#
31、動態空間的釋放(P119)
動態空間的釋放使用delete [] pia;(其中pia為指向動態分配的數組的第一個元素的指針)。在關鍵字delete和指針之間的方括號對是必不可少的:它告訴編譯器該指針指向的是自由存儲區中的數組,而并非單個對象。
如果遺漏了空方括號對,這是一個編譯器無法發現的錯誤,將導致程序在運行時出錯。
使用std::string后則會自動進行釋放,無需delete!
32、c_str返回的數組并不保證一定是有效的……
std::string st1("I am a string object!");
//error C2440: “初始化”: 無法從“const char *”轉換為“char *”
//char *str = st1.c_str();
const char *cstr = st1.c_str();
std::cout<<cstr<<std::endl;
c_str返回的數組并不保證一定是有效的,接下來對st1的操作有可能會改變st1的值,使剛才返回的數組失效。如程序需要持續訪問該數據,則應該復制c_str函數返回的數組。
33、指向函數的指針
詳見《指向函數的指針的一點理解》
34、容器初始化
在大多數的程序中,使用默認構造函數能達到最佳運行時性能,并且使容器更容易使用。
35、容器頭文件
#include <vector>
#include <list>
#include <deque> //雙端隊列“double-ended queue”,發音為“deck”
標準庫定義了以上三種順序容器類型。
36、容器的容器
必須用空格隔開兩個相鄰的>符號,以示這是兩個分開的符號,否則,系統會認為>>是單個符號,為右移操作符,并導致編譯時錯誤。
int m, n;
m = 5;
n = 3;
cout << "Print a line!" << endl;
vector<string> lines(n, " I_am_a_PC_! ");
for (vector<string>::iterator siter = lines.begin(); siter != lines.end(); ++siter) {
cout << *siter;
}
cout << endl;
cout << "Print a paragraph!" << endl;
vector<vector<string> > paragraph(m, lines);
for (vector<vector<string> >::iterator piter = paragraph.begin(); piter
!= paragraph.end(); ++piter) {
for (vector<string>::iterator siter = (*piter).begin(); siter
!= (*piter).end(); ++siter) {
cout << *siter << ends;
}
cout << endl;
}
37、迭代器范圍(P269)
C++定義的容器類型中,只有vector和deque容器提供下面兩種重要的運算集合:迭代器算術運算,以及使用除了==和!=之外的關系操作符來比較兩個迭代器(==和!=這兩種關系運算適用于所有容器)。
list容器的迭代器既不支持算術運算(減法或加法),也不支持關系運算(<=,<,>=,>)它只提供前置和后置的自增、自減以及相同(不等)運算。
38、容器元素都是副本
在容器中添加元素時,系統是將元素值復制到容器里的。類似地,使用一段元素初始化新容器時,新容器存放的是原始元素的副本。被復制的原始值與新容器中的元素各不相關,此后容器內元素值發生變化時,被復制的原值不會受到影響,反之亦然。
39、下標操作和.at(n)的區別
vector<string> svec; //empty vector;
cout << svec[0]; //run-time error:There are no elements in svec!
cout << svec.at(0); //throws out_of_range exception
40、容器的賦值(P283)
assign操作首先刪除容器中所有的元素,然后將其參數所指定的新元素插入到該容器中。與復制容器元素的構造函數一樣,如果兩個容器類型相同,其元素類型也相同,就可以使用賦值操作符(=)將一個容器賦值給另一個容器。如果在不同(或相同)類型的容器內,元素類型不相同但是相互兼容,則其賦值運算必須使用assign函數。例如,可通過assign操作實現將vector容器中一段char*類型的元素賦給string類型的list容器。
由于assign操作首先刪除容器中原來存儲的所有元素,因此,傳遞給assign函數的迭代器不能指向調用該函數的容器內的元素。
準確地講,本文所涉及的內容是C++中較難理解的,本文的目的不是在于將它們解釋清楚,因為這需要你循序漸進地做很多練習才可以。看下面一個例子:
int (*func(bool real))(int, int)
你覺得它的返回值是什么?
這里就涉及到了如何理解指向函數的指針的問題了。一些來自C++教材的建議是從里向外解讀這個表達式,這里所謂的里面就是func(bool real),那么剩下的部分就是所謂的返回值了?有點生硬吧。下面就讓我們循序漸進地看看如何理解更好?
為什么會對這個表達式的返回值產生疑問?
要解決問題通常需要找出問題所在,這里是基于這樣一種思維定勢,那就是我們通常習慣于這樣一種聲明變量的方式:
int a;
這里我們聲明a是一個int類型的變量。而對于返回值,我們通常也是采用類似的方式,如一個返回值為int類型的函數通常可以以下面的方式進行聲明:
int func([params]);
因此我們慣性地認為返回值就是最左側的一個類型名,雖然這通常是對的,但是針對上面的那個例子則顯得十分尷尬。
讓我們看看一個指向函數的指針的聲明式:
int (*pCompare)(int, int);
這個指針的名字就是pCompare,令人奇怪的是pCompare并不是在整個聲明式的最右邊,類型也肯定不是int,而是一個復雜的表達式。讓我們用typedef來聲明就會發現typedef的使用也不太一樣。
typedef int (*PF)(int, int);
我們發現跟慣用的typedef *** ???;的方式也截然不同,在上面這個typedef過后,整個表達式可以被簡化成:
PF pCompare;
現在我們似乎就一見如故了,現在的表達式看起來中規中矩,普通的聲明都是類型名加變量名完成聲明,而函數指針的聲明則是在一個表達式中一個固定的位置進行聲明。
int (* )(int, int);
在上文中劃線的部分即為聲明的部分,也就是這點不同讓我們逐漸迷失了方向。
現在讓我們寫一個返回指向函數的指針的函數,也就是返回值是PF的函數,這就像我們從返回int類型的變量到返回int類型值的函數一樣,因此使用以下方式即可:
PF func([params]);
現在讓我們擴展PF,將它還原,也就是把右側的func([params])部分移到那個橫線的位置上。現在我們就可以很輕松地理解本文開頭的那個函數,原來是返回值為int (*)(int, int)的函數
int (*func(bool real))(int, int)
以上劃線的部分也就是一個函數扣除返回值的部分。也就等價于
PF func(bool real)
至此你應該能夠分析更加復雜的表達式了。
下面的示例旨在幫助理解本文:
/*
* main.cc
*
* Created on: 2009-2-1
* Author: Volnet
*/
#include <stdlib.h>
#include <iostream>
using std::cout;
using std::endl;
int myCompare1(
int a, int b,
int (*Compare)(int, int));
int realCompare(int a, int b);
int fakeCompare(int a, int b);
typedef int (*PF)(int, int);
int myCompare2(
int a, int b,
PF Compare);
PF getAPointerFunc1(bool real);
int (*getAPointerFunc2(bool real))(int, int);
int main(void){
int typeDeclared;
typeDeclared = 1;
//PF pCompare;
int (*pCompare)(int, int);
if(pCompare == NULL)
cout<<"pCompare == NULL"<<endl;
else
{
cout<<"pCompare != NULL"<<" pComapre = "<<pCompare<<endl;
}
cout<<"Compare the pointer function."<<endl;
cout<<"The compare result is : "<<
myCompare1(6, 5, realCompare)<<endl;
cout<<"It's the same to invoke realCompare & *realCompare : "<<
myCompare1(6, 5, *realCompare)<<endl;
cout<<"Using the typedef to predigest definition : "<<
myCompare2(8, 7, realCompare)<<endl;
cout<<"Return a pointer from a function : "<<
myCompare2(10, 20, getAPointerFunc1(true))<<endl;
cout<<"Return a pointer from a function : "<<
myCompare2(20, 30, getAPointerFunc2(false))<<endl;
return EXIT_SUCCESS;
}
int myCompare1(
int a, int b,
int (*Compare)(int, int)){
return Compare(a, b);
}
int realCompare(int a, int b){
cout<<"The realCompare has be invoked."<<endl;
if(a == b)
return 0;
if(a < b)
return -1;
else
return 1;
}
int fakeCompare(int a, int b){
cout<<"The fackCompare has be invoked."<<endl;
return 200;
}
int myCompare2(
int a, int b,
PF Compare){
return Compare(a, b);
}
PF getAPointerFunc1(bool real){
if(real)
return realCompare;
else return fakeCompare;
}
int (*getAPointerFunc2(bool real))(int, int){
if(real)
return realCompare;
else return fakeCompare;
}
21、vector的動態增長優于預先分配內存。
使用vector的時候最好動態地添加元素。它不同于C和Java或其他語言的數據類型,為了達到連續性,更有效的方法是先初始化一個空vector對象,然后再動態添加元素,而不是預先分配內存。
22、vector值初始化
內置->0
有默認構造->調用默認構造
無默認構造,有其他構造->程序員手動提供初始值
無默認構造,也無其他構造->標準庫產生一個帶初值的對象
23、數組下標的類型
C++中,數組下標的正確類型是size_t而不是int,size_t是一個與機器相關的unsigned類型。
24、在聲明指針的時候,可以用空格將符號*與其后的標識符分隔開來,string *ps與string* ps都是可以的,但后者容易產生誤解,如:
string* ps1,ps2; //ps1是指針,而ps2是一個string對象
也就是說,人們可能誤把string和string*當作兩個類型,或者說string*被當作一種新類型來看待,但這是錯的!
