|
#
查看端口被占用情況:
開始==》運行==》cmd==》netstat -ano|more(后面加more可以分頁顯示) 可獲得PID,記下PID
查看進程被誰啟動:
任務管理器==》查看(V)==》選擇列(S)…==》勾選“PID(進程標識符)”==》找到PID對應的映像名稱……
摘要: 編寫自己的一個ping程序,可以說是許多人邁出網絡編程的第一步吧!!這個ping程序的源代碼經過我的修改和調試,基本上可以取代windows中自帶的ping程序. 各個模塊后都有我的詳細注釋和修改日志,希望能夠對大家的學習
Code highlighting produced by Actipro CodeHighlighter (freeware)http://www.CodeHighli... 閱讀全文
插入排序
1.直接插入排序
原理:將數組分為無序區和有序區兩個區,然后不斷將無序區的第一個元素按大小順序插入到有序區中去,最終將所有無序區元素都移動到有序區完成排序。
要點:設立哨兵,作為臨時存儲和判斷數組邊界之用。
實現:
Void InsertSort(Node L[],int length)
{
Int i,j;//分別為有序區和無序區指針
for(i=1;i<length;i++)//逐步擴大有序區
{
j=i+1;
if(L[j]<L[i])
{
L[0]=L[j];//存儲待排序元素
While(L[0]<L[i])//查找在有序區中的插入位置,同時移動元素
{
L[i+1]=L[i];//移動
i--;//查找
}
L[i+1]=L[0];//將元素插入
}
i=j-1;//還原有序區指針
}
}
2.希爾排序
原理:又稱增量縮小排序。先將序列按增量劃分為元素個數相同的若干組,使用直接插入排序法進行排序,然后不斷縮小增量直至為1,最后使用直接插入排序完成排序。
要點:增量的選擇以及排序最終以1為增量進行排序結束。
實現:
Void shellSort(Node L[],int d)
{
While(d>=1)//直到增量縮小為1
{
Shell(L,d);
d=d/2;//縮小增量
}
}
Void Shell(Node L[],int d)
{
Int i,j;
For(i=d+1;i<length;i++)
{
if(L[i]<L[i-d])
{
L[0]=L[i];
j=i-d;
While(j>0&&L[j]>L[0])
{
L[j+d]=L[j];//移動
j=j-d;//查找
}
L[j+d]=L[0];
}
}
}
交換排序
1.冒泡排序
原理:將序列劃分為無序和有序區,不斷通過交換較大元素至無序區尾完成排序。
要點:設計交換判斷條件,提前結束以排好序的序列循環。
實現:
Void BubbleSort(Node L[])
{
Int i ,j;
Bool ischanged;//設計跳出條件
For(j=n;j<0;j--)
{
ischanged =false;
For(i=0;i<j;i++)
{
If(L[i]>L[i+1])//如果發現較重元素就向后移動
{
Int temp=L[i];
L[i]=L[i+1];
L[i+1]=temp;
Ischanged =true;
}
}
If(!ischanged)//若沒有移動則說明序列已經有序,直接跳出
Break;
}
}
2.快速排序
原理:不斷尋找一個序列的中點,然后對中點左右的序列遞歸的進行排序,直至全部序列排序完成,使用了分治的思想。
要點:遞歸、分治
實現:
選擇排序
1.直接選擇排序
原理:將序列劃分為無序和有序區,尋找無序區中的最小值和無序區的首元素交換,有序區擴大一個,循環最終完成全部排序。
要點:
實現:
Void SelectSort(Node L[])
{
Int i,j,k;//分別為有序區,無序區,無序區最小元素指針
For(i=0;i<length;i++)
{
k=i;
For(j=i+1;j<length;j++)
{
If(L[j]<L[k])
k=j;
}
If(k!=i)//若發現最小元素,則移動到有序區
{
Int temp=L[k];
L[k]=L[i];
L[i]=L[temp];
}
}
}
2.堆排序
原理:利用大根堆或小根堆思想,首先建立堆,然后將堆首與堆尾交換,堆尾之后為有序區。
要點:建堆、交換、調整堆
實現:
Void HeapSort(Node L[])
{
BuildingHeap(L);//建堆(大根堆)
For(int i=n;i>0;i--)//交換
{
Int temp=L[i];
L[i]=L[0];
L[0]=temp;
Heapify(L,0,i);//調整堆
}
}
Void BuildingHeap(Node L[])
{ For(i=length/2 -1;i>0;i--)
Heapify(L,i,length);
}
歸并排序
原理:將原序列劃分為有序的兩個序列,然后利用歸并算法進行合并,合并之后即為有序序列。
要點:歸并、分治
實現:
Void MergeSort(Node L[],int m,int n)
{
Int k;
If(m<n)
{
K=(m+n)/2;
MergeSort(L,m,k);
MergeSort(L,k+1,n);
Merge(L,m,k,n);
}
}
基數排序
原理:將數字按位數劃分出n個關鍵字,每次針對一個關鍵字進行排序,然后針對排序后的序列進行下一個關鍵字的排序,循環至所有關鍵字都使用過則排序完成。
要點:對關鍵字的選取,元素分配收集。
實現:
Void RadixSort(Node L[],length,maxradix)
{
Int m,n,k,lsp;
k=1;m=1;
Int temp[10][length-1];
Empty(temp); //清空臨時空間
While(k<maxradix) //遍歷所有關鍵字
{
For(int i=0;i<length;i++) //分配過程
{
If(L[i]<m)
Temp[0][n]=L[i];
Else
Lsp=(L[i]/m)%10; //確定關鍵字
Temp[lsp][n]=L[i];
n++;
}
CollectElement(L,Temp); //收集
n=0;
m=m*10;
k++;
}
}
dll是在你的程序運行的時候才連接的文件,因此它是一種比較小的可執行文件格式,.dll還有其他的文件格式如.ocx等,所有的.dll文件都是可執行;
lib是在你的程序編譯連接的時候就連接的文件,因此你必須告知編譯器連接的lib文件在那里。一般來說,與動態連接文件相對比,lib文件也被稱為是靜態連接庫。當你把代碼編譯成這幾種格式的文件時,在以后他們就不可能再被更改。如果你想使用lib文件,就必須:
1. 包含一個對應的頭文件告知編譯器lib文件里面的具體內容
2 .設置lib文件允許編譯器去查找已經編譯好的二進制代碼
如果你想從你的代碼分離一個dll文件出來代替靜態連接庫,仍然需要一個lib文件。這個lib文件將被連接到程序告訴操作系統在運行的時候你想用到什么 dll文件,一般情況下,lib文件里有相應的dll文件的名字和一個指明dll輸出函數入口的順序表。如果不想用lib文件或者是沒有lib文件,可以使用WIN32 API函數LoadLibrary、GetProcAddress。事實上,我們可以在Visual C++ IDE中以二進制形式打開lib文件,大多情況下會看到ASCII碼格式的C++函數或一些重載操作的函數名字。
一般我們最主要的關于lib文件的麻煩就是出現unresolved symble 這類錯誤,這就是lib文件連接錯誤或者沒有包含.c、.cpp文件到工程里,關鍵是如果在C++工程里用了C語言寫的lib文件,就必需要這樣包含:
extern "C"
