片,不過(guò)用起來(lái)最方便.
另外,在WINDOWS下,最好的方式是用VirtualAlloc分配內(nèi)存,他不是在堆,也不是在棧是直接在進(jìn)程的地址空間中保留一快內(nèi)存,雖然用起來(lái)最不方便。但是速度快,也最靈活。
2.5堆和棧中的存儲(chǔ)內(nèi)容
棧: 在函數(shù)調(diào)用時(shí),第一個(gè)進(jìn)棧的是主函數(shù)中后的下一條指令(函數(shù)調(diào)用語(yǔ)句的下一條可執(zhí)行語(yǔ)句)的地址,然后是函數(shù)的各個(gè)參數(shù),在大多數(shù)的C編譯器中,參數(shù)是由右往左入棧的,然后是函數(shù)中的局部變量。注意靜態(tài)變量是不入棧的。
當(dāng)本次函數(shù)調(diào)用結(jié)束后,局部變量先出棧,然后是參數(shù),最后棧頂指針指向最開(kāi)始存的地址,也就是主函數(shù)中的下一條指令,程序由該點(diǎn)繼續(xù)運(yùn)行。
堆:一般是在堆的頭部用一個(gè)字節(jié)存放堆的大小。堆中的具體內(nèi)容有程序員安排。
2.6存取效率的比較
char s1[] = "aaaaaaaaaaaaaaa";
char *s2 = "bbbbbbbbbbbbbbbbb";
aaaaaaaaaaa是在運(yùn)行時(shí)刻賦值的;
而bbbbbbbbbbb是在編譯時(shí)就確定的;
但是,在以后的存取中,在棧上的數(shù)組比指針?biāo)赶虻淖址?例如堆)快。
比如:
#include
void main()
{
char a = 1;
char c[] = "1234567890";
char *p ="1234567890";
a = c[1];
a = p[1];
return;
}
對(duì)應(yīng)的匯編代碼
10: a = c[1];
00401067 8A 4D F1 mov cl,byte ptr [ebp-0Fh]
0040106A 88 4D FC mov byte ptr [ebp-4],cl
11: a = p[1];
0040106D 8B 55 EC mov edx,dword ptr [ebp-14h]
00401070 8A 42 01 mov al,byte ptr [edx+1]
00401073 88 45 FC mov byte ptr [ebp-4],al
第一種在讀取時(shí)直接就把字符串中的元素讀到寄存器cl中,而第二種則要先把指針值讀到edx中,在根據(jù)edx讀取字符,顯然慢了。
2.7小結(jié):
堆和棧的區(qū)別可以用如下的比喻來(lái)看出:
使用棧就象我們?nèi)ワ堭^里吃飯,只管點(diǎn)菜(發(fā)出申請(qǐng))、付錢(qián)、和吃(使用),吃飽了就走,不必理會(huì)切菜、洗菜等準(zhǔn)備工作和洗碗、刷鍋等掃尾工作,他的好處是快捷,但是自由度小。
使用堆就象是自己動(dòng)手做喜歡吃的菜肴,比較麻煩,但是比較符合自己的口味,而且自由度大。
windows進(jìn)程中的內(nèi)存結(jié)構(gòu)
在閱讀本文之前,如果你連堆棧是什么多不知道的話,請(qǐng)先閱讀文章后面的基礎(chǔ)知識(shí)。
接觸過(guò)編程的人都知道,高級(jí)語(yǔ)言都能通過(guò)變量名來(lái)訪問(wèn)內(nèi)存中的數(shù)據(jù)。那么這些變量在內(nèi)存中是如何存放的呢?程序又是如何使用這些變量的呢?下面就會(huì)對(duì)此進(jìn)行深入的討論。下文中的C語(yǔ)言代碼如沒(méi)有特別聲明,默認(rèn)都使用VC編譯的release版。
首先,來(lái)了解一下 C 語(yǔ)言的變量是如何在內(nèi)存分部的。C 語(yǔ)言有全局變量(Global)、本地變量(Local),靜態(tài)變量(Static)、寄存器變量(Regeister)。每種變量都有不同的分配方式。先來(lái)看下面這段代碼:
#include <stdio.h>
int g1=0, g2=0, g3=0;
int main()
{
static int s1=0, s2=0, s3=0;
int v1=0, v2=0, v3=0;
//打印出各個(gè)變量的內(nèi)存地址
printf("0x%08x\n",&v1); //打印各本地變量的內(nèi)存地址
printf("0x%08x\n",&v2);
printf("0x%08x\n\n",&v3);
printf("0x%08x\n",&g1); //打印各全局變量的內(nèi)存地址
printf("0x%08x\n",&g2);
printf("0x%08x\n\n",&g3);
printf("0x%08x\n",&s1); //打印各靜態(tài)變量的內(nèi)存地址
printf("0x%08x\n",&s2);
printf("0x%08x\n\n",&s3);
return 0;
}
編譯后的執(zhí)行結(jié)果是:
0x0012ff78
0x0012ff7c
0x0012ff80
0x004068d0
0x004068d4
0x004068d8
0x004068dc
0x004068e0
0x004068e4
輸出的結(jié)果就是變量的內(nèi)存地址。其中v1,v2,v3是本地變量,g1,g2,g3是全局變量,s1,s2,s3是靜態(tài)變量。你可以看到這些變量在內(nèi)存是連續(xù)分布的,但是本地變量和全局變量分配的內(nèi)存地址差了十萬(wàn)八千里,而全局變量和靜態(tài)變量分配的內(nèi)存是連續(xù)的。這是因?yàn)楸镜刈兞亢腿?靜態(tài)變量是分配在不同類(lèi)型的內(nèi)存區(qū)域中的結(jié)果。對(duì)于一個(gè)進(jìn)程的內(nèi)存空間而言,可以在邏輯上分成3個(gè)部份:代碼區(qū),靜態(tài)數(shù)據(jù)區(qū)和動(dòng)態(tài)數(shù)據(jù)區(qū)。動(dòng)態(tài)數(shù)據(jù)區(qū)一般就是“堆棧”。“棧(stack)”和“堆(heap)”是兩種不同的動(dòng)態(tài)數(shù)據(jù)區(qū),棧是一種線性結(jié)構(gòu),堆是一種鏈?zhǔn)浇Y(jié)構(gòu)。進(jìn)程的每個(gè)線程都有私有的“棧”,所以每個(gè)線程雖然代碼一樣,但本地變量的數(shù)據(jù)都是互不干擾。一個(gè)堆棧可以通過(guò)“基地址”和“棧頂”地址來(lái)描述。全局變量和靜態(tài)變量分配在靜態(tài)數(shù)據(jù)區(qū),本地變量分配在動(dòng)態(tài)數(shù)據(jù)區(qū),即堆棧中。程序通過(guò)堆棧的基地址和偏移量來(lái)訪問(wèn)本地變量。
├———————┤低端內(nèi)存區(qū)域
│ …… │
├———————┤
│ 動(dòng)態(tài)數(shù)據(jù)區(qū) │
├———————┤
│ …… │
├———————┤
│ 代碼區(qū) │
├———————┤
│ 靜態(tài)數(shù)據(jù)區(qū) │
├———————┤
│ …… │
├———————┤高端內(nèi)存區(qū)域
堆棧是一個(gè)先進(jìn)后出的數(shù)據(jù)結(jié)構(gòu),棧頂?shù)刂房偸切∮诘扔跅5幕刂贰N覀兛梢韵攘私庖幌潞瘮?shù)調(diào)用的過(guò)程,以便對(duì)堆棧在程序中的作用有更深入的了解。不同的語(yǔ)言有不同的函數(shù)調(diào)用規(guī)定,這些因素有參數(shù)的壓入規(guī)則和堆棧的平衡。windows API的調(diào)用規(guī)則和ANSI C的函數(shù)調(diào)用規(guī)則是不一樣的,前者由被調(diào)函數(shù)調(diào)整堆棧,后者由調(diào)用者調(diào)整堆棧。兩者通過(guò)“__stdcall”和“__cdecl”前綴區(qū)分。先看下面這段代碼:
#include <stdio.h>
void __stdcall func(int param1,int param2,int param3)
{
int var1=param1;
int var2=param2;
int var3=param3;
printf("0x%08x\n",¶m1); //打印出各個(gè)變量的內(nèi)存地址
printf("0x%08x\n",¶m2);
printf("0x%08x\n\n",¶m3);
printf("0x%08x\n",&var1);
printf("0x%08x\n",&var2);
printf("0x%08x\n\n",&var3);
return;
}
int main()
{
func(1,2,3);
return 0;
}
編譯后的執(zhí)行結(jié)果是:
0x0012ff78
0x0012ff7c
0x0012ff80
0x0012ff68
0x0012ff6c
0x0012ff70
├———————┤<—函數(shù)執(zhí)行時(shí)的棧頂(ESP)、低端內(nèi)存區(qū)域