25、一個有效的指針必然是以下三種狀態之一:
- 保存特定的對象的地址;
- 指向某個對象后面的另一對象;
- 或者是0值。表明它不指向任何對象。
其中int *pi=0;與int *pi;是不同的。前者是初始化指針指向0地址的對象(即為NULL)(pi initialized to address to no object),后者卻是未初始化的(ok, but dangerous, pi is uninitialized)。
編譯器可以檢測出0值的指針,程序可判斷該指針并未指向一個對象,而未初始化的指針的使用標準并未定義,對大多數編譯器來說,如果使用未初始化的指針會將指針中存放的不確定值視為地址,然后操縱該內存地址中存放的位內容,使用未初始化的指針相當于操縱這個不確定的地址中存儲的基礎數據,因此對未初始化的指針進行解引用時,通常會導致程序崩潰。
26、void*指針
void*指針只支持幾種有限的操作:
- 與另一個指針進行比較;
- 向函數傳遞void*指針或從函數返回void*指針;
- 給另一個void*指針賦值。
不允許使用void*指針操縱它所指向的對象。
27、指針和引用的比較(P105)
雖然使用引用(reference)和指針都可間接訪問另一個值,但它們之間有兩個重要區別。第一個區別在于引用總是指向某個對象:定義引用時沒有初始化是錯誤的。第二個重要區別則是賦值行為的差異:給引用賦值修改的是該引用所關聯的對象的值,而并不是使引用與另一個對象關聯。引用一經初始化,就始終指向同一個特定對象(這就是為什么引用必須在定義時初始化的原因)。
28、指針與typedef(P112)
const放在類型前和放在類型后都可以表示同樣的意思:
const string s1;
string const s2;
s1和s2均表示常量字符串對象。
但因此就導致了下面的句子可能產生誤解:
typedef string *pstring;
const pstring cstr;
容易錯把typedef當成文本擴展而產生下面的理解:
const string *cstr; //這并非上面例子的正確意思!(錯誤)
應該從聲明的句子看,也就是說只看const pstring cstr;,在這里pstring是一種指針類型,const修飾的是這個類型,因此正確的理解應該是:
string *const cstr;
而const pstring cstr;其實可以表示為pstring const cstr;,這樣的寫法則不容易產生誤解。從右向左閱讀的意思就是:cstr是const pstring類型,即指向string對象的const指針。
29、創建動態數組(注意點見代碼注釋)
const char *cp1 = "some value";
char *cp2 = "other value";
int *piArray1 = new int[10]; //內置類型沒有初始化
int *piArray2 = new int[10](); //內置類型需要加空圓括號,對數組元素進行初始化
std::string *psArray1 = new std::string[10]; //默認構造函數初始化
std::cout<<"----------"<<std::endl
<<"*cp1\t\t:"<<*cp1<<std::endl
<<"*cp2\t\t:"<<*cp2<<std::endl
<<"*piArray1\t:"<<*piArray1<<std::endl
<<"*piArray2\t:"<<*piArray2<<std::endl
<<"*psArray1\t:"<<*psArray1<<std::endl
<<"----------"<<std::endl;
但是下面的結果卻與概念上的不同:
////Visual Studio & MS VC++
//----------
//*cp1 :s
//*cp2 :o
//*piArray1 :-842150451
//*piArray2 :0
//*psArray1 :
//----------
////Eclipse&G++
//----------
//*cp1 :s
//*cp2 :o
//*piArray1 :4064608
//*piArray2 :4064560
//*psArray1 :
//----------
看來不同的編譯器對此的定義還是有所不同,注意看*piArray2的值,按照說明應該是初始化為0,但這里卻仍然表現出與*piArray1一樣的值,說明并沒有發生初始化。
對于動態分配的數組,其元素只能初始化為元素類型的默認值,而不能像數組變量一樣,用初始化列表為數組元素提供各不相同的初值。
30、const對象的動態數組
//P118
//error:uninitialized const array
const int *pciArray1 = new const int[10];
//ok:value-initialized const array
const int *pciArray2 = new const int[10]();
std::cout<<*pciArray1<<std::endl;
std::cout<<*pciArray2<<std::endl;
上面的示例的注釋來自書中,但在VC++編譯器和G++編譯器下卻不同,具體表現為:
- VC++:編譯正確,第一句輸出隨機地址的值,第二句輸出初始化的0(其中按照“標準”第一種因為未向const變量初始化,應該無法通過編譯,但這里可以)
- G++:編譯錯誤,第一句的錯誤信息為“uninitialized const in `new' of `const int'”,但第二句按照標準應該輸出0的,這里卻輸出了隨機地址的值。
看來兩個編譯器對這一問題的看法不太一致。
11、枚舉
//enum
enum HttpVerbs { Head, Post, Get, Delete };
HttpVerbs current_verbs = Post;
std::cout<<"Current Verbs = "<<current_verbs<<std::endl;
//error C2440: “=”: 無法從“int”轉換為“HttpVerbs”
//current_verbs = 3;
current_verbs = (HttpVerbs)2;
std::cout<<"Current Verbs = "<<current_verbs<<std::endl;
HttpVerbs copy_verbs = current_verbs;
std::cout<<"Copy Verbs = "<<copy_verbs<<std::endl;
HttpVerbs future_verbs = (HttpVerbs)((current_verbs + 1)%sizeof(HttpVerbs));
std::cout<<"Future Verbs = "<<future_verbs<<std::endl;
std::cout<<"HttpVerbs Size![by sizeof(HttpVerbs)] = "<<sizeof(HttpVerbs)<<std::endl;
輸出:
Current Verbs = 1
Current Verbs = 2
Copy Verbs = 2
Future Verbs = 3
HttpVerbs Size![by sizeof(HttpVerbs)] = 4
12、類,成員變量初始化
定義變量和定義數據成員存在著非常重要的區別:一般不能把類成員的初始化作為其定義的一部分。當定義數據成員時,只能指定該數據成員的名字和類型。類不是在類定義里定義數據成員時初始化數據成員,而是通過成為構造函數的特殊成員函數控制初始化。
class MyClass1
{
public:
int GetMyValue();
void SetMyValue(int value);
private:
//error C2864: “MyClass1::myValue”: 只有靜態常量整型數據成員才可以在類中初始化
int myValue = 3; //只需修改為int myValue;即可
};
13、struct關鍵字
C++支持另一個關鍵字struct,它也可以定義類類型。struct關鍵字是從C語言中繼承過來的。
如果使用class關鍵字來定義類,那么定義在第一個訪問標號前的任何成員都隱式指定為private;如果使用struct關鍵字,那么這些成員都是public,除非有其他特殊的聲明,如添加了private才為private,否則都是public,因此沒必要添加public關鍵字。
用class和struct關鍵字定義類的唯一差別在于默認訪問級別:默認情況下,struct的成員為public,而class的成員為private。
14、預編譯頭文件
一、什么是預編譯頭文件?