{
#include "myheader.h"
}
這是因為C語言寫的lib文件沒有C++所必須的名字破壞,C函數不能被重載,因此連接器會出錯。
在VC中不用MFC如何制作dll
方法一:使用export 和 import
在VC中建立一個Console Application,建立2個文件:Dll.h 和 Dll.cpp
Dll.h
========================================================
#ifdef MYLIBAPI
#else
#define MYLIBAPI extern "C" _declspec (dllimport)
#end if
MYLIBAPI int Add (int iLeft, int iRight)
MYLIBAPI int Sub (int iLeft, int iRight)
========================================================
Dll.cpp
========================================================
#define MYLIBAPI extern "C" _declspec (dllexport)
#include "Dll.h"
int Add (int iLeft, int iRight)
{
return iLeft + iRight ;
}
int Sub (int iLeft, int iRight)
{
return iLeft - iRight ;
}
========================================================
保存文件。在Project->setting->link 最下面加上 “/dll”, "/"之前一定要與前一項有空格。然后編譯,就可以在debug 或 release下面找到dll 和 lib 文件了使用的時候包含dll.h文件。
方法二:使用def文件
建立一個console application, 建立2個文件dll.h 和 dll.cpp
Dll.h
========================================================
int Add (int iLeft, int iRight) ;
int Sub (int iLeft, int iRight) ;
========================================================
Dll.cpp
========================================================
#include "Dll.h"
int Add (int iLeft, int iRight)
{
return iLeft + iRight ;
}
int Sub (int iLeft, int iRight)
{
return iLeft - iRight ;
}
========================================================
然后再當前目錄下面建立一個.def文件,文件名最好和要輸出的dll名字一樣,擴展名為.def, 里面寫上:
LIBRARY dllname.dll
EXPORTS
Add @1
Add @2
然后將這個文件添加到工程中,在link中設置 /dll, 然后編譯在debug或release中就可以找到dll和lib了
使用的時候加上dll.h文件。
===============================
補充一點:
dll是個編譯好的程序,調用時可以直接調用其中的函數,不參加工程的編譯。而lib應該說是一個程序集,只是把一些相應的函數總結在一起,如果調用lib中的函數,在工程編譯時,這些調用的函數都將參加編譯。
簡單講,靜態庫就是直接將需要的代碼連接進可執行程序;動態庫就是在需要調用其中的函數時,根據函數映射表找到該函數然后調入堆棧執行。
做成靜態庫可執行文件本身比較大,但不必附帶動態庫
做成動態庫可執行文件本身比較小,但需要附帶動態庫
其它沒有什么對于程序員而言很大的區別,有的Unix可能不支持動態庫,所以只好用靜態庫。
DLL與LIB的區別:
1.DLL是一個完整程序,其已經經過鏈接,即不存在同名引用,且有導出表,與導入表lib是一個代碼集(也叫函數集)他沒有鏈接,所以lib有冗余,當兩個lib相鏈接時地址會重新建立,當然還有其它相關的不同,用lib.exe就知道了;
2.在生成dll時,經常會生成一個.lib(導入與導出),這個lib實際上不是真正的函數集,其每一個導出導入函數都是跳轉指令,直接跳轉到DLL中的位置,這個目的是外面的程序調用dll時自動跳轉;
3.實際上最常用的lib是由lib.exe把*.obj生成的lib。
我們在用C/C++語言寫程序的時侯,內存管理的絕大部分工作都是需要我們來做的。實際上,內存管理是一個比較繁瑣的工作,無論你多高明,經驗多豐富,難免會在此處犯些小錯誤,而通常這些錯誤又是那么的淺顯而易于消除。但是手工“除蟲”(debug),往往是效率低下且讓人厭煩的,本文將就"段錯誤"這個內存訪問越界的錯誤談談如何快速定位這些"段錯誤"的語句。 下面將就以下的一個存在段錯誤的程序介紹幾種調試方法:
1 dummy_function (void)
2 {
3 unsigned char *ptr = 0x00;
4 *ptr = 0x00;
5 }
6
7 int main (void)
8 {
9 dummy_function ();
10
11 return 0;
12 }
|
作為一個熟練的C/C++程序員,以上代碼的bug應該是很清楚的,因為它嘗試操作地址為0的內存區域,而這個內存區域通常是不可訪問的禁區,當然就會出錯了。我們嘗試編譯運行它:
xiaosuo@gentux test $ ./a.out
段錯誤
|
果然不出所料,它出錯并退出了。 1.利用gdb逐步查找段錯誤:這種方法也是被大眾所熟知并廣泛采用的方法,首先我們需要一個帶有調試信息的可執行程序,所以我們加上“-g -rdynamic"的參數進行編譯,然后用gdb調試運行這個新編譯的程序,具體步驟如下:
xiaosuo@gentux test $ gcc -g -rdynamic d.c
xiaosuo@gentux test $ gdb ./a.out
GNU gdb 6.5
Copyright (C) 2006 Free Software Foundation, Inc.
GDB is free software, covered by the GNU General Public License, and you are
welcome to change it and/or distribute copies of it under certain conditions.
Type "show copying" to see the conditions.
There is absolutely no warranty for GDB. Type "show warranty" for details.
This GDB was configured as "i686-pc-linux-gnu"...Using host libthread_db library "/lib/libthread_db.so.1".
(gdb) r
Starting program: /home/xiaosuo/test/a.out
Program received signal SIGSEGV, Segmentation fault.