│ …… │
├———————┤
│ var 1 │
├———————┤
│ var 2 │
├———————┤
│ var 3 │
├———————┤
│ RET │
├———————┤<—“__cdecl”函數(shù)返回后的棧頂(ESP)
│ parameter 1 │
├———————┤
│ parameter 2 │
├———————┤
│ parameter 3 │
├———————┤<—“__stdcall”函數(shù)返回后的棧頂(ESP)
│ …… │
├———————┤<—棧底(基地址 EBP)、高端內(nèi)存區(qū)域
上圖就是函數(shù)調(diào)用過(guò)程中堆棧的樣子了。首先,三個(gè)參數(shù)以從又到左的次序壓入堆棧,先壓“param3”,再壓“param2”,最后壓入“param1”;然后壓入函數(shù)的返回地址(RET),接著跳轉(zhuǎn)到函數(shù)地址接著執(zhí)行(這里要補(bǔ)充一點(diǎn),介紹UNIX下的緩沖溢出原理的文章中都提到在壓入RET后,繼續(xù)壓入當(dāng)前EBP,然后用當(dāng)前ESP代替EBP。然而,有一篇介紹windows下函數(shù)調(diào)用的文章中說(shuō),在windows下的函數(shù)調(diào)用也有這一步驟,但根據(jù)我的實(shí)際調(diào)試,并未發(fā)現(xiàn)這一步,這還可以從param3和var1之間只有4字節(jié)的間隙這點(diǎn)看出來(lái));第三步,將棧頂(ESP)減去一個(gè)數(shù),為本地變量分配內(nèi)存空間,上例中是減去12字節(jié)(ESP=ESP-3*4,每個(gè)int變量占用4個(gè)字節(jié));接著就初始化本地變量的內(nèi)存空間。由于“__stdcall”調(diào)用由被調(diào)函數(shù)調(diào)整堆棧,所以在函數(shù)返回前要恢復(fù)堆棧,先回收本地變量占用的內(nèi)存(ESP=ESP+3*4),然后取出返回地址,填入EIP寄存器,回收先前壓入?yún)?shù)占用的內(nèi)存(ESP=ESP+3*4),繼續(xù)執(zhí)行調(diào)用者的代碼。參見(jiàn)下列匯編代碼:
;--------------func 函數(shù)的匯編代碼-------------------
:00401000 83EC0C sub esp, 0000000C //創(chuàng)建本地變量的內(nèi)存空間
:00401003 8B442410 mov eax, dword ptr [esp+10]
:00401007 8B4C2414 mov ecx, dword ptr [esp+14]
:0040100B 8B542418 mov edx, dword ptr [esp+18]
:0040100F 89442400 mov dword ptr [esp], eax
:00401013 8D442410 lea eax, dword ptr [esp+10]
:00401017 894C2404 mov dword ptr [esp+04], ecx
……………………(省略若干代碼)
:00401075 83C43C add esp, 0000003C ;恢復(fù)堆棧,回收本地變量的內(nèi)存空間
:00401078 C3 ret 000C ;函數(shù)返回,恢復(fù)參數(shù)占用的內(nèi)存空間
;如果是“__cdecl”的話,這里是“ret”,堆棧將由調(diào)用者恢復(fù)
;-------------------函數(shù)結(jié)束-------------------------
;--------------主程序調(diào)用func函數(shù)的代碼--------------
:00401080 6A03 push 00000003 //壓入?yún)?shù)param3
:00401082 6A02 push 00000002 //壓入?yún)?shù)param2
:00401084 6A01 push 00000001 //壓入?yún)?shù)param1
:00401086 E875FFFFFF call 00401000 //調(diào)用func函數(shù)
;如果是“__cdecl”的話,將在這里恢復(fù)堆棧,“add esp, 0000000C”
聰明的讀者看到這里,差不多就明白緩沖溢出的原理了。先來(lái)看下面的代碼:
#include <stdio.h>
#include <string.h>
void __stdcall func()
{
char lpBuff[8]="\0";
strcat(lpBuff,"AAAAAAAAAAA");
return;
}
int main()
{
func();
return 0;
}
編譯后執(zhí)行一下回怎么樣?哈,“"0x00414141"指令引用的"0x00000000"內(nèi)存。該內(nèi)存不能為"read"。”,“非法操作”嘍!"41"就是"A"的16進(jìn)制的ASCII碼了,那明顯就是strcat這句出的問(wèn)題了。"lpBuff"的大小只有8字節(jié),算進(jìn)結(jié)尾的\0,那strcat最多只能寫(xiě)入7個(gè)"A",但程序?qū)嶋H寫(xiě)入了11個(gè)"A"外加1個(gè)\0。再來(lái)看看上面那幅圖,多出來(lái)的4個(gè)字節(jié)正好覆蓋了RET的所在的內(nèi)存空間,導(dǎo)致函數(shù)返回到一個(gè)錯(cuò)誤的內(nèi)存地址,執(zhí)行了錯(cuò)誤的指令。如果能精心構(gòu)造這個(gè)字符串,使它分成三部分,前一部份僅僅是填充的無(wú)意義數(shù)據(jù)以達(dá)到溢出的目的,接著是一個(gè)覆蓋RET的數(shù)據(jù),緊接著是一段shellcode,那只要著個(gè)RET地址能指向這段shellcode的第一個(gè)指令,那函數(shù)返回時(shí)就能執(zhí)行shellcode了。但是軟件的不同版本和不同的運(yùn)行環(huán)境都可能影響這段shellcode在內(nèi)存中的位置,那么要構(gòu)造這個(gè)RET是十分困難的。一般都在RET和shellcode之間填充大量的NOP指令,使得exploit有更強(qiáng)的通用性。
├———————┤<—低端內(nèi)存區(qū)域
│ …… │
├———————┤<—由exploit填入數(shù)據(jù)的開(kāi)始
│ │
│ buffer │<—填入無(wú)用的數(shù)據(jù)
│ │
├———————┤
│ RET │<—指向shellcode,或NOP指令的范圍
├———————┤
│ NOP │
│ …… │<—填入的NOP指令,是RET可指向的范圍
│ NOP │
├———————┤
│ │
│ shellcode │
│ │
├———————┤<—由exploit填入數(shù)據(jù)的結(jié)束
│ …… │
├———————┤<—高端內(nèi)存區(qū)域
windows下的動(dòng)態(tài)數(shù)據(jù)除了可存放在棧中,還可以存放在堆中。了解C++的朋友都知道,C++可以使用new關(guān)鍵字來(lái)動(dòng)態(tài)分配內(nèi)存。來(lái)看下面的C++代碼:
#include <stdio.h>
#include <iostream.h>
#include <windows.h>
void func()
{
char *buffer=new char[128];
char bufflocal[128];
static char buffstatic[128];
printf("0x%08x\n",buffer); //打印堆中變量的內(nèi)存地址
printf("0x%08x\n",bufflocal); //打印本地變量的內(nèi)存地址
printf("0x%08x\n",buffstatic); //打印靜態(tài)變量的內(nèi)存地址
}
void main()
{
func();
return;
}
程序執(zhí)行結(jié)果為:
0x004107d0
0x0012ff04
0x004068c0
可以發(fā)現(xiàn)用new關(guān)鍵字分配的內(nèi)存即不在棧中,也不在靜態(tài)數(shù)據(jù)區(qū)。VC編譯器是通過(guò)windows下的“堆(heap)”來(lái)實(shí)現(xiàn)new關(guān)鍵字的內(nèi)存動(dòng)態(tài)分配。在講“堆”之前,先來(lái)了解一下和“堆”有關(guān)的幾個(gè)API函數(shù):
HeapAlloc 在堆中申請(qǐng)內(nèi)存空間
HeapCreate 創(chuàng)建一個(gè)新的堆對(duì)象
HeapDestroy 銷(xiāo)毀一個(gè)堆對(duì)象
HeapFree 釋放申請(qǐng)的內(nèi)存
HeapWalk 枚舉堆對(duì)象的所有內(nèi)存塊
GetProcessHeap 取得進(jìn)程的默認(rèn)堆對(duì)象