預編譯頭文件物理上與通常的的.obj文件是一樣的,但編譯入預編譯頭的.h,.c,.cpp文件在整個編譯過程中,只編譯一次,如預編譯頭所涉及的部分不發生改變的話,在隨后的編譯過程中此部分不重新進行編譯。進而大大提高編譯速度,并便于對頭文件進行管理,也有助于杜絕重復包含問題。
VC++程序一般包含的頭文件都比較復雜,如果每次都逐行分析可能會花很多時間,所以VC++默認設置是第一次編譯時分析所有頭文件,生成.pch文件,這個文件很大,但以后每次編譯時就可以節省很多時間。如果刪除了這個文件,下次編譯時VC++會自動生成它。
二、什么時候使用預編譯頭?
當大多.c或.cpp文件都需要相同的頭文件時。
當某些代碼被大量重復使用時。
當導入某些不同庫都有實現的函數,并產生混亂時。
15 、在頭文件中必須總是使用完全限定的標準庫名字。
因為預處理器會將頭文件復制到使用它的任何地方,兩種可能,一種是如果在頭文件中使用using,會使相關代碼不論是否需要該using都必將放置一個using,另一種是,假設有另一個庫可能也包含了相應的方法如有方法std::cout以及my::cout,如果使用了using,有可能導致被引入的程序偏離原本的使用意圖,或者導致編譯錯誤。
16、字符串字面值和標準庫string不是同一種類型
因為歷史原因以及為了與C語言兼容,字符串字面值與標準庫string類型不是同一種類型。這一點很容易引起混亂,編程時一定要注意區分字符串字面值和string數據類型的使用,這很重要。
17、getline函數輸入的時候丟棄末尾的換行符,并將整行返回,而且不丟棄第一個換行符,也就是即便你一開始就輸入了換行符,它仍然會返回,只不過返回的是一個空字符串而已。
編寫程序實現從標準輸入每次讀取一行文本。然后改寫程序,每次讀入一個單詞!
//std::cout<<"getline:<<std::endl;
WriteLine("getLine");
WriteLine("P72 編);
using std::string;
WriteLine("每(輸"NEXT\"進");
string str;
while(std::getline(std::cin, str))
{
if(str == "NEXT")
break;
std::cout<<str<<std::endl;
}
WriteLine("每輸"NEXT\"進");
while(std::getline(std::cin, str))
{
if(str == "NEXT")
break;
//從第0個開始查找空白
static const std::basic_string<char>::size_type npos = (std::basic_string<char>::size_type)-1;
std::basic_string<char>::size_type firstIndexOfEmpty = str.find_first_of(" ", 0);
if(firstIndexOfEmpty != npos)
std::cout<<str.substr(0, firstIndexOfEmpty)<<std::endl;
else
std::cout<<str<<endl;
}
其中WriteLine函數:
void WriteLine(std::string str)
{
std::cout<<str<<std::endl;
}
18、std::string對象的加法
如果一串字符串和string對象混合相加,則要求+操作符左右操作數必須至少有一個是string類型的。
推論:一串字符串和string對象混合相加,前兩個操作數中至少有一個是string對象。
std::string str2 = str1 + "this" + " that" + " those";
std::cout << str2 << std::endl;
//error C2110: “+”: 不能添加兩個指針
std::string str3 = "this" + " that" + str1 + " those";
std::cout << str3 << std::endl;
19、C標準庫頭文件和C++版本
C++標準庫也包括C標準庫,命名上則在C標準庫的名字前加一個c并省去后綴.h,比如C標準庫中的ctype.h,在C++中就有相應的標準庫cctype(注意沒有.h)。C++和C標準庫文件的內容是一樣的,只是采用了更適合C++的形式。而且通常cname頭文件中定義的名字都定義在命名空間std內,而.h版本的名字卻不是這樣。
20、關于中文編碼的相關問題
我們知道大部分的編譯器以及解決方案都由外國人發明創造,特別是美國人。因此很多程序默認不支持中文。雖然隨著Unicode的普及這部分問題得到了很大的改善(比如C#就可以完美地支持中文),但是類似C++這樣的語言,仍然面臨著中文編碼的問題。關于編碼,有一篇值得推薦的文章:地址1(備用地址)下載后打印(docx,50.7KB)查找更多
1、標識符命名規則!
標識符不能包含兩個連續的下劃線,也不能以下劃線開頭后面緊跟一個大寫字母。有些標識符(在函數外定義的標識符)不能以下劃線開頭。
但是在G++編譯器和VC編譯器下,二者均可正確編譯!


2、跨平臺編譯程序!
這里不是要講解如何跨平臺編譯程序,也不是告訴你如何更好地編寫通用平臺的程序規則,那可能涉及到很多的宏定義以及硬件相關特性。這里僅為使用示例代碼提供一種精簡的方式。
用Eclipse+MinGW的方式默認會很精簡,所以把它當作一種目標!
用Visual Studio 2008創建的程序會讓你引入預編譯頭stdafx.h(這通常發生在使用Visual Studio創建Win32控制臺應用程序,并直接點擊“完成”后),這將導致你無法將在Eclipse上編寫的程序直接運行在Visual Studio上。這時你應該通過修改項目屬性來獲得這種精簡的方式:(選擇項目,右鍵屬性,選擇配置屬性->C/C++->預編譯頭->創建/使用預編譯頭,選擇“不使用預編譯頭”->“確定”后再次編譯即可!)

3、變量命名習題
//測試變量命名!
//error C2632: “int”后面的“double”非法
//int double = 3.14159;
//-------------------------------------------------
char _='a';
std::cout<<_<<std::endl;
//-------------------------------------------------
//warning C4091: “”: 沒有聲明變量時忽略“bool”的左側
//error C2059: 語法錯誤: “-”
//bool catch-22;
//-------------------------------------------------
//error C2059: 語法錯誤: “數字上的錯誤后綴”
//char 1_or_2 = '1';
//-------------------------------------------------
float Float=3.14f;
std::cout<<Float<<std::endl;
4、在C++中,“初始化不是賦值”
初始化指創建變量并給它賦初始值,而賦值則是擦除對象的當前值并用新值代替。
int ival(1024); //直接初始化
int ival = 1024; //復制初始化
直接初始化語法更靈活,效率更高!