0x08048524 in dummy_function () at d.c:4
4 *ptr = 0x00;
(gdb)
|
哦?!好像不用一步步調試我們就找到了出錯位置d.c文件的第4行,其實就是如此的簡單。 從這里我們還發現進程是由于收到了SIGSEGV信號而結束的。通過進一步的查閱文檔(man 7 signal),我們知道SIGSEGV默認handler的動作是打印”段錯誤"的出錯信息,并產生Core文件,由此我們又產生了方法二。 2.分析Core文件:Core文件是什么呢?
| The default action of certain signals is to cause a process to terminate and produce a core dump file, a disk file containing an image of the process's memory at the time of termination. A list of the signals which cause a process to dump core can be found in signal(7). |
以上資料摘自man page(man 5 core)。不過奇怪了,我的系統上并沒有找到core文件。后來,憶起為了漸少系統上的拉圾文件的數量(本人有些潔癖,這也是我喜歡Gentoo的原因之一),禁止了core文件的生成,查看了以下果真如此,將系統的core文件的大小限制在512K大小,再試:
xiaosuo@gentux test $ ulimit -c
0
xiaosuo@gentux test $ ulimit -c 1000
xiaosuo@gentux test $ ulimit -c
1000
xiaosuo@gentux test $ ./a.out
段錯誤 (core dumped)
xiaosuo@gentux test $ ls
a.out core d.c f.c g.c pango.c test_iconv.c test_regex.c
|
core文件終于產生了,用gdb調試一下看看吧:
xiaosuo@gentux test $ gdb ./a.out core
GNU gdb 6.5
Copyright (C) 2006 Free Software Foundation, Inc.
GDB is free software, covered by the GNU General Public License, and you are
welcome to change it and/or distribute copies of it under certain conditions.
Type "show copying" to see the conditions.
There is absolutely no warranty for GDB. Type "show warranty" for details.
This GDB was configured as "i686-pc-linux-gnu"...Using host libthread_db library "/lib/libthread_db.so.1".
warning: Can't read pathname for load map: 輸入/輸出錯誤.
Reading symbols from /lib/libc.so.6...done.
Loaded symbols for /lib/libc.so.6
Reading symbols from /lib/ld-linux.so.2...done.
Loaded symbols for /lib/ld-linux.so.2
Core was generated by `./a.out'.
Program terminated with signal 11, Segmentation fault.
#0 0x08048524 in dummy_function () at d.c:4
4 *ptr = 0x00;
|
哇,好歷害,還是一步就定位到了錯誤所在地,佩服一下Linux/Unix系統的此類設計。 接著考慮下去,以前用windows系統下的ie的時侯,有時打開某些網頁,會出現“運行時錯誤”,這個時侯如果恰好你的機器上又裝有windows的編譯器的話,他會彈出來一個對話框,問你是否進行調試,如果你選擇是,編譯器將被打開,并進入調試狀態,開始調試。 Linux下如何做到這些呢?我的大腦飛速地旋轉著,有了,讓它在SIGSEGV的handler中調用gdb,于是第三個方法又誕生了: 3.段錯誤時啟動調試:
#include <stdio.h>
#include <stdlib.h>
#include <signal.h>
#include <string.h>
void dump(int signo)
{
char buf[1024];
char cmd[1024];
FILE *fh;
snprintf(buf, sizeof(buf), "/proc/%d/cmdline", getpid());
if(!(fh = fopen(buf, "r")))
exit(0);
if(!fgets(buf, sizeof(buf), fh))
exit(0);
fclose(fh);
if(buf[strlen(buf) - 1] == '\n')
buf[strlen(buf) - 1] = '\0';
snprintf(cmd, sizeof(cmd), "gdb %s %d", buf, getpid());
system(cmd);
exit(0);
}
void
dummy_function (void)
{
unsigned char *ptr = 0x00;
*ptr = 0x00;
}
int
main (void)
{
signal(SIGSEGV, &dump);
dummy_function ();
return 0;
}
|
編譯運行效果如下:
xiaosuo@gentux test $ gcc -g -rdynamic f.c
xiaosuo@gentux test $ ./a.out
GNU gdb 6.5
Copyright (C) 2006 Free Software Foundation, Inc.
GDB is free software, covered by the GNU General Public License, and you are
welcome to change it and/or distribute copies of it under certain conditions.
Type "show copying" to see the conditions.
There is absolutely no warranty for GDB. Type "show warranty" for details.
This GDB was configured as "i686-pc-linux-gnu"...Using host libthread_db library "/lib/libthread_db.so.1".
Attaching to program: /home/xiaosuo/test/a.out, process 9563
Reading symbols from /lib/libc.so.6...done.
Loaded symbols for /lib/libc.so.6
Reading symbols from /lib/ld-linux.so.2...done.
Loaded symbols for /lib/ld-linux.so.2
0xffffe410 in __kernel_vsyscall ()
(gdb) bt
#0 0xffffe410 in __kernel_vsyscall ()
#1 0xb7ee4b53 in waitpid () from /lib/libc.so.6
#2 0xb7e925c9 in strtold_l () from /lib/libc.so.6
#3 0x08048830 in dump (signo=11) at f.c:22
#4 <signal handler called>
#5 0x0804884c in dummy_function () at f.c:31
#6 0x08048886 in main () at f.c:38
|
怎么樣?是不是依舊很酷? 以上方法都是在系統上有gdb的前提下進行的,如果沒有呢?其實glibc為我們提供了此類能夠dump棧內容的函數簇,詳見/usr/include/execinfo.h(這些函數都沒有提供man page,難怪我們找不到),另外你也可以通過 gnu的手冊進行學習。 4.利用backtrace和objdump進行分析:重寫的代碼如下:
#include <execinfo.h>
#include <stdio.h>
#include <stdlib.h>
#include <signal.h>
/* A dummy function to make the backtrace more interesting. */
void
dummy_function (void)
{
unsigned char *ptr = 0x00;
*ptr = 0x00;
}
void dump(int signo)
{
void *array[10];
size_t size;
char **strings;
size_t i;
size = backtrace (array, 10);
strings = backtrace_symbols (array, size);
printf ("Obtained %zd stack frames.\n", size);
for (i = 0; i < size; i++)
printf ("%s\n", strings[i]);
free (strings);
exit(0);
}
int
main (void)
{
signal(SIGSEGV, &dump);
dummy_function ();
return 0;
}
|
編譯運行結果如下:
xiaosuo@gentux test $ gcc -g -rdynamic g.c
xiaosuo@gentux test $ ./a.out
Obtained 5 stack frames.