GetProcessHeaps 取得進(jìn)程所有的堆對(duì)象
LocalAlloc
GlobalAlloc
當(dāng)進(jìn)程初始化時(shí),系統(tǒng)會(huì)自動(dòng)為進(jìn)程創(chuàng)建一個(gè)默認(rèn)堆,這個(gè)堆默認(rèn)所占內(nèi)存的大小為1M。堆對(duì)象由系統(tǒng)進(jìn)行管理,它在內(nèi)存中以鏈?zhǔn)浇Y(jié)構(gòu)存在。通過(guò)下面的代碼可以通過(guò)堆動(dòng)態(tài)申請(qǐng)內(nèi)存空間:
HANDLE hHeap=GetProcessHeap();
char *buff=HeapAlloc(hHeap,0,8);
其中hHeap是堆對(duì)象的句柄,buff是指向申請(qǐng)的內(nèi)存空間的地址。那這個(gè)hHeap究竟是什么呢?它的值有什么意義嗎?看看下面這段代碼吧:
#pragma comment(linker,"/entry:main") //定義程序的入口
#include <windows.h>
_CRTIMP int (__cdecl *printf)(const char *, ...); //定義STL函數(shù)printf
/*---------------------------------------------------------------------------
寫(xiě)到這里,我們順便來(lái)復(fù)習(xí)一下前面所講的知識(shí):
(*注)printf函數(shù)是C語(yǔ)言的標(biāo)準(zhǔn)函數(shù)庫(kù)中函數(shù),VC的標(biāo)準(zhǔn)函數(shù)庫(kù)由msvcrt.dll模塊實(shí)現(xiàn)。
由函數(shù)定義可見(jiàn),printf的參數(shù)個(gè)數(shù)是可變的,函數(shù)內(nèi)部無(wú)法預(yù)先知道調(diào)用者壓入的參數(shù)個(gè)數(shù),函數(shù)只能通過(guò)分析第一個(gè)參數(shù)字符串的格式來(lái)獲得壓入?yún)?shù)的信息,由于這里參數(shù)的個(gè)數(shù)是動(dòng)態(tài)的,所以必須由調(diào)用者來(lái)平衡堆棧,這里便使用了__cdecl調(diào)用規(guī)則。BTW,Windows系統(tǒng)的API函數(shù)基本上是__stdcall調(diào)用形式,只有一個(gè)API例外,那就是wsprintf,它使用__cdecl調(diào)用規(guī)則,同printf函數(shù)一樣,這是由于它的參數(shù)個(gè)數(shù)是可變的緣故。
---------------------------------------------------------------------------*/
void main()
{
HANDLE hHeap=GetProcessHeap();
char *buff=HeapAlloc(hHeap,0,0x10);
char *buff2=HeapAlloc(hHeap,0,0x10);
HMODULE hMsvcrt=LoadLibrary("msvcrt.dll");
printf=(void *)GetProcAddress(hMsvcrt,"printf");
printf("0x%08x\n",hHeap);
printf("0x%08x\n",buff);
printf("0x%08x\n\n",buff2);
}
執(zhí)行結(jié)果為:
0x00130000
0x00133100
0x00133118
hHeap的值怎么和那個(gè)buff的值那么接近呢?其實(shí)hHeap這個(gè)句柄就是指向HEAP首部的地址。在進(jìn)程的用戶(hù)區(qū)存著一個(gè)叫PEB(進(jìn)程環(huán)境塊)的結(jié)構(gòu),這個(gè)結(jié)構(gòu)中存放著一些有關(guān)進(jìn)程的重要信息,其中在PEB首地址偏移0x18處存放的ProcessHeap就是進(jìn)程默認(rèn)堆的地址,而偏移0x90處存放了指向進(jìn)程所有堆的地址列表的指針。windows有很多API都使用進(jìn)程的默認(rèn)堆來(lái)存放動(dòng)態(tài)數(shù)據(jù),如windows 2000下的所有ANSI版本的函數(shù)都是在默認(rèn)堆中申請(qǐng)內(nèi)存來(lái)轉(zhuǎn)換ANSI字符串到Unicode字符串的。對(duì)一個(gè)堆的訪問(wèn)是順序進(jìn)行的,同一時(shí)刻只能有一個(gè)線程訪問(wèn)堆中的數(shù)據(jù),當(dāng)多個(gè)線程同時(shí)有訪問(wèn)要求時(shí),只能排隊(duì)等待,這樣便造成程序執(zhí)行效率下降。
最后來(lái)說(shuō)說(shuō)內(nèi)存中的數(shù)據(jù)對(duì)齊。所位數(shù)據(jù)對(duì)齊,是指數(shù)據(jù)所在的內(nèi)存地址必須是該數(shù)據(jù)長(zhǎng)度的整數(shù)倍,DWORD數(shù)據(jù)的內(nèi)存起始地址能被4除盡,WORD數(shù)據(jù)的內(nèi)存起始地址能被2除盡,x86 CPU能直接訪問(wèn)對(duì)齊的數(shù)據(jù),當(dāng)他試圖訪問(wèn)一個(gè)未對(duì)齊的數(shù)據(jù)時(shí),會(huì)在內(nèi)部進(jìn)行一系列的調(diào)整,這些調(diào)整對(duì)于程序來(lái)說(shuō)是透明的,但是會(huì)降低運(yùn)行速度,所以編譯器在編譯程序時(shí)會(huì)盡量保證數(shù)據(jù)對(duì)齊。同樣一段代碼,我們來(lái)看看用VC、Dev-C++和lcc三個(gè)不同編譯器編譯出來(lái)的程序的執(zhí)行結(jié)果:
#include <stdio.h>
int main()
{
int a;
char b;
int c;
printf("0x%08x\n",&a);
printf("0x%08x\n",&b);
printf("0x%08x\n",&c);
return 0;
}
這是用VC編譯后的執(zhí)行結(jié)果:
0x0012ff7c
0x0012ff7b
0x0012ff80
變量在內(nèi)存中的順序:b(1字節(jié))-a(4字節(jié))-c(4字節(jié))。
這是用Dev-C++編譯后的執(zhí)行結(jié)果:
0x0022ff7c
0x0022ff7b
0x0022ff74
變量在內(nèi)存中的順序:c(4字節(jié))-中間相隔3字節(jié)-b(占1字節(jié))-a(4字節(jié))。
這是用lcc編譯后的執(zhí)行結(jié)果:
0x0012ff6c
0x0012ff6b
0x0012ff64
變量在內(nèi)存中的順序:同上。
三個(gè)編譯器都做到了數(shù)據(jù)對(duì)齊,但是后兩個(gè)編譯器顯然沒(méi)VC“聰明”,讓一個(gè)char占了4字節(jié),浪費(fèi)內(nèi)存哦。
基礎(chǔ)知識(shí):
堆棧是一種簡(jiǎn)單的數(shù)據(jù)結(jié)構(gòu),是一種只允許在其一端進(jìn)行插入或刪除的線性表。允許插入或刪除操作的一端稱(chēng)為棧頂,另一端稱(chēng)為棧底,對(duì)堆棧的插入和刪除操作被稱(chēng)為入棧和出棧。有一組CPU指令可以實(shí)現(xiàn)對(duì)進(jìn)程的內(nèi)存實(shí)現(xiàn)堆棧訪問(wèn)。其中,POP指令實(shí)現(xiàn)出棧操作,PUSH指令實(shí)現(xiàn)入棧操作。CPU的ESP寄存器存放當(dāng)前線程的棧頂指針,EBP寄存器中保存當(dāng)前線程的棧底指針。CPU的EIP寄存器存放下一個(gè)CPU指令存放的內(nèi)存地址,當(dāng)CPU執(zhí)行完當(dāng)前的指令后,從EIP寄存器中讀取下一條指令的內(nèi)存地址,然后繼續(xù)執(zhí)行。
參考:《Windows下的HEAP溢出及其利用》by: isno
《windows核心編程》by: Jeffrey Richter
摘要: 討論常見(jiàn)的堆性能問(wèn)題以及如何防范它們。(共 9 頁(yè))
前言
您是否是動(dòng)態(tài)分配的 C/C++ 對(duì)象忠實(shí)且幸運(yùn)的用戶(hù)?您是否在模塊間的往返通信中頻繁地使用了“自動(dòng)化”?您的程序是否因堆分配而運(yùn)行起來(lái)很慢?不僅僅您遇到這樣的問(wèn)題。幾乎所有項(xiàng)目遲早都會(huì)遇到堆問(wèn)題。大家都想說(shuō),“我的代碼真正好,只是堆太慢”。那只是部分正確。更深入理解堆及其用法、以及會(huì)發(fā)生什么問(wèn)題,是很有用的。
什么是堆?