對內置類型來說,復制初始化和直接初始化幾乎沒有差別。
對類類型來說,有些初始化僅能用直接初始化完成。要想理解其中緣由,需要初步了解類是如何控制初始化的。
例如:
也可以通過一個計數器和一個字符初始化string對象。這樣創建的對象包含重復多次的指定字符,重復次數由計數器指定:
std::string all_nines(10, ‘9’); //all_nines = “9999999999”;
本例中,初始化all_nines的唯一方法是直接初始化。有多個初始化式時不能使用復制初始化。(V注:這里的初始化式即為構造函數的多個重載;這里所謂的“不能使用”應該是“功能有所不及”的意思!)
5、變量初始化規則
使用未初始化的變量經常導致錯誤,而且十分隱蔽。問題出在未初始化的變量事實上都有一個值。編譯器把該變量放到內存中的某個位置,而把這個位置的無論哪種位模式都當成是變量初始的狀態。當被解釋成整型值時,任何位模式都是合法的值——雖然這個值不可能是程序員想要的。因為這個值合法,所以使用它也不可能導致程序崩潰。可能的結果是導致程序錯誤執行和/或錯誤計算。
//在Eclipse中運行沒有出現錯誤!
//在Visual Studio中運行出現運行時錯誤!
int ival; //沒有初始化!
std::cout<<ival<<std::endl;
6、聲明和定義
為了能讓多個文件訪問相同的變量,C++區分了聲明和定義。簡單地說就是可以用extern關鍵字來聲明,任何有分配內存行為的聲明都是定義。定義也是聲明。聲明:標明變量的類型和名字;定義:為變量分配存儲空間,還可以為變量指定初始值。
舉例說明:
extern double pi; //聲明
double pi; //定義,聲明了pi同時定義了pi
extern double pi = 3.14159; //定義,因為它為pi分配了初值。只有當該extern語句
位于函數外部的時候才允許使用初始化式,否則將導致編譯錯誤。
7、變量的隱藏:
std::string s1 = "I am a std::string!";
std::cout<<s1<<std::endl;
for(int s1=3; s1!=0; --s1)
std::cout<<"I am a number(int):"<<s1<<std::endl;
提示:在Visual Studio 2008中使用std::string定義一個變量,再通過std::cout將其輸出,將會得到“error C2679: 二進制“<<”: 沒有找到接受“std::string”類型的右操作數的運算符(或沒有可接受的轉換)”錯誤信息,這時要檢查頭文件中是否包含#include <string>。而在Eclipse中則不用如此設置(具體看編譯器版本)。這與標準庫實現的具體細節有關,在MSVC中,它在文件Program Files (x86)\Microsoft Visual Studio 9.0\VC\include\string中被實現,在GNU中,它在base_string.h中被實現。在使用std::string時,總是包含#include <string>是一個好習慣!
8、const對象默認為文件的局部變量
一般聲明變量后可以在其它文件中通過extern關鍵字聲明并使用該變量:
//文件1:
int counter;
//文件2:
extern int counter;
++counter;
但是如果是const則無法訪問。可以通過顯式指定extern關鍵字使其成為全局可訪問對象:
//文件1:
extern const int bufSize = getBufSize();
//文件2:
extern count int bufSize;
//……使用bufSize
注解:非const變量默認為extern。要使const變量能夠在其他的文件中訪問,必須顯式地指定它為extern。
9、引用
int ival = 1024;
int &refVal = ival;
當引用初始化后,只要該引用存在,就保持綁定到初始化時指向的對象。不可能將引用綁定到另一個對象。
也正因為如此,所以引用比指針的優勢就在于:引用不可以在方法中篡改,這使得方法變量變得安全了。
10、const引用
const int ival = 1024;
const int &refVal = ival;
這里我們要求左側的類型是一致的,包括const!
非const引用只能綁定到與該引用同類型的對象。
const引用則可以綁定到不同但相關的類型的對象或綁定到右值。(具體示例詳見C++Primer v4 P52)
例如:
//錯誤代碼
double dval = 3.14;
const int &ri = dval;
編譯器會將這些代碼轉換成如以下形式的編碼:
int temp = dval;
const int &ri = temp;
如果ri不是const,那么可以給ri賦一新值。這樣做不會修改dval,而是修改了temp。期望對ri的賦值會修改dval的程序員會發現dval并沒有被修改。僅允許const引用綁定到需要臨時使用的值完全避免了這個問題,因為const引用是只讀的。
但是如下代碼可以執行:
int ival = 1024;