./a.out(dump+0x19) [0x80486c2]
[0xffffe420]
./a.out(main+0x35) [0x804876f]
/lib/libc.so.6(__libc_start_main+0xe6) [0xb7e02866]
./a.out [0x8048601]
|
這次你可能有些失望,似乎沒能給出足夠的信息來標示錯誤,不急,先看看能分析出來什么吧,用objdump反匯編程序,找到地址0x804876f對應的代碼位置:
xiaosuo@gentux test $ objdump -d a.out
|
8048765: e8 02 fe ff ff call 804856c <signal@plt>
804876a: e8 25 ff ff ff call 8048694 <dummy_function>
804876f: b8 00 00 00 00 mov $0x0,%eax
8048774: c9 leave
|
我們還是找到了在哪個函數(dummy_function)中出錯的,信息已然不是很完整,不過有總比沒有好的啊! 后記:本文給出了分析"段錯誤"的幾種方法,不要認為這是與孔乙己先生的"回"字四種寫法一樣的哦,因為每種方法都有其自身的適用范圍和適用環境,請酌情使用,或遵醫囑。
跟諸如Object Pascal和Ada等其它一些語言不同,C++語言并沒有內在地提供一種將類的方法作為回調函數使用的方案。在C語言中,這種回調函數被稱作算子(functor),在事件驅動類程序中普遍存在。主要問題基于這樣一個事實:某個類的多個實例各自位于內存的不同位置。這就需要在回調的時候不僅需要一個函數指針,同時也需要一個指針指向某個實例本身(譯者注:否則回調時便無法知道目前正在操作的是哪個對象,C++類的非靜態方法包含一個默認的“參數”:this指針,就是起這種作用的)。所以,針對問題的定義,有一個很直觀的解決方法就是使用模板和編譯時的實例化及特化。
解決方案
這里的方案只支持一個模板參數,但如果一些能夠如愿的話,隨著更多的編譯器完全實現C++標準,以后將會支持動態的模板參數,比如“…”形式的模板參數列表(參見《C++ Templates, The Complete Guide》),那時,我們就可以可以實現無需全部預定義的參數集合。(文中所有代碼的注釋為譯者加,下同。)
template < class Class, typename ReturnType, typename Parameter >
class SingularCallBack
{
public:
//指向類成員函數的指針,用他來實現回調函數。
typedef ReturnType (Class::*Method)(Parameter);
//構造函數
SingularCallBack(Class* _class_instance, Method _method)
{
class_instance = _class_instance;
method = _method;
};
//重載函數調用運算符()
ReturnType operator()(Parameter parameter)
{
return (class_instance->*method)(parameter);
};
//與上面的()等價的函數,引入這個函數的原因見下文
ReturnType execute(Parameter parameter)
{
return operator()(parameter);
};
private:
Class* class_instance;
Method method;
};
模板的使用
模板(template)的使用非常方便,模板本身可被實例化為一個對象指針(object pointer)或者一個簡單的類(class)。當作為對象指針使用時,C++有另外一個令人痛苦的限制:operator() 不可以在指針未被解引用的情況下調用,對于這個限制,一個簡便的但卻不怎么優雅的解決方法在一個模板內部增加一個execute方法(method),由這個方法從模板內部來調用operator()。除了這一點不爽之外,實例化SinglarCallBack為一個對象指針將可以使你擁有一個由回調組成的vector,或者任何其他類型的集合,這在事件驅動程序設計中是非常需要的。
假設以下兩個類已經存在,而且我們想讓methodB作為我們的回調方法,從代碼中我們可以看到當傳遞一個class A類的參數并調用methodB時,methodB會調用A類的output方法,如果你能在stdout上看到"I am class A :D",就說明回調成功了。
class A
{
public:
void output()
{
std::cout << "I am class A :D" << std::endl;
};
};
class B
{
public:
bool methodB(A a)
{
a.output();
return true;
}
};
有兩種方法可以從一個對象指針上調用一個回調方法,較原始的方法是解引用(dereference)一個對象指針并運行回調方法(即:operator()),第二個選擇是運行execute方法。
//第一種方法:
A a;
B b;
SingularCallBack< B,bool,A >* cb;
cb = new SingularCallBack< B,bool,A >(&b,&B::methodB);
if((*cb)(a))
{
std::cout << "CallBack Fired Successfully!" << std::endl;
}
else
{
std::cout << "CallBack Fired Unsuccessfully!" << std::endl;
}
//第二種方法:
A a;
B b;
SingularCallBack< B,bool,A >* cb;
cb = new SingularCallBack< B,bool,A >(&b,&B::methodB);
if(cb->execute(a))
{
std::cout << "CallBack Fired Successfully!" << std::endl;
}
else
{
std::cout << "CallBack Fired Unsuccessfully!" << std::endl;
}
下面的代碼示范了怎樣將一個模板實例化成一個普通的對象并使用之。
A a;
B b;
SingularCallBack< B,bool,A >cb(&b,&B::methodB);
{
std::cout << "CallBack Fired Successfully!" << std::endl;
}
else
{
std::cout << "CallBack Fired Unsuccessfully!" << std::endl;
}
更復雜的例子,一個回調模板可以像下面這樣使用:
class AClass
{
public:
AClass(unsigned int _id): id(_id){};
~AClass(){};
bool AMethod(std::string str)
{
std::cout << "AClass[" << id << "]: " << str << std::endl;
return true;
};
private:
unsigned int id;
};
typedef SingularCallBack < AClass, bool, std::string > ACallBack;
int main()
{
std::vector < ACallBack > callback_list;