(如果您已經(jīng)知道什么是堆,可以跳到“什么是常見(jiàn)的堆性能問(wèn)題?”部分)
在程序中,使用堆來(lái)動(dòng)態(tài)分配和釋放對(duì)象。在下列情況下,調(diào)用堆操作:
事先不知道程序所需對(duì)象的數(shù)量和大小。
對(duì)象太大而不適合堆棧分配程序。
堆使用了在運(yùn)行時(shí)分配給代碼和堆棧的內(nèi)存之外的部分內(nèi)存。下圖給出了堆分配程序的不同層。
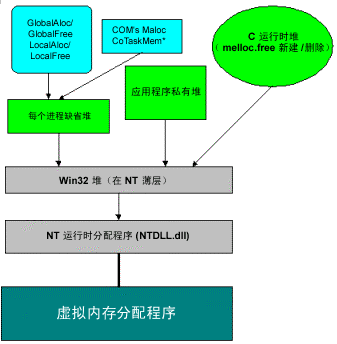
GlobalAlloc/GlobalFree:Microsoft Win32 堆調(diào)用,這些調(diào)用直接與每個(gè)進(jìn)程的默認(rèn)堆進(jìn)行對(duì)話。
LocalAlloc/LocalFree:Win32 堆調(diào)用(為了與 Microsoft Windows NT 兼容),這些調(diào)用直接與每個(gè)進(jìn)程的默認(rèn)堆進(jìn)行對(duì)話。
COM 的 IMalloc 分配程序(或 CoTaskMemAlloc / CoTaskMemFree):函數(shù)使用每個(gè)進(jìn)程的默認(rèn)堆。自動(dòng)化程序使用“組件對(duì)象模型 (COM)”的分配程序,而申請(qǐng)的程序使用每個(gè)進(jìn)程堆。
C/C++ 運(yùn)行時(shí) (CRT) 分配程序:提供了 malloc() 和 free() 以及 new 和 delete 操作符。如 Microsoft Visual Basic 和 Java 等語(yǔ)言也提供了新的操作符并使用垃圾收集來(lái)代替堆。CRT 創(chuàng)建自己的私有堆,駐留在 Win32 堆的頂部。
Windows NT 中,Win32 堆是 Windows NT 運(yùn)行時(shí)分配程序周?chē)谋印K?nbsp;API 轉(zhuǎn)發(fā)它們的請(qǐng)求給 NTDLL。
Windows NT 運(yùn)行時(shí)分配程序提供 Windows NT 內(nèi)的核心堆分配程序。它由具有 128 個(gè)大小從 8 到 1,024 字節(jié)的空閑列表的前端分配程序組成。后端分配程序使用虛擬內(nèi)存來(lái)保留和提交頁(yè)。
在圖表的底部是“虛擬內(nèi)存分配程序”,操作系統(tǒng)使用它來(lái)保留和提交頁(yè)。所有分配程序使用虛擬內(nèi)存進(jìn)行數(shù)據(jù)的存取。
分配和釋放塊不就那么簡(jiǎn)單嗎?為何花費(fèi)這么長(zhǎng)時(shí)間?
堆實(shí)現(xiàn)的注意事項(xiàng)
傳統(tǒng)上,操作系統(tǒng)和運(yùn)行時(shí)庫(kù)是與堆的實(shí)現(xiàn)共存的。在一個(gè)進(jìn)程的開(kāi)始,操作系統(tǒng)創(chuàng)建一個(gè)默認(rèn)堆,叫做“進(jìn)程堆”。如果沒(méi)有其他堆可使用,則塊的分配使用“進(jìn)程堆”。語(yǔ)言運(yùn)行時(shí)也能在進(jìn)程內(nèi)創(chuàng)建單獨(dú)的堆。(例如,C 運(yùn)行時(shí)創(chuàng)建它自己的堆。)除這些專(zhuān)用的堆外,應(yīng)用程序或許多已載入的動(dòng)態(tài)鏈接庫(kù) (DLL) 之一可以創(chuàng)建和使用單獨(dú)的堆。Win32 提供一整套 API 來(lái)創(chuàng)建和使用私有堆。有關(guān)堆函數(shù)(英文)的詳盡指導(dǎo),請(qǐng)參見(jiàn) MSDN。
當(dāng)應(yīng)用程序或 DLL 創(chuàng)建私有堆時(shí),這些堆存在于進(jìn)程空間,并且在進(jìn)程內(nèi)是可訪問(wèn)的。從給定堆分配的數(shù)據(jù)將在同一個(gè)堆上釋放。(不能從一個(gè)堆分配而在另一個(gè)堆釋放。)
在所有虛擬內(nèi)存系統(tǒng)中,堆駐留在操作系統(tǒng)的“虛擬內(nèi)存管理器”的頂部。語(yǔ)言運(yùn)行時(shí)堆也駐留在虛擬內(nèi)存頂部。某些情況下,這些堆是操作系統(tǒng)堆中的層,而語(yǔ)言運(yùn)行時(shí)堆則通過(guò)大塊的分配來(lái)執(zhí)行自己的內(nèi)存管理。不使用操作系統(tǒng)堆,而使用虛擬內(nèi)存函數(shù)更利于堆的分配和塊的使用。
典型的堆實(shí)現(xiàn)由前、后端分配程序組成。前端分配程序維持固定大小塊的空閑列表。對(duì)于一次分配調(diào)用,堆嘗試從前端列表找到一個(gè)自由塊。如果失敗,堆被迫從后端(保留和提交虛擬內(nèi)存)分配一個(gè)大塊來(lái)滿(mǎn)足請(qǐng)求。通用的實(shí)現(xiàn)有每塊分配的開(kāi)銷(xiāo),這將耗費(fèi)執(zhí)行周期,也減少了可使用的存儲(chǔ)空間。
Knowledge Base 文章 Q10758,“用 calloc() 和 malloc() 管理內(nèi)存” (搜索文章編號(hào)), 包含了有關(guān)這些主題的更多背景知識(shí)。另外,有關(guān)堆實(shí)現(xiàn)和設(shè)計(jì)的詳細(xì)討論也可在下列著作中找到:“Dynamic Storage Allocation: A Survey and Critical Review”,作者 Paul R. Wilson、Mark S. Johnstone、Michael Neely 和 David Boles;“International Workshop on Memory Management”, 作者 Kinross, Scotland, UK, 1995 年 9 月( http://www.cs.utexas.edu/users/oops/papers.html)(英文)。
http://www.cs.utexas.edu/users/oops/papers.html)(英文)。
Windows NT 的實(shí)現(xiàn)(Windows NT 版本 4.0 和更新版本) 使用了 127 個(gè)大小從 8 到 1,024 字節(jié)的 8 字節(jié)對(duì)齊塊空閑列表和一個(gè)“大塊”列表。“大塊”列表(空閑列表[0]) 保存大于 1,024 字節(jié)的塊。空閑列表容納了用雙向鏈表鏈接在一起的對(duì)象。默認(rèn)情況下,“進(jìn)程堆”執(zhí)行收集操作。(收集是將相鄰空閑塊合并成一個(gè)大塊的操作。)收集耗費(fèi)了額外的周期,但減少了堆塊的內(nèi)部碎片。
單一全局鎖保護(hù)堆,防止多線程式的使用。(請(qǐng)參見(jiàn)“Server Performance and Scalability Killers”中的第一個(gè)注意事項(xiàng), George Reilly 所著,在 “MSDN Online Web Workshop”上(站點(diǎn):http://msdn.microsoft.com/workshop/server/iis/tencom.asp(英文)。)單一全局鎖本質(zhì)上是用來(lái)保護(hù)堆數(shù)據(jù)結(jié)構(gòu),防止跨多線程的隨機(jī)存取。若堆操作太頻繁,單一全局鎖會(huì)對(duì)性能有不利的影響。
什么是常見(jiàn)的堆性能問(wèn)題?