const int &refVal = ival;
++ival;
//++refVal; //error C3892: “refVal” 不能給常量賦值
std::cout<<"ival="<<ival<<"\trefVal="<<refVal<<std::endl;
輸出:ival=1025 refVal=1025
const double dval = 3.14;
const int &ri = (int)dval;
std::cout<<ri<<std::endl;
輸出:3
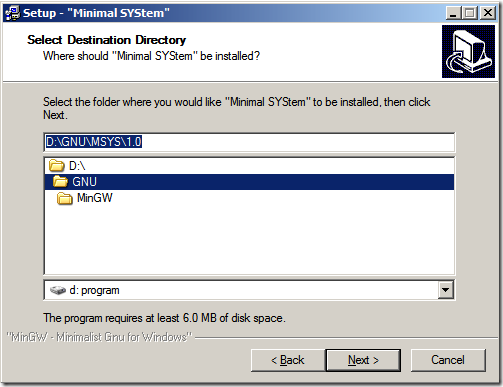
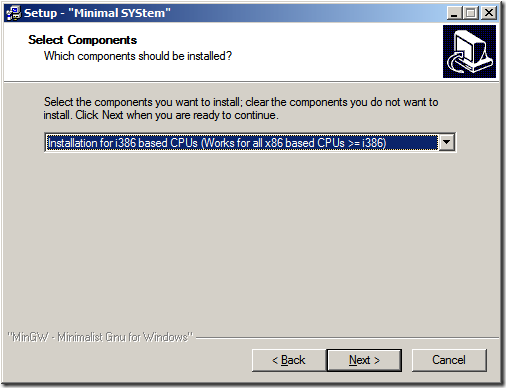
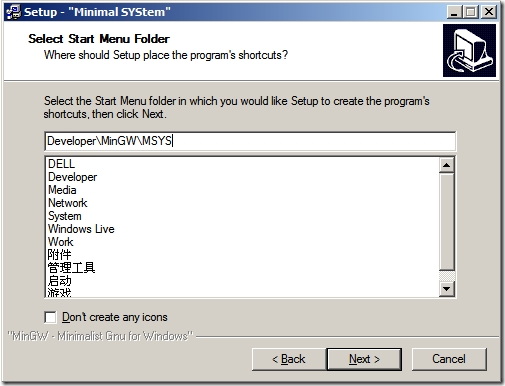
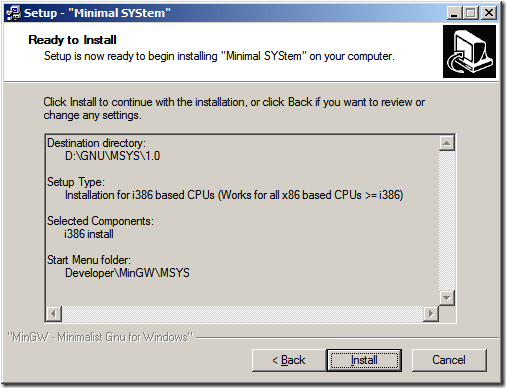
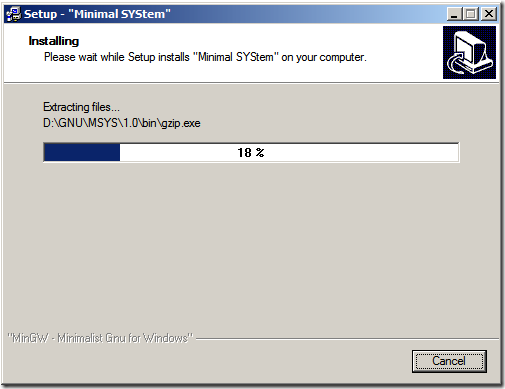
以上步驟基本上沒有啥技術含量(一點都沒有噢,只為記錄一下,圖片也漂亮點),注意到最后這個黑色的命令行,在安裝結束之后會出現這么個命令行,其中會問你是否已經安裝過MinGW了?在回答y之后,要求輸入MinGW的地址,注意,在資源管理器里面我們都是用“\”來代表路徑層級的分層的,在這里是用“/”(方向不一樣)。另外地址中不允許帶有空格。這一點在《如何安裝MinGW》一文中已經有提到。
MSYS(Minimal GNU(POSIX)system on Windows)
由于本文的主角是它,我們先來看看它是什么?從名字的全稱我們可以看出它是一個小型的GNU環境。MSYS在windows下模擬了一個類unix的終端,它只提供了MinGW的用戶載入環境,Cygwin在windows下模擬了一個linux環境,它們帶有一些unix終端下常用的工具,如ls、tail、tar,其實它們都是相應unix/linux工具的windows版,而且它們的環境會繼承windows的一些系統變量,如path,如果windows下裝有ruby、rails,在它們的環境里同樣都可以直接運行。
Cygwin(基于GPL licensed協議)
Cygwin并不是GNU,它只是實現了許多Windows API中沒有的Unix風格的調用(如fork,spawn,signals,select,sockets等),并將它們封裝在Cygwin.dll中,讓Windows系統能夠模擬出Unix的調用,進而直接使用Unix上的交叉編譯器來生成可以在windows平臺上運行的工具集。以這些移植到windows平臺上的開發工具為基礎,cygnus又逐步把其他的工具(幾乎不需要對源代碼進行修改,只需要修改他們的配置腳本)軟件移植到windows上來。這樣,在windows平臺上運行bash和開發工具、用戶工具,感覺好像在unix上工作。
MinGW(Minimalist GNU For Windows)
主要由GNU binary utilities、GCC和GDB組成。同時還包括一些必要的庫,例如libc(C Runtime),及專門用于Win32環境的API接口庫。如果你想學習linux環境下的編程,而又不想裝linux,那你就裝一個MinGW吧。
它與Cygwin實現了相同的夢想,也是為了實現在Windows上能夠運行Unix上的工具。但與之不同的是它采用的是Windows C類庫(mscvrt)而不是Cygwin采用的GNU C運行時類庫。同時也因為兩個運行時類庫的端口不同而導致兩者有諸多區別。但是卻因為采用了直接支持Windows環境的Windows C運行時類庫,它也給CDT(C/C++ Development Toolkit)提供了最好的支持。同時,它避免了像Cygwin使用了GPL協議。
C/C++ Development Toolkit(CDT)
C/C++ Development Toolkit(CDT)是基于Eclipse特征的,為使用C/C++編程語言,提供創建、編輯、導航、生成(build)和調試項目的一個集合。
它不包含必要的轉換C/C++代碼的編譯器和調試器來執行和調試程序,但是它提供了一個允許這些工具集成在一個相容方式下協作的框架。它允許你根據你的項目需求來混合和匹配這些工具。
通常,商業發行的CDT包括了必要的工具集。如果你沒有,那么最基本的CDT提供了綜合的GNU工具來生成和調試。他們通常指Cygwin和MinGW等。
做了三個簡單的概念介紹后,我們知道了它們各自的一些特征。它們都不是像Visual Studio這樣可以拿來直接就用的軟件,它們的使用需要一些必要的配置。這也是社區文化的一種體現。
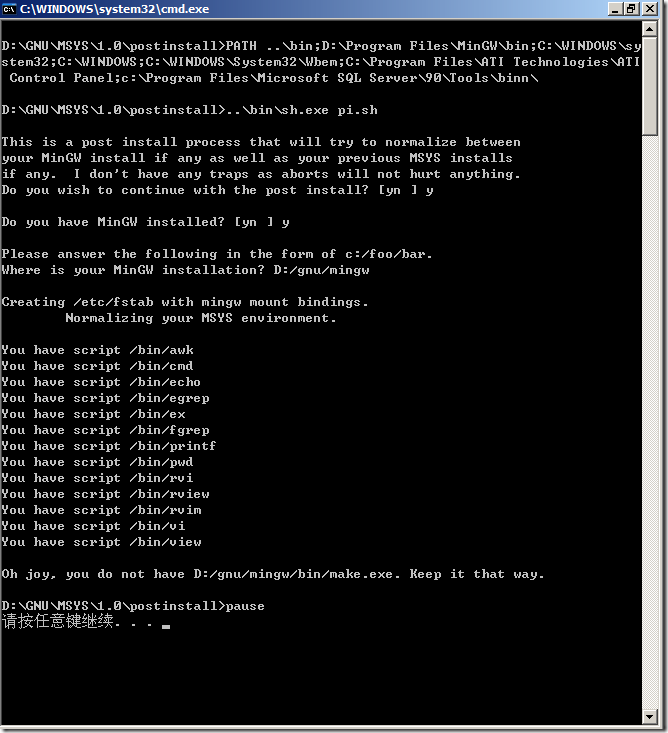
以上的安裝步驟最后一步出現的命令行模式,確實是大部分安裝程序中不常出現的,那么它究竟為我們做了什么呢?帶著這樣的疑問,我們滾動到這副截圖來看看它的內容。從內容中我們可以看到在安裝完畢之后我們會被要求輸入MinGW的所在目錄,根據文檔中的說明,我們可以將MinGW放在除了MSYS目錄的任何的一個目錄中(也就是如圖D:\GNU\MSYS位置不能放),至于放了之后會怎樣,筆者也不知曉,望知曉者可以告知在下,定當感激不盡。