AClass a1(1);
AClass a2(2);
AClass a3(3);
callback_list.push_back(ACallBack(&a1, &AClass::AMethod));
callback_list.push_back(ACallBack(&a2, &AClass::AMethod));
callback_list.push_back(ACallBack(&a3, &AClass::AMethod));
for (unsigned int i = 0; i < callback_list.size(); i++)
{
callback_list[i]("abc");
}
for (unsigned int i = 0; i < callback_list.size(); i++)
{
callback_list[i].execute("abc");
}
return true;
}
下面這個例子比上面的又復雜一些,你可以混合從同一個公共基類(base class)上繼承下來的不同的類到一個容器中,于是你就可以調用位于繼承樹的最底層的類的方法(most derived method)。(譯者注,C++的多態機制)
class BaseClass
{
public:
virtual ~BaseClass(){};
virtual bool DerivedMethod(std::string str){ return true; };
};
class AClass : public BaseClass
{
public:
AClass(unsigned int _id): id(_id){};
~AClass(){};
bool AMethod(std::string str)
{
std::cout << "AClass[" << id << "]: " << str << std::endl;
return true;
};
bool DerivedMethod(std::string str)
{
std::cout << "Derived Method AClass[" << id << "]: " << str << std::endl;
return true;
};
private:
unsigned int id;
};
class BClass : public BaseClass
{
public:
BClass(unsigned int _id): id(_id){};
~BClass(){};
bool BMethod(std::string str)
{
std::cout << "BClass[" << id << "]: " << str << std::endl;
return true;
};
bool DerivedMethod(std::string str)
{
std::cout << "Derived Method BClass[" << id << "]: " << str << std::endl;
return true;
};
private:
unsigned int id;
};
typedef SingularCallBack < BaseClass, bool, std::string > BaseCallBack;
int main()
{
std::vector < BaseCallBack > callback_list;
AClass a(1);
BClass b(2);
callback_list.push_back(BaseCallBack(&a, &BaseClass::DerivedMethod));
callback_list.push_back(BaseCallBack(&b, &BaseClass::DerivedMethod));
for (unsigned int i = 0; i < callback_list.size(); i++)
{
callback_list[i]("abc");
}
for (unsigned int i = 0; i < callback_list.size(); i++)
{
callback_list[i].execute("abc");
}
return true;
}
為簡捷起見,與實例的驗證(instance validation)相關的必要代碼沒有被包含進來,在實際的程序設計中,類實例的傳遞應該基于這樣的結構:使用類似智能指針(smart pointer)的包裝類。STL(標準模板庫)提供了兩個極好的選擇:aotu_ptr以及它的后繼:shared_ptr。Andrei Alexandrescu所著的《Modern C++ Design》一書也提供了一個面向策略設計(policy design oriented)的智能指針類。這三種方案中各有自己的優缺點,最終由用戶自己來決定究竟那一種最適合他們的需要。
一 拷貝構造函數是C++最基礎的概念之一,大家自認為對拷貝構造函數了解么?請大家先回答一下三個問題:
1. 以下函數哪個是拷貝構造函數,為什么?
- X::X(const X&);
- X::X(X);
- X::X(X&, int a=1);
- X::X(X&, int a=1, b=2);
2. 一個類中可以存在多于一個的拷貝構造函數嗎?
3. 寫出以下程序段的輸出結果, 并說明為什么? 如果你都能回答無誤的話,那么你已經對拷貝構造函數有了相當的了解。
- #include
- #include
-
- struct X {
- template<typename T>
- X( T& ) { std::cout << "This is ctor." << std::endl; }
-
- template<typename T>
- X& operator=( T& ) { std::cout << "This is ctor." << std::endl; }
- };
-
- void main() {
- X a(5);
- X b(10.5);
- X c = a;
- c = b;
- }
解答如下:
1. 對于一個類X,如果一個構造函數的第一個參數是下列之一:
a) X&
b) const X&
c) volatile X&
d) const volatile X&
且沒有其他參數或其他參數都有默認值,那么這個函數是拷貝構造函數.
- X::X(const X&);
- X::X(X&, int=1);
2.類中可以存在超過一個拷貝構造函數,
- class X {
- public:
- X(const X&);
- X(X&);
- };
注意,如果一個類中只存在一個參數為X&的拷貝構造函數,那么就不能使用const X或volatile X的對象實行拷貝初始化.
- class X {
- public:
- X();
- X(X&);
- };
-
- const X cx;
- X x = cx;
如果一個類中沒有定義拷貝構造函數,那么編譯器會自動產生一個默認的拷貝構造函數.
這個默認的參數可能為X::X(const X&)或X::X(X&),由編譯器根據上下文決定選擇哪一個.
默認拷貝構造函數的行為如下:
默認的拷貝構造函數執行的順序與其他用戶定義的構造函數相同,執行先父類后子類的構造.
拷貝構造函數對類中每一個數據成員執行成員拷貝(memberwise Copy)的動作.
a)如果數據成員為某一個類的實例,那么調用此類的拷貝構造函數.
b)如果數據成員是一個數組,對數組的每一個執行按位拷貝.
c)如果數據成員是一個數量,如int,double,那么調用系統內建的賦值運算符對其進行賦值.
3. 拷貝構造函數不能由成員函數模版生成.