以下是您使用堆時(shí)會(huì)遇到的最常見(jiàn)問(wèn)題:
分配操作造成的速度減慢。光分配就耗費(fèi)很長(zhǎng)時(shí)間。最可能導(dǎo)致運(yùn)行速度減慢原因是空閑列表沒(méi)有塊,所以運(yùn)行時(shí)分配程序代碼會(huì)耗費(fèi)周期尋找較大的空閑塊,或從后端分配程序分配新塊。
釋放操作造成的速度減慢。釋放操作耗費(fèi)較多周期,主要是啟用了收集操作。收集期間,每個(gè)釋放操作“查找”它的相鄰塊,取出它們并構(gòu)造成較大塊,然后再把此較大塊插入空閑列表。在查找期間,內(nèi)存可能會(huì)隨機(jī)碰到,從而導(dǎo)致高速緩存不能命中,性能降低。
堆競(jìng)爭(zhēng)造成的速度減慢。當(dāng)兩個(gè)或多個(gè)線程同時(shí)訪問(wèn)數(shù)據(jù),而且一個(gè)線程繼續(xù)進(jìn)行之前必須等待另一個(gè)線程完成時(shí)就發(fā)生競(jìng)爭(zhēng)。競(jìng)爭(zhēng)總是導(dǎo)致麻煩;這也是目前多處理器系統(tǒng)遇到的最大問(wèn)題。當(dāng)大量使用內(nèi)存塊的應(yīng)用程序或 DLL 以多線程方式運(yùn)行(或運(yùn)行于多處理器系統(tǒng)上)時(shí)將導(dǎo)致速度減慢。單一鎖定的使用—常用的解決方案—意味著使用堆的所有操作是序列化的。當(dāng)?shù)却i定時(shí)序列化會(huì)引起線程切換上下文。可以想象交叉路口閃爍的紅燈處走走停停導(dǎo)致的速度減慢。
競(jìng)爭(zhēng)通常會(huì)導(dǎo)致線程和進(jìn)程的上下文切換。上下文切換的開(kāi)銷(xiāo)是很大的,但開(kāi)銷(xiāo)更大的是數(shù)據(jù)從處理器高速緩存中丟失,以及后來(lái)線程復(fù)活時(shí)的數(shù)據(jù)重建。
堆破壞造成的速度減慢。造成堆破壞的原因是應(yīng)用程序?qū)Χ褖K的不正確使用。通常情形包括釋放已釋放的堆塊或使用已釋放的堆塊,以及塊的越界重寫(xiě)等明顯問(wèn)題。(破壞不在本文討論范圍之內(nèi)。有關(guān)內(nèi)存重寫(xiě)和泄漏等其他細(xì)節(jié),請(qǐng)參見(jiàn) Microsoft Visual C++(R) 調(diào)試文檔 。)
頻繁的分配和重分配造成的速度減慢。這是使用腳本語(yǔ)言時(shí)非常普遍的現(xiàn)象。如字符串被反復(fù)分配,隨重分配增長(zhǎng)和釋放。不要這樣做,如果可能,盡量分配大字符串和使用緩沖區(qū)。另一種方法就是盡量少用連接操作。
競(jìng)爭(zhēng)是在分配和釋放操作中導(dǎo)致速度減慢的問(wèn)題。理想情況下,希望使用沒(méi)有競(jìng)爭(zhēng)和快速分配/釋放的堆。可惜,現(xiàn)在還沒(méi)有這樣的通用堆,也許將來(lái)會(huì)有。
在所有的服務(wù)器系統(tǒng)中(如 IIS、MSProxy、DatabaseStacks、網(wǎng)絡(luò)服務(wù)器、 Exchange 和其他), 堆鎖定實(shí)在是個(gè)大瓶頸。處理器數(shù)越多,競(jìng)爭(zhēng)就越會(huì)惡化。
盡量減少堆的使用
現(xiàn)在您明白使用堆時(shí)存在的問(wèn)題了,難道您不想擁有能解決這些問(wèn)題的超級(jí)魔棒嗎?我可希望有。但沒(méi)有魔法能使堆運(yùn)行加快—因此不要期望在產(chǎn)品出貨之前的最后一星期能夠大為改觀。如果提前規(guī)劃堆策略,情況將會(huì)大大好轉(zhuǎn)。調(diào)整使用堆的方法,減少對(duì)堆的操作是提高性能的良方。
如何減少使用堆操作?通過(guò)利用數(shù)據(jù)結(jié)構(gòu)內(nèi)的位置可減少堆操作的次數(shù)。請(qǐng)考慮下列實(shí)例:
struct ObjectA {
// objectA 的數(shù)據(jù)
}
struct ObjectB {
// objectB 的數(shù)據(jù)
}
// 同時(shí)使用 objectA 和 objectB
//
// 使用指針
//
struct ObjectB {
struct ObjectA * pObjA;
// objectB 的數(shù)據(jù)
}
//
// 使用嵌入
//
struct ObjectB {
struct ObjectA pObjA;
// objectB 的數(shù)據(jù)
}
//
// 集合 – 在另一對(duì)象內(nèi)使用 objectA 和 objectB
//
struct ObjectX {
struct ObjectA objA;
struct ObjectB objB;
}
避免使用指針關(guān)聯(lián)兩個(gè)數(shù)據(jù)結(jié)構(gòu)。如果使用指針關(guān)聯(lián)兩個(gè)數(shù)據(jù)結(jié)構(gòu),前面實(shí)例中的對(duì)象 A 和 B 將被分別分配和釋放。這會(huì)增加額外開(kāi)銷(xiāo)—我們要避免這種做法。
把帶指針的子對(duì)象嵌入父對(duì)象。當(dāng)對(duì)象中有指針時(shí),則意味著對(duì)象中有動(dòng)態(tài)元素(百分之八十)和沒(méi)有引用的新位置。嵌入增加了位置從而減少了進(jìn)一步分配/釋放的需求。這將提高應(yīng)用程序的性能。
合并小對(duì)象形成大對(duì)象(聚合)。聚合減少分配和釋放的塊的數(shù)量。如果有幾個(gè)開(kāi)發(fā)者,各自開(kāi)發(fā)設(shè)計(jì)的不同部分,則最終會(huì)有許多小對(duì)象需要合并。集成的挑戰(zhàn)就是要找到正確的聚合邊界。
內(nèi)聯(lián)緩沖區(qū)能夠滿(mǎn)足百分之八十的需要(aka 80-20 規(guī)則)。個(gè)別情況下,需要內(nèi)存緩沖區(qū)來(lái)保存字符串/二進(jìn)制數(shù)據(jù),但事先不知道總字節(jié)數(shù)。估計(jì)并內(nèi)聯(lián)一個(gè)大小能滿(mǎn)足百分之八十需要的緩沖區(qū)。對(duì)剩余的百分之二十,可以分配一個(gè)新的緩沖區(qū)和指向這個(gè)緩沖區(qū)的指針。這樣,就減少分配和釋放調(diào)用并增加數(shù)據(jù)的位置空間,從根本上提高代碼的性能。
在塊中分配對(duì)象(塊化)。塊化是以組的方式一次分配多個(gè)對(duì)象的方法。如果對(duì)列表的項(xiàng)連續(xù)跟蹤,例如對(duì)一個(gè) {名稱(chēng),值} 對(duì)的列表,有兩種選擇:選擇一是為每一個(gè)“名稱(chēng)-值”對(duì)分配一個(gè)節(jié)點(diǎn);選擇二是分配一個(gè)能容納(如五個(gè))“名稱(chēng)-值”對(duì)的結(jié)構(gòu)。例如,一般情況下,如果存儲(chǔ)四對(duì),就可減少節(jié)點(diǎn)的數(shù)量,如果需要額外的空間數(shù)量,則使用附加的鏈表指針。
塊化是友好的處理器高速緩存,特別是對(duì)于 L1-高速緩存,因?yàn)樗峁┝嗽黾拥奈恢?nbsp;—不用說(shuō)對(duì)于塊分配,很多數(shù)據(jù)塊會(huì)在同一個(gè)虛擬頁(yè)中。
正確使用 _amblksiz。C 運(yùn)行時(shí) (CRT) 有它的自定義前端分配程序,該分配程序從后端(Win32 堆)分配大小為 _amblksiz 的塊。將 _amblksiz 設(shè)置為較高的值能潛在地減少對(duì)后端的調(diào)用次數(shù)。這只對(duì)廣泛使用 CRT 的程序適用。
使用上述技術(shù)將獲得的好處會(huì)因?qū)ο箢?lèi)型、大小及工作量而有所不同。但總能在性能和可升縮性方面有所收獲。另一方面,代碼會(huì)有點(diǎn)特殊,但如果經(jīng)過(guò)深思熟慮,代碼還是很容易管理的。