之后它會根據我們給出的路徑在MSYS目錄下的etc文件夾(如本例中的D:\GNU\MSYS\1.0\etc)內找到fstab文件并進行編輯(會在稍后描述)。然后檢查我們給出的路徑下的一些文件。從圖中我們可以看到我們缺少了一個非常重要的make.exe文件,這個文件其實存在,只是文件名不同,我們可以將其重命名為make.exe。(本例中,我們將已經安裝的D:\GNU\MinGW\bin\mingw32-make.exe修改為D:\GNU\MinGW\bin\make.exe即可)
fstab文件
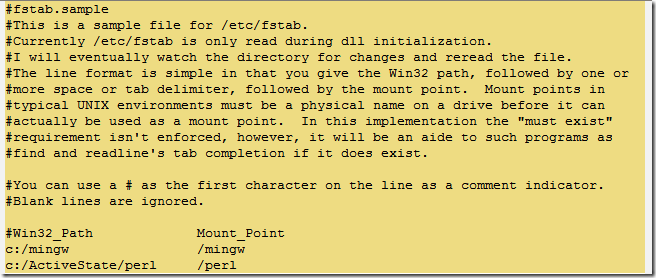
與fstab相同路徑下的有個fstab.sample文件,這是一個示例文件。您可以仿造它進行一些設置。(如果您按照之前我們的安裝步驟,并且中途沒有出現偏差的話,那么通常您已經正確設置了fstab文件,如果因為其它原因您需要修改該文件,也可以參考該部分內容。)fstab文件將是dll初始化期間唯一被載入的文件。它的格式我們可以看到,是由一個物理路徑+“空格/TAB制表格”+Mount_Point來維持的。它實現了一個路徑映射的體系結構,以至于我們不必手動地搬動那些文件到正確的目錄,也能夠讓我們正確地訪問我們所需的文件。
下圖為fstab.sample文件
下面我們打開fstab看看系統之前為我們設置了什么:

從本例子中我們發現了系統為我們做好了這樣一個映射。將D:/gnu/mingw映射到了/mingw。
MSYS只是一個模擬的平臺,我們除了讓它跟MinGW實現互聯互通,我們也能夠讓它跟系統上的其他程序互聯互通。
通過運行D:\GNU\MSYS\1.0\msys.bat批處理文件,我們可以打開如上圖所示的命令行窗口(它的功能基本上類似于運行了D:\GNU\MSYS\1.0\bin\sh --login -i語句)
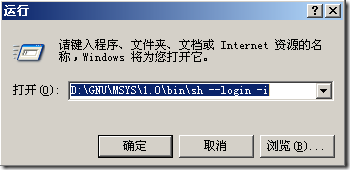
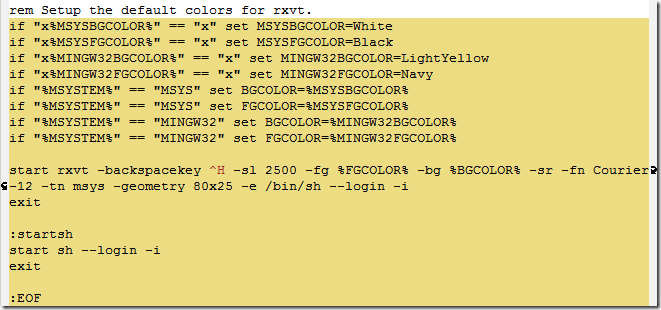
執行的內容相當于運行了下面的批處理語句。
下面讓我們打開一個word程序。我們在命令行下輸入:
$ start '/d/Program\ Files/Microsoft\ Office/Office12/WINWORD' $@
語句(具體路徑視您本機的word安裝程序路徑所定)
我本機的路徑為
D:\Program Files\Microsoft Office\Office12\WINWORD.EXE
我們很容易看出它們二者之間的區別。下面我就針對這些區別做一些簡要的解釋。
首先我們看“D”是一個盤符,在這個映射里面,我們規定,盤符若為“D:\”我們就將其轉化為“/d”,同時為了與Unix的使用習慣一致,在資源管理器中表示層次的“\”符號都變成了“/”,若遇到空格,我們則以“\ ”(\+空格)來表示。因此我們有了如上一個等價的路徑轉換。
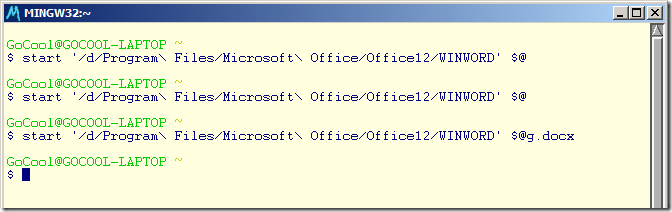
復制粘帖
說到使用這樣的命令行方式大家一定覺得還不是那么方便。因為這里不能夠復制粘貼。但你錯了,這里復制粘貼也很容易。
復制:選擇你要復制的部分,然后鼠標點一下,就可以了。容易吧?
粘帖:只需用shift+鼠標左鍵,就可以直接將剪貼板內的文字粘帖進來了。
(更多辦法請參考doc/msys/readme.rtf)
在Windows上使用gcc編譯器,我們需要獲取一些第三方的工具。MinGW是一個基于GNU規范的可以在Windows上編譯的第三方工具。MinGW與著名的Cygwin的差別在于它使用Windows系統的C運行時(mscvrt)取代了GNU的C運行時。因為兼容層不是必須的,因此避免了Cygwin的GPL授權問題。
同時也因為它直接使用了Windows系統的C運行時,從而增強了利用它開發的程序在Windows系統上的兼容性。
1、首先到sourceforge.net(http://sourceforge.net/projects/mingw/)上下載最新的MinGW。如果您在安裝的時候始終和互聯網保持連接(這也是必須的),那么首先安裝包會檢測當前的版本是否為最新,如果不是,則會提示有更新。這時,您需要自己上網站上去下載最新的版本。
2、下載的最新版本安裝的時候如下圖解。基本上都是NEXT的操作,所以也沒有什么可說明的。
3、值得注意的一點是,安裝路徑中最好不要有空格,因為在別的軟件的引用中可能出現問題。類似:Program files的最好都不要出現。


至此,這個MinGW就已經安裝完了,它是一組有用的工具集(這些工具將包含在$\bin目錄下(其中 $代表您所選擇的安裝路徑))。
摘要: 初入Emacs,還是要入鄉隨俗的,基于Unix的程序還是在鍵盤命令上下了很大的功夫,但這樣的通用性也得到了極大的提高。下面是拷貝Emacs的快速指南的中譯版本,只是記錄一下,沒有別的意思。呵呵提供一下Windows平臺Emacs的安裝方式:1、下載Emacs基于Windows的安裝包,我是從ftp://ftp.keystealth.org/pub/gnu/gnu/emacs/windows/ema...