- struct X {
- template<typename T>
- X( const T& );
-
- template<typename T>
- operator=( const T& );
- };
-
原因很簡單, 成員函數模版并不改變語言的規則,而語言的規則說,如果程序需要一個拷貝構造函數而你沒有聲明它,那么編譯器會為你自動生成一個. 所以成員函數模版并不會阻止編譯器生成拷貝構造函數, 賦值運算符重載也遵循同樣的規則.(參見Effective C++ 3edition, Item45)
二 針對上面作者的討論,理解更深了,但是下面我還是會給出一個一般的標準的實現和注意事項:
 #include "stdafx.h" #include "stdafx.h"
#include "stdio.h"
#include <iostream>
#include <string>
struct Test1
   { {
  Test1() { } Test1() { }
Test1(int i) { id = i; }
 Test1(const Test1& test) Test1(const Test1& test)
{
id = test.id;
 } }
Test1& operator = (const Test1& test)
{
if(this == &test)
return *this;
id = test.id;
return *this;
}
int id;
 }; };
class Test2
{
public:
Test2(){ m_pChar = NULL;}
Test2(char *pChar) { m_pChar = pChar;}
Test2(int num)
{
m_pChar = new char[num];
for(int i = 0; i< num; ++i)
m_pChar[i] = 'a';
m_pChar[num-1] = '\0';
}
Test2(const Test2& test)
{
char *pCharT = m_pChar;
m_pChar = new char[strlen(test.m_pChar)];
strcpy(m_pChar, test.m_pChar);
if(!pCharT)
delete []pCharT;
}
Test2& operator = (const Test2& test)
{
if(this == &test)
return *this;
char *pCharT = m_pChar;
m_pChar = new char[strlen(test.m_pChar)];
strcpy(m_pChar, test.m_pChar);
if(!pCharT)
delete []pCharT;
return *this;
}
private:
char *m_pChar;
};
int main(int argc, char* argv[])
{
const Test1 ts(1); // Test1()
const Test1* p_ts = &ts;
const Test1 ts2(ts); //Test(const Test1& test)
const Test1 ts3 = ts; //Test(const Test1& test)
Test1 ts4; ts4 = ts; //Test1& operator = (const Test1& test)
Test2 t(5);
Test2 t2(t);
Test2 t3 = t2;
Test2 t4; t4 = t;
return 0;
}
protobuf簡介
protobuf是google提供的一個開源序列化框架,類似于XML,JSON這樣的數據表示語言,其最大的特點是基于二進制,因此比傳統的XML表示高效短小得多。雖然是二進制數據格式,但并沒有因此變得復雜,開發人員通過按照一定的語法定義結構化的消息格式,然后送給命令行工具,工具將自動生成相關的類,可以支持java、c++、python等語言環境。通過將這些類包含在項目中,可以很輕松的調用相關方法來完成業務消息的序列化與反序列化工作。
protobuf在google中是一個比較核心的基礎庫,作為分布式運算涉及到大量的不同業務消息的傳遞,如何高效簡潔的表示、操作這些業務消息在google這樣的大規模應用中是至關重要的。而protobuf這樣的庫正好是在效率、數據大小、易用性之間取得了很好的平衡。
更多信息可參考官方文檔
例子介紹
先下載protobuf-2.3.0.zip源代碼庫,下載后解壓,選擇vsprojects目錄下的protobuf.sln解決方案打開,編譯整個方案順利成功。其中有一些測試工程,庫相關的工程是libprotobuf、libprotobuf-lite、libprotoc和protoc。其中protoc是命令行工具。在example目錄下有一個地址薄消息的例子,業務消息的定義文件后綴為.proto,其中的addressbook.proto內容為:
package tutorial;
option java_package = "com.example.tutorial";
option java_outer_classname = "AddressBookProtos";
message Person {
required string name = 1;
required int32 id = 2; // Unique ID number for this person.
optional string email = 3;
enum PhoneType {
MOBILE = 0;
HOME = 1;
WORK = 2;
}
message PhoneNumber {
required string number = 1;
optional PhoneType type = 2 [default = HOME];
}
repeated PhoneNumber phone = 4;
}
// Our address book file is just one of these.
message AddressBook {
repeated Person person = 1;
}
該定義文件,定義了地址薄消息的結構,頂層消息為AddressBook,其中包含多個Person消息,Person消息中又包含多個PhoneNumber消息。里面還定義了一個PhoneType的枚舉類型。
類型前面有required表示必須,optional表示可選,repeated表示重復,這些定義都是一目了然的,無須多說。關于消息定義的詳細語法可參考官方文檔。
現在用命令行工具來生成業務消息類,切換到protoc.exe所在的debug目錄,在命令行敲入:
protoc.exe --proto_path=..\..\examples --cpp_out=..\..\examples ..\..\examples\addressbook.proto
該命令中--proto_path參數表示.proto消息定義文件路徑,--cpp_out表示輸出c++類的路徑,后面接著是addressbook.proto消息定義文件。該命令會讀取addressbook.proto文件并生成對應的c++類頭文件和實現文件。執行完后在examples目錄生存了addressbook.pb.h和addressbook.pb.cpp。
現在新建兩個空控制臺工程,第一個不妨叫AddPerson,然后把examples目錄下的add_person.cc、addressbook.pb.h和addressbook.pb.cpp加入到該工程,另一個工程不妨叫ListPerson,將examples目錄下的list_people.cc、addressbook.pb.h和addressbook.pb.cpp加入到該工程,在兩個工程的項目屬性中附加頭文件路徑../src。兩個工程的項目依賴都選擇libprotobuf工程(庫)。
給AddPerson工程添加一個命令行參數比如叫addressbook.dat用于將地址薄信息序列化寫入該文件,然后編譯運行AddPerson工程,根據提示輸入地址薄信息:
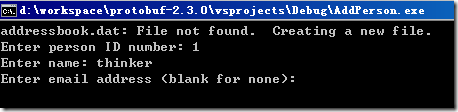
輸入完成后,將序列化到addressbook.dat文件中。
在ListPerson工程的命令行參數中加讀取文件參數..\AddPerson\addressbook.dat,然后在運行ListPerson工程,可在 list_people.cc的最后設個斷點,避免命令行窗口運行完后關閉看不到結果:
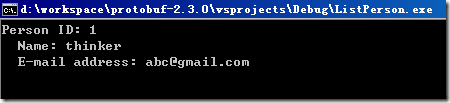
寫入地址薄的操作,關鍵操作就是調用address_book.SerializeToOstream進行序列化到文件流。
而讀取操作中就是address_book.ParseFromIstream從文件流反序列化,這都是框架自動生成的類中的方法。
其他操作都是業務消息的字段set/get之類的對象級操作,很明了。更詳細的API參考官方文檔有詳細說明。
在TCP網絡編程中的考慮
從上面的例子可以看出protobuf這樣的庫是很方便高效的,那么自然的想到在網絡編程中用來做業務消息的序列化、反序列化支持。在基于UDP協議的網絡應用中,由于UDP本身是有邊界,那么用protobuf來處理業務消息就很方便。但在TCP應用中,由于TCP協議沒有消息邊界,這就需要有一種機制來確定業務消息邊界。在TCP網絡編程中這是必須面對的問題。
注意上面的address_book.ParseFromIstream調用,如果流參數的內容多一個字節或者少一個字節,該方法都會返回失敗(雖然某些字段可能正確得到結果了),也就是說送給反序列化的數據參數除了格式正確還必須有正確的大小。因此在tcp網絡編程中,要反序列化業務消息,就要先知道業務數據的大小。而且在實際應用中可能在一個發送操作中,發送多個業務消息,而且每個業務消息的大小、類型都不一樣。而且可能發送很大的數據流,比如文件。
顯然消息邊界的確認問題和protobuf庫無關,還得自己搞定。在官方文檔中也提到,protobuf并不太適合來作大數據的處理,當業務消息超過1M時,就應該考慮是否應該用另外的替代方案。當然對于大數據,你也可以分割為多個小塊用protobuf做小塊消息封裝進行傳遞。但對很多應用這樣的作法顯得比較多余,比如發送一個大的文件,一般是在接收方從協議棧收到多少數據就寫多少數據到磁盤,這是一種邊接收邊處理的流模式,這種模式基本上和每次收到的數據量沒有關系。這種模式下再采用分割成小消息進行反序列化就顯得多此一舉了。
由于每個業務消息的大小和處理方式都可能不一樣,那么就需要獨立抽象出一個邊界消息來區分不同的業務消息,而且這個邊界消息的格式和大小必須固定。對于網絡編程熟手,可能早已經想到了這樣的消息,我們可以結合protobuf庫來定義一個邊界消息,不妨叫BoundMsg:
message BoundMsg
{
required int32 msg_type = 1;
required int32 msg_size = 2;
}
可以根據需要擴充一些字段,但最基本的這兩個字段就夠用了。我們只需要知道業務消息的類型和大小即可。這個消息大小是固定的8字節,專門用來確定數據流的邊界。有了這樣的邊界消息,在接收端處理任何業務消息就很靈活方便了,下面是接收端處理的簡單偽代碼示例:
if(net_read(buf,8))
{
boundMsg.ParseFromIstream(buf);
switch(boundMsg.msg_type)
{
case BO_1:
if(net_read(bo1Buf,boundMsg.msg_size))
{
bo1.ParseFromIstream(bo1Buf);
....