其他提高性能的技術(shù)
下面是一些提高速度的技術(shù):
使用 Windows NT5 堆
由于幾個(gè)同事的努力和辛勤工作,1998 年初 Microsoft Windows(R) 2000 中有了幾個(gè)重大改進(jìn):
改進(jìn)了堆代碼內(nèi)的鎖定。堆代碼對(duì)每堆一個(gè)鎖。全局鎖保護(hù)堆數(shù)據(jù)結(jié)構(gòu),防止多線程式的使用。但不幸的是,在高通信量的情況下,堆仍受困于全局鎖,導(dǎo)致高競(jìng)爭(zhēng)和低性能。Windows 2000 中,鎖內(nèi)代碼的臨界區(qū)將競(jìng)爭(zhēng)的可能性減到最小,從而提高了可伸縮性。
使用 “Lookaside”列表。堆數(shù)據(jù)結(jié)構(gòu)對(duì)塊的所有空閑項(xiàng)使用了大小在 8 到 1,024 字節(jié)(以 8-字節(jié)遞增)的快速高速緩存。快速高速緩存最初保護(hù)在全局鎖內(nèi)。現(xiàn)在,使用 lookaside 列表來(lái)訪問(wèn)這些快速高速緩存空閑列表。這些列表不要求鎖定,而是使用 64 位的互鎖操作,因此提高了性能。
內(nèi)部數(shù)據(jù)結(jié)構(gòu)算法也得到改進(jìn)。
這些改進(jìn)避免了對(duì)分配高速緩存的需求,但不排除其他的優(yōu)化。使用 Windows NT5 堆評(píng)估您的代碼;它對(duì)小于 1,024 字節(jié) (1 KB) 的塊(來(lái)自前端分配程序的塊)是最佳的。GlobalAlloc() 和 LocalAlloc() 建立在同一堆上,是存取每個(gè)進(jìn)程堆的通用機(jī)制。如果希望獲得高的局部性能,則使用 Heap(R) API 來(lái)存取每個(gè)進(jìn)程堆,或?yàn)榉峙洳僮鲃?chuàng)建自己的堆。如果需要對(duì)大塊操作,也可以直接使用 VirtualAlloc() / VirtualFree() 操作。
上述改進(jìn)已在 Windows 2000 beta 2 和 Windows NT 4.0 SP4 中使用。改進(jìn)后,堆鎖的競(jìng)爭(zhēng)率顯著降低。這使所有 Win32 堆的直接用戶(hù)受益。CRT 堆建立于 Win32 堆的頂部,但它使用自己的小塊堆,因而不能從 Windows NT 改進(jìn)中受益。(Visual C++ 版本 6.0 也有改進(jìn)的堆分配程序。)
使用分配高速緩存
分配高速緩存允許高速緩存分配的塊,以便將來(lái)重用。這能夠減少對(duì)進(jìn)程堆(或全局堆)的分配/釋放調(diào)用的次數(shù),也允許最大限度的重用曾經(jīng)分配的塊。另外,分配高速緩存允許收集統(tǒng)計(jì)信息,以便較好地理解對(duì)象在較高層次上的使用。
典型地,自定義堆分配程序在進(jìn)程堆的頂部實(shí)現(xiàn)。自定義堆分配程序與系統(tǒng)堆的行為很相似。主要的差別是它在進(jìn)程堆的頂部為分配的對(duì)象提供高速緩存。高速緩存設(shè)計(jì)成一套固定大小(如 32 字節(jié)、64 字節(jié)、128 字節(jié)等)。這一個(gè)很好的策略,但這種自定義堆分配程序丟失與分配和釋放的對(duì)象相關(guān)的“語(yǔ)義信息”。
與自定義堆分配程序相反,“分配高速緩存”作為每類(lèi)分配高速緩存來(lái)實(shí)現(xiàn)。除能夠提供自定義堆分配程序的所有好處之外,它們還能夠保留大量語(yǔ)義信息。每個(gè)分配高速緩存處理程序與一個(gè)目標(biāo)二進(jìn)制對(duì)象關(guān)聯(lián)。它能夠使用一套參數(shù)進(jìn)行初始化,這些參數(shù)表示并發(fā)級(jí)別、對(duì)象大小和保持在空閑列表中的元素的數(shù)量等。分配高速緩存處理程序?qū)ο缶S持自己的私有空閑實(shí)體池(不超過(guò)指定的閥值)并使用私有保護(hù)鎖。合在一起,分配高速緩存和私有鎖減少了與主系統(tǒng)堆的通信量,因而提供了增加的并發(fā)、最大限度的重用和較高的可伸縮性。
需要使用清理程序來(lái)定期檢查所有分配高速緩存處理程序的活動(dòng)情況并回收未用的資源。如果發(fā)現(xiàn)沒(méi)有活動(dòng),將釋放分配對(duì)象的池,從而提高性能。
可以審核每個(gè)分配/釋放活動(dòng)。第一級(jí)信息包括對(duì)象、分配和釋放調(diào)用的總數(shù)。通過(guò)查看它們的統(tǒng)計(jì)信息可以得出各個(gè)對(duì)象之間的語(yǔ)義關(guān)系。利用以上介紹的許多技術(shù)之一,這種關(guān)系可以用來(lái)減少內(nèi)存分配。
分配高速緩存也起到了調(diào)試助手的作用,幫助您跟蹤沒(méi)有完全清除的對(duì)象數(shù)量。通過(guò)查看動(dòng)態(tài)堆棧返回蹤跡和除沒(méi)有清除的對(duì)象之外的簽名,甚至能夠找到確切的失敗的調(diào)用者。
MP 堆
MP 堆是對(duì)多處理器友好的分布式分配的程序包,在 Win32 SDK(Windows NT 4.0 和更新版本)中可以得到。最初由 JVert 實(shí)現(xiàn),此處堆抽象建立在 Win32 堆程序包的頂部。MP 堆創(chuàng)建多個(gè) Win32 堆,并試圖將分配調(diào)用分布到不同堆,以減少在所有單一鎖上的競(jìng)爭(zhēng)。
本程序包是好的步驟 —一種改進(jìn)的 MP-友好的自定義堆分配程序。但是,它不提供語(yǔ)義信息和缺乏統(tǒng)計(jì)功能。通常將 MP 堆作為 SDK 庫(kù)來(lái)使用。如果使用這個(gè) SDK 創(chuàng)建可重用組件,您將大大受益。但是,如果在每個(gè) DLL 中建立這個(gè) SDK 庫(kù),將增加工作設(shè)置。
重新思考算法和數(shù)據(jù)結(jié)構(gòu)
要在多處理器機(jī)器上伸縮,則算法、實(shí)現(xiàn)、數(shù)據(jù)結(jié)構(gòu)和硬件必須動(dòng)態(tài)伸縮。請(qǐng)看最經(jīng)常分配和釋放的數(shù)據(jù)結(jié)構(gòu)。試問(wèn),“我能用不同的數(shù)據(jù)結(jié)構(gòu)完成此工作嗎?”例如,如果在應(yīng)用程序初始化時(shí)加載了只讀項(xiàng)的列表,這個(gè)列表不必是線性鏈接的列表。如果是動(dòng)態(tài)分配的數(shù)組就非常好。動(dòng)態(tài)分配的數(shù)組將減少內(nèi)存中的堆塊和碎片,從而增強(qiáng)性能。
減少需要的小對(duì)象的數(shù)量減少堆分配程序的負(fù)載。例如,我們?cè)诜?wù)器的關(guān)鍵處理路徑上使用五個(gè)不同的對(duì)象,每個(gè)對(duì)象單獨(dú)分配和釋放。一起高速緩存這些對(duì)象,把堆調(diào)用從五個(gè)減少到一個(gè),顯著減少了堆的負(fù)載,特別當(dāng)每秒鐘處理 1,000 個(gè)以上的請(qǐng)求時(shí)。
如果大量使用“Automation”結(jié)構(gòu),請(qǐng)考慮從主線代碼中刪除“Automation BSTR”,或至少避免重復(fù)的 BSTR 操作。(BSTR 連接導(dǎo)致過(guò)多的重分配和分配/釋放操作。)
摘要
對(duì)所有平臺(tái)往往都存在堆實(shí)現(xiàn),因此有巨大的開(kāi)銷(xiāo)。每個(gè)單獨(dú)代碼都有特定的要求,但設(shè)計(jì)能采用本文討論的基本理論來(lái)減少堆之間的相互作用。
評(píng)價(jià)您的代碼中堆的使用。
改進(jìn)您的代碼,以使用較少的堆調(diào)用:分析關(guān)鍵路徑和固定數(shù)據(jù)結(jié)構(gòu)。