閱讀全文

Eclipse(http://www.eclipse.org/)
Eclipse是一個由IBM公司牽頭開發的一個自由軟件,后來IBM公司為了讓更多的公司積極參與進來而不至于讓它們因為這是一個由IBM主導的軟件而導致軟件開發者們拒之門外,Eclipse的身份則轉為由一個固定員工的組織所維護的非營利組織。它和所有的自由軟件一樣,被免費地提供給所有熱愛開源事業的人們,通過集體的智慧將它進行完善。
Eclipse是一款跨平臺的IDE,它既不是編譯器,也不是簡單的編輯器,它提供了一個開放的平臺用于為各種各樣的編譯器,開源或者不開源的,提供一個能夠共同操作的平臺。由于它是一款基于Java虛擬機的應用軟件,因此它同時也是一款跨平臺的IDE。跨平臺的特性讓它的存在有了更有征服力的理由。眾所周知,Linux是開源社區中的一顆璀璨奪目的明珠,以Linux為核心的開源軟件組織也是數不勝數,無數人為之奮斗傾盡心血。但是作為開發人員,Windows平臺上的Visual Studio一貫的平易近人(不是指價格上)讓所有的程序員所稱贊。就算是要搞Borland Delphi也有一款優秀的IDE在實時待命。但是在Linux上有啥?對于骨灰級的程序員,拿個Emacs甚至一個記事本就可以將編程進行到底。他們追求的無非就是換行和顯色等漂亮點的效果,對于項目級的維護和便利并沒有過高的要求,也許是一種習慣,也許是一種妥協。但是這一切因為Eclipse的出現而大大變樣了,程序員從紛繁的makefile中解脫出來專心于邏輯代碼的編寫,很多自動化的組件出現更增加了程序的健壯性。雖然舊式的編碼方式顯得更專業,但還是一定程度上束縛了生產力的發展。
多說無益,反正IDE的出現總是預示著編程門檻的降低,隨之而來帶來的就是在該平臺上的投入的人員越來越多而讓這個平臺能夠接受越來越多的人來參與。這對這個產業絕對是“生產力大獎”的。
CDT(http://www.eclipse.org/cdt/)
CDT英文全稱是C/C++ Developer Tools,CDT是為Eclipse平臺提供集成開發環境的一個項目。我們知道將Eclipse+CDT就可以用于開發C++了,現在又說這CDT也是個IDE,這是怎么回事呢?事實是這樣的,因為Eclipse是個開放的平臺,所以它希望所有的開發者都能夠參與進來。但是現在市面上流行的語言種類太多了,多得有點數不過來,有些甚至只有少數幾個人自己會用(比如中文編程語言吧)。所以Eclipse公開了自己的部分接口讓這些語言能夠定義帶有自己特征的部分功能。可以這么理解,Eclipse定義了IDE的共性部分,而類似CDT這樣的則定義了IDE的個性部分。所以它是專門針對C/C++IDE的個性化組件。有了它,用Eclipse寫C/C++代碼才顯得更有價值。
CDT的組件安裝,則是將安裝包解壓后,直接覆蓋到Eclipse的目錄下,重新啟動Eclipse即可。關于這點內容可能根據具體的版本會略有不同。當然最簡單的方式是下載C/C++版本的Eclipse。
編譯器(Complier)
每一個科班出身的程序員對這個詞都耳熟能詳,每個人對這個詞都有自己的理解。但是真正接觸過的程序員又有多少呢?來一段軟件開發技術發展的簡史,傳說在很久以前,搞計算機的都是科學家,那時候大家剛剛從硬件電板上轉到鍵盤編碼的過程中來,用匯編+DOS似乎是一件很享受的事,但是那批科學家已經青春不在了。新來的年輕人又弄出了高級語言這種接近人類思維的語言,很快匯編就成為了專屬領域的內容,能用高級語言的地方,沒有人愿意讓匯編有用武之地。很快匯編也漸漸淡出視線。然后就是圖形化界面的出現,但這本身并沒有改變人們使用編譯器的方式。無非就是換成記事本去編寫代碼罷了。但是圖形化的出現促使了圖形化IDE的出現,人們發現編譯事實上又是遵循一定規律的集合,這部分可以很容易地通過一些編程上的限制或者通過代碼可以整理出人們期待的編譯方式,于是很快makefile一類的事也變成人們可以淡忘的事了。現在人們使用許多優秀的IDE,編譯不過只是按一下“編譯”或者輸入個快捷方式。那些難記的參數早已經忘到九霄云外了。由于編程的門檻在大大降低,所以是越來越多的程序員跟編譯器無一面之緣了。我們稱他們都是被慣壞的程序員,當然并不表示他們就怎么不好了,只是一個社會現象罷了。正如我們會用白米煮飯,并不需要我們去理解谷子的剝皮方式,也不需要去理解水稻的種植。我們只要懂得選擇哪種米能煮出更好吃的米飯就可以了。當然了,這一點在Windows平臺上顯得更為常見,因為Windows是最普及也是很優秀的一款圖形化的操作系統。但是在Unix上,計算機的發展還沒有那么文明。這里的大多數程序員從水稻種植到磨成白米,樣樣都得會,不然連HelloWorld都整不出來。而且每次要Say Hello就得重頭開始寫makefile,手動編譯等。雖然這看起來很酷,但是沒有多少意思。
C/C++的編譯器很多,比較常見的優秀作品有MS C++,GCC(G++),Borland C++等,其中在Windows平臺上基本都用MS C++,而且MS C++也是截至我發稿時最接近ISO C++標準的編譯器(據說已經實現了標準的98%以上),但是在Linux平臺上,則多數是以GCC為主,其中GNU GCC Complier則是其中的佼佼者,但是它的標準化只達到了(94%以上,但是之前一直優于MS C++,即便如此,大部分的Linux C++開發人員仍然親睞GCC,因為它是OpenSource的)。
經過簡單的一段介紹,我們應該對編譯器有了一點感覺了,可是這和我們這篇主題有啥關系?我只是一個希望點一下“編譯”按鈕的讀者,我并不希望makefile然后才編譯。這一切似乎和我沒啥關系。不過我告訴你,就了Eclipse+CDT,你仍然做不到這點。因為就算是針對C/C++的開發,我們仍然要經常面臨使用不同的編譯器進行編譯的情形。甚至有些語法特性和標準C++并無任何關聯,而僅與不同的編譯器有關。又或者有些源代碼在不同的編譯器編譯下會產生微妙不同的目標代碼,而這一些則需要我們更好地理解。就算我們期望有一種通用或者說是常用的方式來解決這個問題,我們仍然需要手動為自己配置一個簡單而通用的編譯器,盡管你從不了解編譯器方面的差異,你起碼也得有一個編譯器。那么好吧,既然Eclipse的安裝如此不盡人意,那我就只能自己動手了。
如果您看過我的上兩篇文章,您或許已經跟著做了,如果沒有,那么重復一遍。(《如何安裝MinGW 》、《如何安裝Minimal SYStem(MSYS)》)
如果您照上面那么做了,那么您的機器上已經有了MinGW和MSYS了,換言之,您已經有了gcc、make以及其它一些必要文件了。下面您需要做的只要設定一下環境變量即可。
設置環境變量步驟:
右鍵“我的電腦”(沒有“我的電腦”的用戶在桌面右鍵“屬性”,然后再“桌面”選項卡中自定義中將其選出,或者直接在Windows Explorer地址欄中輸入“我的電腦”,回車即可),選擇“屬性”,選擇“高級”選項卡,最下方有“環境變量”(或Alt+N打開),在下面窗格“系統變量”中,選擇變量“Path”,雙擊后出現“編輯系統變量”的選項。將我們MinGW的bin目錄全局路徑復制進去(一般可以復制在“變量值”的最前面,或者緊跟在任何一個“;”(分號,不包括引號)后),點擊確定,即可。
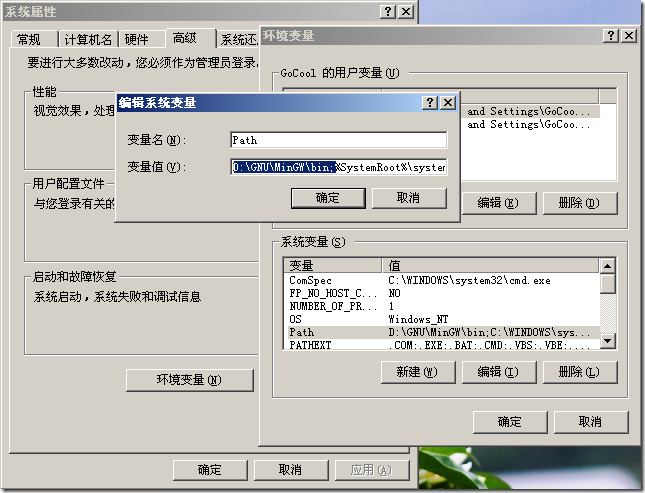
如果我現在告訴您可以編輯C/C++代碼了,您相信么?