}
break;
case BO_2:
if(net_read(bo2Buf,boundMsg.msg_size))
{
bo2.ParseFromIstream(bo2Buf);
....
}
break;
case FILE_DATA:
count = 0;
while(count < boundMsg.msg_size)
{
piece_size = net_read(fileBuf,1024);
write_file(filename,fileBuf,piece_size);
count = count + piece_size;
}
break;
}
}
注意上面如果FILE_DATA消息后,還緊接其他業務消息的話,需要小心,即count累計出的值可能大于
boundMsg.msg_size的值,那么多出來的實際上應該是下一個邊界消息數據了。為了避免處理的復雜性,上面所有的循環網絡讀取操作(上面BO_1,BO_2都可能需要循環讀取,為了簡化沒有寫成循環)的緩沖區位置和大小參數應該動態調整,即每次讀取時傳遞的都是還期望讀取的數據大小,對于文件的話,可能特殊點,因為邊讀取邊寫入,就沒有必要事先要分配一個文件大小的緩沖區來存放數據了。對于文件分配一個小緩沖區來讀,注意確認下邊界即可。
上面是我的一點考慮,不妥之處還請大家討論交流。想想借助于ACE、MINA這樣的網絡編程框架,然后結合protobuf這樣的序列化框架,網絡編程中技術基礎設施層面的東西就給我們解決得差不多了,我們可以真正只關注于業務的實現。
摘要: 轉載自:Protocol Buffers Language Guide之proto文件類型格式分析[關鍵點翻譯] | 漂泊如風1、 定義一個消息類型:
message SearchRequest {
required string query = 1;
optional int32 page_number = 2;
optional int32 result_per_... 閱讀全文
轉載自:Protocol Buffers Language Guide之proto文件類型格式分析[關鍵點翻譯] | 漂泊如風
今天來介紹一下“Protocol Buffers”(以下簡稱protobuf)這個玩意兒。
★protobuf是啥玩意兒?
為了照顧從沒聽說過的同學,照例先來掃盲一把。
首先,protobuf是一個開源項目(官方站點在“這里 ”),而且是后臺很硬的開源項目。網上現有的大部分(至少80%)開源項目,要么是某人單干、要么是幾個閑雜人等合伙搞。而protobuf則不然,它是 鼎鼎大名的Google公司開發出來,并且在Google內部久經考驗的一個東東。由此可見,它的作者絕非一般閑雜人等可比。
那這個聽起來牛X的東東到底有啥用處捏?簡單地說,這個東東干的事兒其實和XML差不多,也就是把某種數據結構的信息,以某種格式保存起來。主要用于數據存儲、傳輸協議格式等 場合。有同學可能心理犯嘀咕了:放著好好的XML不用,干嘛重新發明輪子啊?!先別急,后面俺自然會有說道。
話說到了去年(大約是08年7 月),Google突然大發慈悲,把這個好東西貢獻給了開源社區。這下,像俺這種喜歡撿現成的家伙可就有福啦!貌似喜歡撿現成的家伙還蠻多滴,再加上 Google的號召力,開源后不到一年,protobuf的人氣就已經很旺了。所以俺為了與時俱進,就單獨開個帖子來忽悠一把。
★protobuf有啥特色?