在實(shí)現(xiàn)自定義的包裝程序之前使用量化堆調(diào)用成本的方法。
如果對(duì)性能不滿(mǎn)意,請(qǐng)要求 OS 組改進(jìn)堆。更多這類(lèi)請(qǐng)求意味著對(duì)改進(jìn)堆的更多關(guān)注。
要求 C 運(yùn)行時(shí)組針對(duì) OS 所提供的堆制作小巧的分配包裝程序。隨著 OS 堆的改進(jìn),C 運(yùn)行時(shí)堆調(diào)用的成本將減小。
操作系統(tǒng)(Windows NT 家族)正在不斷改進(jìn)堆。請(qǐng)隨時(shí)關(guān)注和利用這些改進(jìn)。
Murali Krishnan 是 Internet Information Server (IIS) 組的首席軟件設(shè)計(jì)工程師。從 1.0 版本開(kāi)始他就設(shè)計(jì) IIS,并成功發(fā)行了 1.0 版本到 4.0 版本。Murali 組織并領(lǐng)導(dǎo) IIS 性能組三年 (1995-1998), 從一開(kāi)始就影響 IIS 性能。他擁有威斯康星州 Madison 大學(xué)的 M.S.和印度 Anna 大學(xué)的 B.S.。工作之外,他喜歡閱讀、打排球和家庭烹飪。
http://community.csdn.net/Expert/FAQ/FAQ_Index.asp?id=172835
我在學(xué)習(xí)對(duì)象的生存方式的時(shí)候見(jiàn)到一種是在堆棧(stack)之中,如下
CObject object;
還有一種是在堆(heap)中 如下
CObject* pobject=new CObject();
請(qǐng)問(wèn)
(1)這兩種方式有什么區(qū)別?
(2)堆棧與堆有什么區(qū)別??
---------------------------------------------------------------
1) about stack, system will allocate memory to the instance of object automatically, and to the
heap, you must allocate memory to the instance of object with new or malloc manually.
2) when function ends, system will automatically free the memory area of stack, but to the
heap, you must free the memory area manually with free or delete, else it will result in memory
leak.
3)棧內(nèi)存分配運(yùn)算內(nèi)置于處理器的指令集中,效率很高,但是分配的內(nèi)存容量有限。
4)堆上分配的內(nèi)存可以有我們自己決定,使用非常靈活。
---------------------------------------------------------------
先感謝木的{moond},要不是一次提供了那么多畫(huà)原型圖的工具,我現(xiàn)在還在Word和Visio里面打轉(zhuǎn)呢。
這些軟件能試用的我差不多都用了一下,其中覺(jué)得Axure的RP Pro 4挺好的,功能包括站點(diǎn)地圖、流程設(shè)計(jì)、頁(yè)面框架設(shè)計(jì)、簡(jiǎn)單交互設(shè)計(jì)等,可以生成HTML、Word等格式。

RP操作比用Dreamweaver簡(jiǎn)單多了,圖片、文字、輸入框等等所有組件全是可視化操作,可以很方便的實(shí)現(xiàn)網(wǎng)站交互內(nèi)容的原型設(shè)計(jì),可將以前死板的頁(yè)面版式全部替換為有點(diǎn)擊、鏈接效果的網(wǎng)頁(yè),nice~
同時(shí)可以為網(wǎng)站設(shè)計(jì)提供AJAX式的交互處理,RP提供一種動(dòng)態(tài)層的組件,在同一頁(yè)設(shè)定不同狀態(tài)的效果,然后用鏈接、按鈕等觸發(fā)即可產(chǎn)生動(dòng)態(tài)效果,這樣網(wǎng)站設(shè)計(jì)就變得更加生動(dòng),意圖也就更加直觀。
可惜,這么好的軟件只能試用30天,哪位兄臺(tái)要是有解決方法一定要通知我,這里先謝了~
以下對(duì)RP5的新特性做了下簡(jiǎn)單翻譯:
Axure RP Pro 5.0增加了眾多新特性,并且著重增強(qiáng)了設(shè)計(jì)師間的協(xié)作、交互功能和更多的定制功能,生成也變的更快。
新功能包括:
1. 共享工程
1.1 可以在網(wǎng)絡(luò)驅(qū)動(dòng)器上創(chuàng)建共享工程,而不必非安裝在服務(wù)器上
1.2 管理和便捷頁(yè)面只需要通過(guò)簡(jiǎn)單的 check in / check out 即可
1.3 維護(hù)和瀏覽歷史版本
1.4 更多介紹
2. 交互功能的增強(qiáng)
2.1 OnFocus 和 OnLostFocus 事件 (更多)
2.2 使用和禁止Widgets行為
2.3 模仿在圖片上的錨點(diǎn)/熱區(qū)行為 (更多)
2.4 移動(dòng)動(dòng)態(tài)層(Dynamic Panels)行為 (更多)
2.5 在其他行為運(yùn)行之前暫停當(dāng)前行為
2.6 頁(yè)面間多達(dá)25個(gè)變量的儲(chǔ)存
3. 規(guī)范的增強(qiáng)
3.1 可以更快的把演示生成為Microsoft Word 2007格式(使用Microsoft Office兼容包可與Microsoft Word 2000+兼容)
3.2 有1欄和2欄布局的選項(xiàng)
3.3 可以更簡(jiǎn)單的定制Word模板
3.4 有更多新選項(xiàng)去配置規(guī)范內(nèi)容
4. 更多增強(qiáng)
4.1 優(yōu)化Tab交互
4.2 可以選擇與主窗體分離(比如Sitemap和Widgets)
4.3 有更好的保存機(jī)制來(lái)處理關(guān)閉和重開(kāi)一個(gè)文件
4.4 帶有梯度和透明設(shè)置的顏色工具
4.5 打印設(shè)置是被保存的
查看原文
同時(shí)提示一下:如果之前裝過(guò)RP4,并且有l(wèi)icense的話,RP5可以直接使用,
是作為免費(fèi)升級(jí)的,當(dāng)然,你也可以只當(dāng)下來(lái)看看,有30天試用
=======================================================================
互聯(lián)網(wǎng)行業(yè)產(chǎn)品經(jīng)理的一項(xiàng)重要工作,就是進(jìn)行產(chǎn)品原型設(shè)計(jì)(Prototype Design)。而產(chǎn)品原型設(shè)計(jì)最基礎(chǔ)的工作,就是結(jié)合批注、大量的說(shuō)明以及流程圖畫(huà)框架圖wireframe,將自己的產(chǎn)品原型完整而準(zhǔn)確的表述給UI、UE、程序工程師,市場(chǎng)人員,并通過(guò)溝通會(huì)議,反復(fù)修改prototype 直至最終確認(rèn),開(kāi)始投入執(zhí)行。
進(jìn)行產(chǎn)品原型設(shè)計(jì)的軟件工具也有很多種,我寫(xiě)的這個(gè)教程所介紹的Axure RP,是taobao、dangdang等國(guó)內(nèi)大型網(wǎng)絡(luò)公司的團(tuán)隊(duì)在推廣使用的原型設(shè)計(jì)軟件。同時(shí),此軟件也在產(chǎn)品經(jīng)理圈子中廣為流傳。之所以Axure RP得到了大家的認(rèn)同和推廣,正是因?yàn)槠浜?jiǎn)便的操作和使用,符合了產(chǎn)品經(jīng)理、交互設(shè)計(jì)師們的需求。