好吧,那么就開始我們的第一個C/C++代碼的測試,以驗證我們的成果。
一個HelloWorld的基本步驟:
1、打開Eclipse
2、選擇一個“工作空間”(workspace)
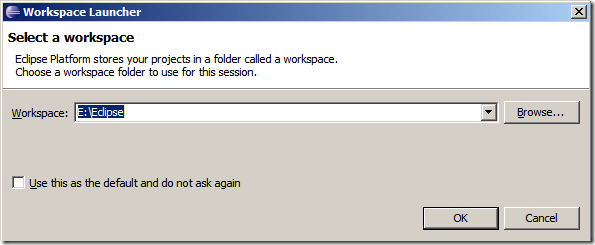
3、選擇一個“工程”(Project)

4、在向導中設置項目名稱。這里我們將項目名稱設定為HelloEclipse,在存放路徑上,我們需要有所講究,如果我們勾選Use default location的話,我們的location位置將是步驟1中設置的路徑,我們通常需要設立子文件夾,以避免工程數量的增加而導致不同工程文件的交錯。深刻理解這一點,把兩種方案都試一下就可以了。
在Project types(項目類型)中,我們可以選擇一個Hello World ANSI C Project,在Toolchain中選擇MinGW GCC,這就是我們本機所擁有的編譯器了。
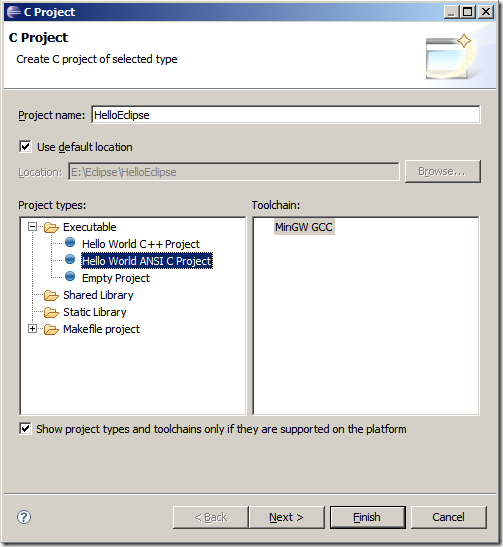
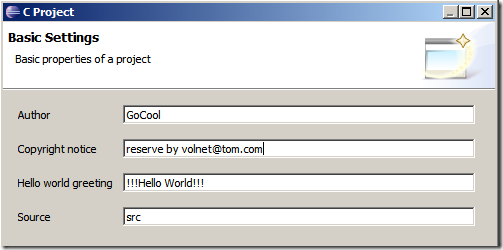
5、因為我們選擇了Hello World項目,所以我們還有一個基本設置的頁面,可以輸入一些個性化的信息。
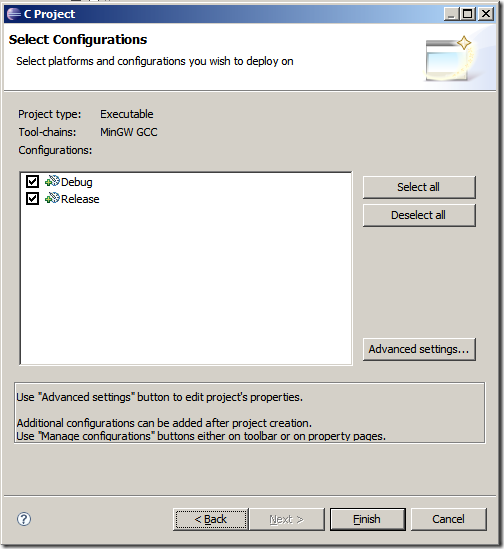
6、如果您是在Windows上使用,則可以選擇高級設置(Advanced settings),選擇二進制轉換器的類型(如圖),當然,默認情況下是選好的因此,不用顧及該部分內容也依然會成功,但如果您遇到諸如此類的問題,則可以看看這里是否正確設置了。
相關路徑:C/C++ Build -> Settings -> Binary Parsers
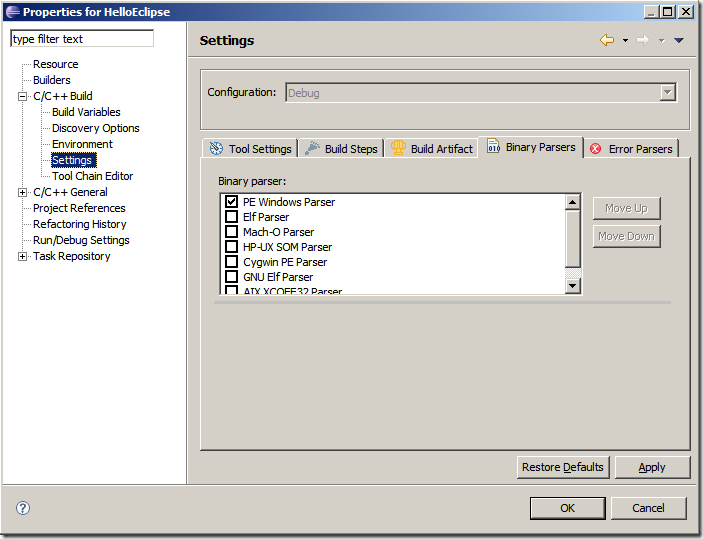
點擊“OK”或者“Finish”即可完成。
7、編寫個代碼試試(其實系統已經為我們在src文件夾下生成了一個)
讓我們寫一個簡單的代碼試試
代碼如下:
#include <stdio.h>
void myputs(char * s);
int main()
{
char * s = "HelloEclipse!";
myputs(s);
return 0;
}
void myputs(char * s)
{
while(*s)
{
printf("%c",*s++);
}
return;
}
另外在菜單Project中有很多Build相關的選項,選擇Build Project后,等待編譯結束,然后點擊“Run”(綠色圖標),在最下方的選項卡中找到Console,即可看到輸出結果。
用慣了GCC編譯器,也就容易將C語言的寫法和其它的寫法混淆起來。雖然在GCC平臺上可以順利編譯,但是在其它編譯器比如Microsoft C++編譯器下就有可能編譯出錯了。看下面這段代碼:
#include <stdio.h>
int main(void){ char *s1 ;
s1 = "Hello";
char *s2 ;
s2 = "World";
printf("%s %s\n",s1,s2); return 0;
}
它看上去是可以執行的,在GCC編譯器下它確實也是可以執行的。但在VC++中則不能執行,準確地說,在未開啟編譯器選項為標準C99的情況下,是會編譯出錯的。
按如上所示的編譯器在C89標準下編譯,GCC pass,MS C++ fatal。錯誤指示會在s2 = "World"; 這句話上,錯誤代碼通常為
error C2143:語法錯誤:缺少“;”(在“類型”的前面)
要是您的類型剛好由typedef來定義的話,則會出現錯誤代碼:
error C2275:“your_type”:將此類型用作表達式非法
下面兩幅截圖展示了以上兩種錯誤。因為在變量聲明環節出了錯誤,因此會引發一連串的錯誤,包括變量未定義等錯誤。

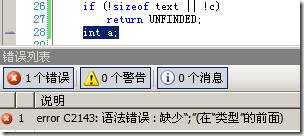
建議:為了保持源碼能夠保持跨編譯器特性,我們最好能夠按舊時的寫法來寫(C89)直到它確實被淘汰為止。