掃盲完了之后,就該聊一下技術方面的話題了。由于這玩意兒發布的時間較短(未滿周歲),所以俺接觸的時間也不長。今天在此是先學現賣,列位看官多多包涵 
◇性能好/效率高
現在,俺就來說說Google公司為啥放著好端端的XML不用,非要另起爐灶,重新造輪子。一個根本的原因是XML性能不夠好。
先說時間開銷:XML格式化(序列化)的開銷倒還好;但是XML解析(反序列化)的開銷就不敢恭維啦。俺之前經常碰到一些時間性能很敏感的場合,由于不堪忍受XML解析的速度,棄之如敝履。
再來看空間開銷:熟悉XML語法的同學應該知道,XML格式為了有較好的可讀性,引入了一些冗余的文本信息。所以空間開銷也不是太好(不過這點缺點,俺不常碰到)。
由于Google公司賴以吹噓的就是它的海量數據和海量處理能力。對于幾十萬、上百萬機器的集群,動不動就是PB級的數據量,哪怕性能稍微提高0.1% 也是相當可觀滴。所以Google自然無法容忍XML在性能上的明顯缺點。再加上Google從來就不缺造輪子的牛人,所以protobuf也就應運而生 了。
Google對于性能的偏執,那可是出了名的。所以,俺對于Google搞出來protobuf是非常滴放心,性能上不敢說是最好,但肯定不會太差。
◇代碼生成機制
除了性能好,代碼生成機制是主要吸引俺的地方。為了說明這個代碼生成機制,俺舉個例子。
比如有個電子商務的系統(假設用C++實現),其中的模塊A需要發送大量的訂單信息給模塊B,通訊的方式使用socket。
假設訂單包括如下屬性:
--------------------------------
時間:time(用整數表示)
客戶id:userid(用整數表示)
交易金額:price(用浮點數表示)
交易的描述:desc(用字符串表示)
--------------------------------
如果使用protobuf實現,首先要寫一個proto文件(不妨叫Order.proto),在該文件中添加一個名為”Order”的message結構,用來描述通訊協議中的結構化數據。該文件的內容大致如下:
--------------------------------
message Order
{
required int32 time = 1;
required int32 userid = 2;
required float price = 3;
optional string desc = 4;
}
--------------------------------
然后,使用protobuf內置的編譯器編譯 該proto。由于本例子的模塊是C++,你可以通過protobuf編譯器的命令行參數(看“這里 ”),指定它生成C++語言的“訂單包裝類”。(一般來說,一個message結構會生成一個包裝類)
然后你使用類似下面的代碼來序列化/解析該訂單包裝類:
--------------------------------
// 發送方
Order order;
order.set_time(XXXX);
order.set_userid(123);
order.set_price(100.0f);
order.set_desc(“a test order”);
string sOrder;
order.SerailzeToString(&sOrder);
// 然后調用某種socket的通訊庫把序列化之后的字符串發送出去
// ……
--------------------------------
// 接收方
string sOrder;
// 先通過網絡通訊庫接收到數據,存放到某字符串sOrder
// ……
Order order;
if(order.ParseFromString(sOrder)) // 解析該字符串
{
cout << “userid:” << order.userid() << endl
<< “desc:” << order.desc() << endl;
}
else
{
cerr << “parse error!” << endl;
}
--------------------------------
有了這種代碼生成機制,開發人員再也不用吭哧吭哧地編寫那些協議解析的代碼了(干這種活是典型的吃力不討好)。
萬一將來需求發生變更,要求給訂單再增加一個“狀態”的屬性,那只需要在Order.proto文件中增加一行代碼。對于發送方(模塊A),只要增加一行設置狀態的代碼;對于接收方(模塊B)只要增加一行讀取狀態的代碼。哇塞,簡直太輕松了!
另外,如果通訊雙方使用不同的編程語言來實現,使用這種機制可以有效確保兩邊的模塊對于協議的處理是一致的。
順便跑題一下。
從某種意義上講,可以把proto文件看成是描述通訊協議的規格說明書(或者叫接口規范)。這種伎倆其實老早就有了,搞過微軟的COM編程或者接觸過CORBA的同學,應該都能從中看到IDL(詳細解釋看“這里 ”)的影子。它們的思想是相通滴。
◇支持“向后兼容”和“向前兼容”
還是拿剛才的例子來說事兒。為了敘述方便,俺把增加了“狀態”屬性的訂單協議成為“新版本”;之前的叫“老版本”。
所謂的“向后兼容”(backward compatible),就是說,當模塊B升級了之后,它能夠正確識別模塊A發出的老版本的協議。由于老版本沒有“狀態”這個屬性,在擴充協議時,可以考慮把“狀態”屬性設置成非必填 的,或者給“狀態”屬性設置一個缺省值(如何設置缺省值,參見“這里 ”)。
所謂的“向前兼容”(forward compatible),就是說,當模塊A升級了之后,模塊B能夠正常識別模塊A發出的新版本的協議。這時候,新增加的“狀態”屬性會被忽略。
“向后兼容”和“向前兼容”有啥用捏?俺舉個例子:當你維護一個很龐大的分布式系統時,由于你無法同時 升級所有 模塊,為了保證在升級過程中,整個系統能夠盡可能不受影響,就需要盡量保證通訊協議的“向后兼容”或“向前兼容”。
◇支持多種編程語言
俺開博以來點評的幾個開源項目(比如“Sqlite ”、“cURL ”),都是支持很多種 編程語言滴,這次的protobuf也不例外。在Google官方發布的源代碼中包含了C++、Java、Python三種語言(正好也是俺最常用的三種,真爽)。如果你平時用的就是這三種語言之一,那就好辦了。
假如你想把protobuf用于其它語言,咋辦捏?由于Google一呼百應的號召力,開源社區對protobuf響應踴躍,近期冒出很多其它編程語言 的版本(比如ActionScript、C#、Lisp、Erlang、Perl、PHP、Ruby等),有些語言還同時搞出了多個開源的項目。具體細節可以參見“這里 ”。
不過俺有義務提醒一下在座的各位同學。如果你考慮把protobuf用于上述這些語言,一定認真評估對應的開源庫。因為這些開源庫不是Google官方提供的、而且出來的時間還不長。所以,它們的質量、性能等方面可能還有欠缺。
★protobuf有啥缺陷?
前幾天剛剛在“光環效應 ”的帖子里強調了“要同時評估優點和缺點”。所以俺最后再來批判一下這玩意兒的缺點。
◇應用不夠廣
由于protobuf剛公布沒多久,相比XML而言,protobuf還屬于初出茅廬。因此,在知名度、應用廣度等方面都遠不如XML。由于這個原因,假如你設計的系統需要提供若干對外的接口給第三方系統調用,俺奉勸你暫時不要考慮protobuf格式。
◇二進制格式導致可讀性差
為了提高性能,protobuf采用了二進制格式進行編碼。這直接導致了可讀性差的問題(嚴格地說,是沒有可讀性)。雖然protobuf提供了TextFormat這個工具類(文檔在“這里 ”),但終究無法徹底解決此問題。
可讀性差的危害,俺再來舉個例子。比如通訊雙方如果出現問題,極易導致扯皮(都不承認自己有問題,都說是對方的錯)。俺對付扯皮的一個簡單方法就是直接 抓包并dump成log,能比較容易地看出錯誤在哪一方。但是protobuf的二進制格式,導致你抓包并直接dump出來的log難以看懂。
◇缺乏自描述
一般來說,XML是自描述的,而protobuf格式則不是。給你一段二進制格式的協議內容,如果不配合相應的proto文件,那簡直就像天書一般。
由于“缺乏自描述”,再加上“二進制格式導致可讀性差”。所以在配置文件方面,protobuf是肯定無法取代XML的地位滴。
|