在正式談Axure RP之前,我們先來(lái)看看做產(chǎn)品原型設(shè)計(jì),現(xiàn)在大致有哪些工具可以使用,而他們的利弊何在。
紙筆:簡(jiǎn)單易得,上手難度為零。有力于瞬間創(chuàng)意的產(chǎn)生與記錄,有力于對(duì)文檔即時(shí)的討論與修改。但是保真度不高,難以表述頁(yè)面流程,更難以表述交互信息與程序需求細(xì)節(jié)。
Word:上手難度普通。可以畫(huà)wireframe,能夠畫(huà)頁(yè)面流程,能夠使用批注與文字說(shuō)明。但是對(duì)交互表達(dá)不好,也不利于演示。
PPT:上手難度普通。易于畫(huà)框架圖,易于做批注,也可以表達(dá)交互流程,也擅長(zhǎng)演示。但是不利于大篇幅的文檔表達(dá)。
Visio:功能相對(duì)比較復(fù)雜。善于畫(huà)流程圖,框架圖。不利于批注與大篇幅的文字說(shuō)明。同樣不利于交互的表達(dá)與演示。
Photshop/fireworks:操作難度相對(duì)較大,易于畫(huà)框架圖、流程圖。不利于表達(dá)交互設(shè)計(jì),不擅長(zhǎng)文字說(shuō)明與批注。
Dreamweave:操作難度大,需要基礎(chǔ)的html知識(shí)。易于畫(huà)框架圖、流程圖、表達(dá)交互設(shè)計(jì)。不擅長(zhǎng)文字說(shuō)明與批注。
以上這些工具,都是產(chǎn)品經(jīng)理經(jīng)常會(huì)使用到的,但是從根本上來(lái)說(shuō),這些工具都不是做prototype design的專(zhuān)門(mén)利器,需要根據(jù)產(chǎn)品開(kāi)發(fā)不同的目的,不同的開(kāi)發(fā)階段,選擇不同的工具搭配使用,才能達(dá)到表達(dá)、溝通的目的。
比如使用紙筆,更適合在產(chǎn)品創(chuàng)意階段使用,可以快速記錄閃電般的思路和靈感;也可以在即時(shí)討論溝通時(shí)使用,通過(guò)圖形快速表達(dá)自己的產(chǎn)品思路,及時(shí)的畫(huà)出來(lái),是再好不過(guò)的方法。而word則適合在用文字詳細(xì)表達(dá)產(chǎn)品,對(duì)產(chǎn)品進(jìn)行細(xì)節(jié)說(shuō)明時(shí)使用,圖片結(jié)合文字的排版,是word最擅長(zhǎng)的工作。而ppt自然是演示時(shí)更好。visio則可以適用于各種流程圖、關(guān)系圖的表達(dá),更可通過(guò)畫(huà)use case 獲取用戶(hù)需求。PS/FW是圖片處理的工具,DW則是所見(jiàn)即所得的網(wǎng)頁(yè)開(kāi)發(fā)軟件,這些是設(shè)計(jì)師的看家本領(lǐng),對(duì)于普通的產(chǎn)品經(jīng)理來(lái)說(shuō),需要耗費(fèi)太多的精力去掌握。
其實(shí)每件工具,每個(gè)軟件,在創(chuàng)造它的初期,軟件設(shè)計(jì)師們都給它賦予了性格、氣質(zhì)。因?yàn)槊總€(gè)工具的產(chǎn)生,都是為了滿(mǎn)足人類(lèi)的某一方面需求。比如鋤頭是鋤土的,起子是起螺絲的,電熨斗是燙衣服的。但是不同的工具都有自己的工作領(lǐng)域,在其他領(lǐng)域它并不擅長(zhǎng)。而以上的軟件在創(chuàng)造的初期,并非為了幫助產(chǎn)品經(jīng)理、ue完成產(chǎn)品原型設(shè)計(jì),因此他們都不能在prototype design 這件工作上得心應(yīng)手。而Axure RP正是在互聯(lián)網(wǎng)產(chǎn)品大張其道的前提下,為滿(mǎn)足prototype design創(chuàng)建的需求,應(yīng)運(yùn)而生。

Axure RP 能幫助網(wǎng)站需求設(shè)計(jì)者,快捷而簡(jiǎn)便的創(chuàng)建 基于目錄組織的原型文檔、功能說(shuō)明、交互界面以及帶注釋的wireframe網(wǎng)頁(yè),并可自動(dòng)生成用于演示的網(wǎng)頁(yè)文件和word文檔,以提供演示與開(kāi)發(fā)。
沒(méi)錯(cuò)!Axure RP 的特點(diǎn)是:
- 快速創(chuàng)建帶注釋的wireframe文件,并可根據(jù)所設(shè)置的時(shí)間周期,軟件自動(dòng)保存文檔,確保文件安全。
?
- 在不寫(xiě)任何一條html與javascript語(yǔ)句的情況下,通過(guò)創(chuàng)建的文檔以及相關(guān)條件和注釋?zhuān)绘I生成html prototype演示。
?
- 根據(jù)設(shè)計(jì)稿,一鍵生成一致而專(zhuān)業(yè)的word版本的原型設(shè)計(jì)文檔。
說(shuō)到這里相信很多人已經(jīng)激起了興趣,但是在開(kāi)始學(xué)習(xí)之前,我認(rèn)為我們還是有必要先了解一下軟件短短的歷史,創(chuàng)造這一軟件的公司-Axure Software Solutions, Inc.該公司創(chuàng)建于2002年五月,Axure RP是這一軟件公司的旗艦產(chǎn)品,2003年一月Axure RP第一版本上線發(fā)表,至今已經(jīng)正式發(fā)行到了第四個(gè)版本,而我提筆寫(xiě)到這里的時(shí)候,Axure 5.0版本beta版本已經(jīng)正式提供下載試用,雖然我已經(jīng)下載使用,但是我想,寫(xiě)教程還是應(yīng)該先從穩(wěn)定的4.6版說(shuō)起,至于5.0版,我們可以伴隨著軟件一起成長(zhǎng)。
接下來(lái)我會(huì)結(jié)合圖片,分幾個(gè)步驟分享我對(duì)Axure的認(rèn)識(shí),
一、 界面與功能
二、 工具欄
三、 站點(diǎn)地圖
四、 組件與使用方法
五、 復(fù)用模板與使用
六、 交互功能與注釋
七、 實(shí)例
當(dāng)然,在書(shū)寫(xiě)的過(guò)程中我會(huì)根據(jù)具體的情況再進(jìn)行調(diào)整,盡量做到圖文并茂,易于理解。寫(xiě)這個(gè)教程的目的,一方面為自己熟悉與更加理解Axure,另一方面也鞭策自己完善自己的blog網(wǎng)站www.2tan.net,同時(shí)也希望以自己的綿薄之力,為希望學(xué)習(xí)Axure的朋友分享一點(diǎn)經(jīng)驗(yàn)。由于這是我第一次嘗試寫(xiě)教程,難免會(huì)出現(xiàn)偏頗,也希望朋友們能夠不吝賜教,共同進(jìn)步。
另,為e文好的朋友附上自學(xué)Axure RP的幾個(gè)途徑:
1、 打開(kāi)軟件,按F1調(diào)取幫助文檔,對(duì)照文檔學(xué)習(xí)。
2、 登錄http://www.axure.com/au-home.aspx 查看flash視頻學(xué)習(xí)。
3、 登錄 Axure 博客 http://axure.com/cs/blogs/Default.aspx,了解軟件最新信息。
4、 登錄討論組http://axure.com/cs/forums/Default.aspx,參與討論。
并提供Axure RP pro 4.6版本的下載
http://www.2tan.net/LoadMod.asp?plugins=downloadForPJBlog
由于放存軟件的網(wǎng)絡(luò)硬盤(pán)在下載數(shù)量不多的情況下可能會(huì)刪除文件,如遇到死鏈接,可留言給我,我將重新上傳:)
(軟件僅供學(xué)習(xí)使用,反對(duì)商業(yè)用途 -_-!!!)
Name:3ddown
Serial:FiCGEezgdGoYILo8U/2MFyCWj0jZoJc/sziRRj2/ENvtEq+7w1RH97k5MWctqVHA